
1. Pandas 패키지
- 데이터 분석을 위한 고수준의 자료구조, 분석 도구 제공
- 자료구조
- Series: 열이 1개인 데이터 구조
- DataFrame: 열이 2개 이상인 데이터 구조
2. Series
- Index와 Value 1개를 가지는 자료구조
series (데이터, index=None, dtype=None, copy=False)- 데이터: list, set, dict와 numpy.ndarray 가능
- index: 데이터를 가리키는 이름
- list · set · ndarray를 대입하면 0부터 시작하는 숫자 인덱스가 자동으로 생성
- dict를 설정하면 key가 인덱스
- index 옵션에 직접 인덱스 설정 가능
- dtype
- 데이터 1개의 자료형으로 설정 -> 그 자료형으로 생성
- 설정 없음 -> pandas가 추론
- copy: True -> 데이터 복제해서 생성 / False -> 참조를 가져와서 생성
- index와 values 속성
- index 속성 호출 : 인덱스를 numpy의 ndarray로 리턴
- values 속성 호출: 값들을 numpy의 ndarray로 리턴
* 딥러닝은 기본적으로 numpy의 ndarray로 수행하는데, 데이터가 pandas의 자료구조면 values 속성을 호출해서 numpy의 ndarray로 수행해야 함.
* pandas를 사용해야 하는 이유: 다양한 데이터를 불러올 수 있기 때문! pandas로 불러오고 numpy 배열로 바꿔줘야 한다.
- 하나의 데이터를 접근
- Series[index]
- numpy와 동일한 형태로 연산 수행하고 numpy의 함수 사용 가능
- numpy의 1차원 배열과 Series의 차이는 Index의 여부!!!
#시리즈를 생성
price = pd.Series([1000, 3000, 2000, 4000])
#시리즈를 출력 - 자동 생성된 인덱스 와 값이 출력
print(price)
#1이라는 인덱스를 가진 데이터를 조회
print(price[1])
#인덱스를 직접 설정
price.index = ["사탕", "과자", "음료수", "과일"]
print(price)
#인덱스가 사탕이라는 데이터를 조회: 1000
print(price["사탕"])| 0 1000 1 3000 2 2000 3 4000 dtype: int64 3000 사탕 1000 과자 3000 음료수 2000 과일 4000 dtype: int64 1000 |
파이썬을 쓰는 것은 숫자가 항상 0부터 시작하고, n-1까지인데
개발자가 아닌 경우 1부터 시작하고 마지막을 포함한다. (ex.R)
pandas는 데이터분석을 위한 패키지기 때문에 (1, n)으로 인식한다.
x = price["사탕":"음료수"] #사탕부터 음료수까지의 데이터의 참조를 가져온 것
#x의 데이터를 변경하면 원본인 price 의 데이터도 수정
x["사탕"] = 800
print(x)
print(price)
print("=============================================")
y = price[["사탕","음료수"]] #사탕과 음료수의 데이터를 복제해 온 것
#y의 데이터를 변경해도 원본인 price의 데이터를 변경되지 않는 것
y["사탕"] = 2000
print(y)
print(price)| 사탕 800 과자 3000 음료수 2000 dtype: int64 사탕 800 과자 3000 음료수 2000 과일 4000 dtype: int64 ============================================= 사탕 2000 음료수 2000 dtype: int64 사탕 800 과자 3000 음료수 2000 과일 4000 dtype: int64 |
- x는 참조를 가져와서 쓴 것. 따라서 x의 데이터를 변경하면 원본인 price의 데이터도 변경된다.
- y는 데이터를 복제함. y의 데이터를 변경해도 원본인 price의 데이터는 변경되지 않았다.
배열은 데이터의 연속적인 모임이다. array는 연속이 전제된다.
물리적으로 연속되면 array list (혹은 dense list)라고 하고, 논리적으로 연속되면 linked list라고 한다.
대괄호를 쓴 건 복제를 하겠다는 뜻
- Series와 Series의 연산은 인덱스를 기준
- 동일한 인덱스가 없으면 연산을 수행하지 못한다.
s1 = pd.Series([100, 200, 300, np.nan], index=["사과", "배", "한라봉", "천혜향"])
print(s1)
s2 = pd.Series([100, 200, 300, 500], index=["사과", "한라봉", "천혜향", "무화과"])
print(s2)
print(s1 + s2)| 사과 100.0 배 200.0 한라봉 300.0 천혜향 NaN dtype: float64 사과 100 한라봉 200 천혜향 300 무화과 500 dtype: int64 무화과 NaN 배 NaN 사과 200.0 천혜향 NaN 한라봉 500.0 dtype: float64 |
- 시리즈는 인덱스를 일치하는 데이터끼리 연산을 수행
- 한쪽에만 존재하거나 np.nan인 데이터가 있으면 결과가 np.nan
- None은 데이터가 없다는 뜻이고, np.nan은 숫자로 볼 수 없다는 뜻.
3. DataFrame
- 인덱스를 가진 테이블 형태의 자료구조
- 관계형 데이터베이스의 테이블과 유사하지만 인덱스를 직접 설정할 수 있다는 것이 다르다.
- dict를 이용해서 주로 생성.
- dict의 키가 컬럼(열)의 이름이 되고 값이 셀 값이 된다.
- head(n), tail(n)로 앞 또는 뒤에서 n 개의 데이터를 추출할 수 있다.
- 기본적으로 5개를 가져온다.
- 데이터를 제대로 가져왔는지 확인할 때 많이 사용한다.
- idex: DataFrame의 index를 리턴하고 설정할 수 있는 속성
- 0부터 연속되는 숫자로 인덱스가 생성. index 속성으로 인덱스 직접 설정 가능
- columns: 컬럼의 이름을 리턴하고 이름을 수정할 수 있는 속성
- columns = [리스트] 하면 컬럼의 이름을 직접 설정하는 것도 가능
- values: DataFrame의 데이터를 2차원 ndarray로 리턴
- info()는 데이터프레임의 개요를 리턴
#DataFrame 생성
source = {
"code":[1, 2, 3, 4],
"name":["카리나", "지젤", np.nan, "윈터"],
"age": [23, 22, 34, 21]
}
df = pd.DataFrame(source)
print(df)
print(df.head(2)) #앞에서 2개
print(df.tail(2)) #뒤에서 2개
df.info()| code name age 0 1 카리나 23 1 2 지젤 22 2 3 NaN 34 3 4 윈터 21 code name age 0 1 카리나 23 1 2 지젤 22 code name age 2 3 NaN 34 3 4 윈터 21 <class 'pandas.core.frame.DataFrame'> RangeIndex: 4 entries, 0 to 3 Data columns (total 3 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 code 4 non-null int64 1 name 3 non-null object 2 age 4 non-null int64 dtypes: int64(2), object(1) memory usage: 224.0+ bytes |
4. Pandas를 이용한 데이터 수집
1) 클립보드의 내용 읽어오기
pandas.read_clipboard()
2) 자주 사용하는 데이터셋
scikit-learn
https://scikit-learn.org/stable/datasets/toy_dataset.html
load_digits(): 숫자 데이터 셋 - 분류에 사용
load_iris(): 붓꽃 데이터 - 분류에 사용
load_diabetes(): 당뇨병 데이터 - 회귀에 사용
load_linnerud(): 체력 검사 데이터 - 회귀에 사용
load_wine(): 와인 품질 데이터 - 분류에 사용
load_breast_cancer(): 유방암 데이터 - 분류에 사용
UCI 머신러닝 데이터 저장소: https://archive.ics.uci.edu/ml/index.php
kaggle: https://www.kaggle.com
데이콘: https://dacon.io/
#사이킷런(scikit-learn)에서 제공하는 데이터를 사용
from sklearn import datasets
#iris 데이터 읽어오기
iris = datasets.load_iris()
#print(iris)
#데이터프레임이 아니고 Bunch 클래스의 인스턴스
print(type(iris))- type은 <class 'sklearn.utils._bunch.Bunch'>
- 데이터프레임이 아니라 Bunch 클래스의 인스턴스임
키 확인
print(iris.keys())dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
- data가 피처, target이 레이블
- 레이블은 target, 목표값이다.
- 어떤 target을 찾을 수 있는 열을 feature라고 한다.
데이터 확인
print(iris.data)[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
....
- type은 ndarray
5. 텍스트 파일의 데이터 읽기
1) fwf 파일 읽기
2017-04-10다음32000
2017-04-11다음34000
2017-04-12다음33000
- 일정한 간격을 가지고 컬럼을 구분하는 텍스트파일
- 텍스트 파일은 포맷과 인코딩 방식 확인
인코딩 방식: utf-8, euc-kr, cp949(윈도우 한글 기본 포맷)
pandas.read_fwf('파일 경로', widths = (글자 사이의 간격), names = (컬럼 이름나열), encoding = 인코딩 방식)
#fwf 파일 읽기
df = pd.read_fwf('C:\\Users\\USER\\Downloads\\data\\data\\data_fwf.txt',
widths=(10, 2, 5),
names = ('날짜', '이름', '가격'),
encoding = 'utf-8')
print(df)- 윈도우에서 파일의경로를 설정할 때 역슬래시는 두번씩 입력
| 날짜 이름 가격 0 2017-04-10 다음 32000 1 2017-04-11 다음 34000 2 2017-04-12 다음 33000 |
2) csv 파일 읽기
- csv: 구분 기호로 분리된 텍스트 파일
- pandas.read_csv: 기본 구분자가 쉼표(,)
- pandas.read_table: 기본 구분자가 탭
- 첫번째 매개변수로 파일 경로 설정
- 아무런 옵션이 없으면 첫 번째 줄 데이터를 컬럼 이름으로 사용
#item.csv 파일 읽기
item = pd.read_csv('C:\\Users\\USER\\Downloads\\data\\data\\item.csv')
print(item)
print(item.info())| code manufacture name price 0 1 korea apple 1500 1 2 korea watermelon 15000 2 3 korea oriental melon 1000 3 4 philippines banana 500 4 5 korea lemon 1500 5 6 korea mango 700 <class 'pandas.core.frame.DataFrame'> RangeIndex: 6 entries, 0 to 5 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 code 6 non-null int64 1 manufacture 6 non-null object 2 name 6 non-null object 3 price 6 non-null int64 dtypes: int64(2), object(2) memory usage: 324.0+ bytes None |
옵션
- path: 데이터의 경로
- sep, delimiter: 구분자 설정. 기본은 ,
- header: 컬럼이름의 행번호 설정. 기본은 0, 없을 때는 None을 설정
- index_col: 인덱스로 사용할 컬럼 번호나 컬럼 이름 설정
- names: 컬럼 이름으로 사용할 list를 설정할 수 있는데 header=None일 때만 사용
- skiprows: 읽지 않을 행의 개수
- nrows: 읽을 행의 개수
- skip_footer: 무시할 마지막 행 개수
- endocing
- thousands: 천 단위 구분 기호. 설정하지 않으면 문자로 인식함
- na_values: NA 값으로 처리할 문자의 list
- parse_dates: 날짜 텍스트를 문자열이 아닌 날짜로 인식하게 하는 설정. 기본은 False라서 문자열로 인식
* csv 파일을 읽을 때는 먼저 파일을 열어서 첫번째 행이 컬럼의 이름인지, 한글이 포함되어있는지, 구분기호가 뭔지 확인
#item.csv 파일 읽기
good = pd.read_csv('C:\\Users\\USER\\Downloads\\data\\data\\good.csv')
print(good)| apple 10 1500 0 banana 5 15000 1 melon 7 1000 2 kiwi 20 500 3 mango 30 1500 4 orange 4 700 |
- 첫번째 행이 컬럼 이름이 되어버렸다.
- 첫번째 행을 컬럼 이름이 아니고 데이터로 만들기
#item.csv 파일 읽기
good = pd.read_csv('C:\\Users\\USER\\Downloads\\data\\data\\good.csv',
header=None, names=['제품이름', '수량', '가격'])
print(good)
| 제품이름 수량 가격 0 apple 10 1500 1 banana 5 15000 2 melon 7 1000 3 kiwi 20 500 4 mango 30 1500 5 orange 4 700 |
- 데이터 양이 아주 많은 경우에 한 번에 읽으려고 하면 실패
- nrows 속성을 이용해서 시작 위치에서 일부분의 데이터만 읽어오고 skiprows를 이용해서 읽을 수 있음
#item.csv 파일 읽기
parser = pd.read_csv('C:\\Users\\USER\\Downloads\\data\\data\\good.csv',
header=None, nrows=2, skiprows=4)
print(parser)| 0 1 2 0 mango 30 1500 1 orange 4 700 |
- 반복문을 사용하면
#item.csv 파일 읽기
for i in range(0, 3):
parser = pd.read_csv('C:\\Users\\USER\\Downloads\\data\\data\\good.csv',
header=None, nrows=2, skiprows=i*2)
print(parser)| 0 1 2 0 apple 10 1500 1 banana 5 15000 0 1 2 0 melon 7 1000 1 kiwi 20 500 0 1 2 0 mango 30 1500 1 orange 4 700 |
- 데이터 갯수가 몇개인지 모르면 while문
i = 0
while True:
try:
parser = pd.read_csv('C:\\Users\\USER\\Downloads\\data\\data\\good.csv',
header=None, nrows=2, skiprows=i*2)
print(parser)
i = i + 1
except:
break- chunksize를 설정해서 한 번에 읽을 데이터의 개수를 설정하고 이때 리턴되는 TextParser 객체를 순회하면서 읽을 수 있음
parser = pd.read_csv('C:\\Users\\USER\\Downloads\\data\\data\\good.csv',
header=None, chunksize=2)
for piece in parser:
print(piece)
- 탭으로 구분된 파일 읽기
ParserError: Error tokenizing data. C error: Expected 1 fields in line 326, saw 2- 탭으로 구분돼있음을 확인
gapminder = pd.read_csv('C:\\Users\\USER\\Downloads\\data\\data\\gapminder.tsv',
sep = 'Wt')
print(gapminder.head())| country continent year lifeExp pop gdpPercap 0 Afghanistan Asia 1952 28.801 8425333 779.445314 1 Afghanistan Asia 1957 30.332 9240934 820.853030 2 Afghanistan Asia 1962 31.997 10267083 853.100710 3 Afghanistan Asia 1967 34.020 11537966 836.197138 4 Afghanistan Asia 1972 36.088 13079460 739.981106 |
csv로 저장
- Series나 DataFrame의 to_csv 메소드 호출
- 첫 번째 매개변수로 파일 경로 설정
- 기본적으로는 index와 컬럼 이름이 저장되는데 index와 header에 False 설정하면 출력되지 않음
- sep: 구분자 설정
- na_rep: NaN 값을 원하는 형식으로 설정
- cols: 컬럼 이름을 list로 설정하면 설정한 컬럼만 파일에 저장
data.to_csv('test.csv', index=False)
3) 엑셀 파일 읽기
pandas.io.excel.read_excel("파일 경로")- read_csv와 유사한데 sep는 없음
- sheet_name: 시트 선택해서 불러오기
- xlrd 패키지 설치
pip install xlrd* anaconda는 패키지가 내장되어있음
- DataFrame으로 만들기
df = pd.read_excel('C:\\Users\\USER\\Downloads\\2023-2 FOLLOW 순모임 출석체크.xlsx')
df
엑셀 파일 저장
- openpyxl 패키지 설치
*아나콘다는 내장
- 엑셀파일 경로를 갖는 라이터변수
!pip install xlsxwriter
writer = pandas.ExcelWriter("엑셀파일 경로", engine="xlsxwriter")
df.to_excel(writer, sheet_name='시트이름')
writer.close()- 저장했지만 여전히 쥬피터가 df를 쓰고 있기 때문에 작업이 완전히 끝난 후에 자유롭게 쓸 수 있음!
6. Web의 데이터 읽기
1) HTML에 있는 table 태그의 모든 가져오기
- pandas.read_html('파일의 경로나 URL')을 이용하면 table 태그의 내용을 DF로 만들어서 list 리턴
- 옵션으로 천단위 구분 기호 설정, 인코딩 방식, na 데이터 설정 등
https://ko.wikipedia.org/wiki/인구순_나라_목록
https://ko.wikipedia.org/wiki/%EC%9D%B8%EA%B5%AC%EC%88%9C_%EB%82%98%EB%9D%BC_%EB%AA%A9%EB%A1%9D
- URL에는 한글을 직접 사용하지 않고 인코딩된 URL을 사용해야 함
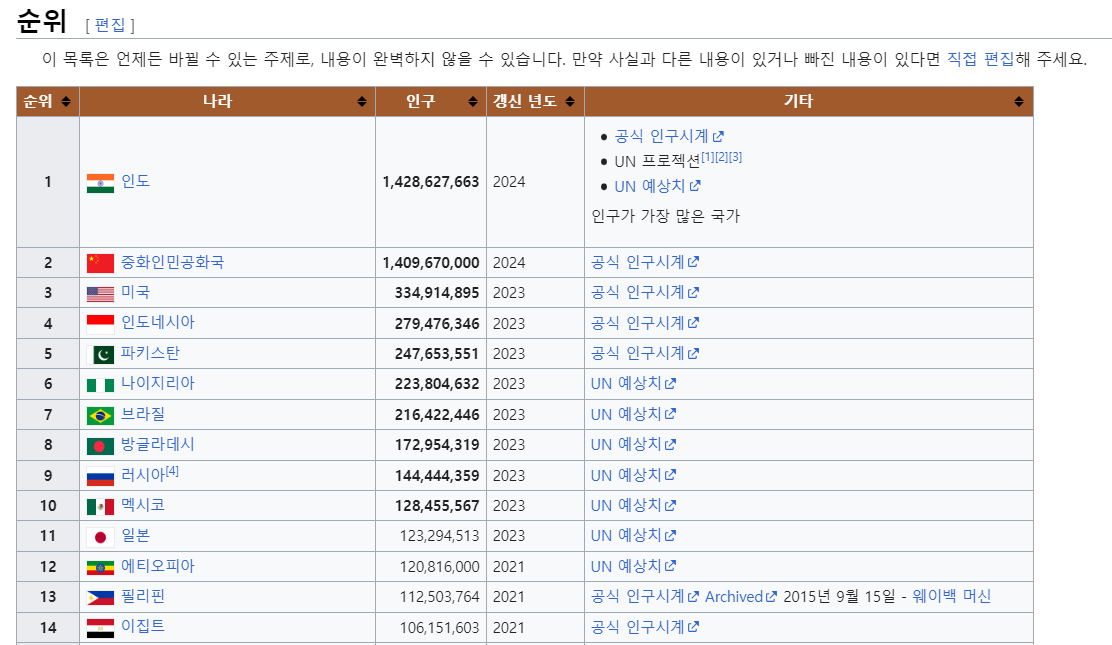
li = pd.read_html('https://ko.wikipedia.org/wiki/%EC%9D%B8%EA%B5%AC%EC%88%9C_%EB%82%98%EB%9D%BC_%EB%AA%A9%EB%A1%9D')
print(li[0])- 인덱스를 이용해 원하는 테이블을 선택해야 함
| 순위 나라 인구 갱신 년도 \ 0 1 인도 1428627663 2024.0 1 2 중화인민공화국 1409670000 2024.0 2 3 미국 334914895 2023.0 3 4 인도네시아 279476346 2023.0 4 5 파키스탄 247653551 2023.0 .. ... ... ... ... 236 237 토켈라우 1893 2023.0 237 238 니우에 1681 2022.0 238 239 바티칸 시국 764 2023.0 239 240 코코스 제도 593 2021.0 240 241 핏케언 제도 47 2021.0 기타 0 공식 인구시계 UN 프로젝션[1][2][3] UN 예상치 인구가 가장 많은 국가 1 공식 인구시계 2 공식 인구시계 3 공식 인구시계 4 공식 인구시계 .. ... 236 UN 예상치 237 공식 추계치 238 바티칸 시국 인구통계 인구가 가장 적은 UN 가입국 239 공식 추계치 240 인구가 가장 적은 속령 [241 rows x 5 columns] |
2) 웹에서 데이터 활용
- 웹에서 데이터 가져오기
- 데이터를 파싱 (데이터를 해석해서 원하는 데이터를 추출)
- 웹에서 제공되는 텍스트 데이터 종류
XML
- 데이터를 태그 형식으로 표현하는데 해석은 사용자가 함
<Persons>
<Person>
<name>귀도반로썸</name>
<language>파이썬</language>
</Person>
<Person>
<name>제임스 고슬링</name>
<language>자바</language>
</Persons>
JSON
- 자바스크립트의 객체 표현법으로 데이터를 표현하는 방식
- 최근의 API에서는 대부분 JSON만 지원
{"persons" : [{"name" : "하일스베르", "language" : "C#"}, {"name" : "데니스 리치히", "language" : "C"}]}
YAML (yml, 야믈)
- 가장 최근에 등장한 포맷으로 이메일 형식으로 데이터 표현하는 방식
- 클라우드 환경에서 설정 파일의 대부분은 YAML
persons:
person:
name:하일스베르
language: typescript
person:
name: 래리앨리슨
language: 오라클
HTML
- 웹 브라우저가 해석해서 화면에 랜더링하기 위한 포맷
- 구조적이지 않아서 데이터를 표현하는 데는 사용하기 어려움
- API를 제공하지 않는 사이트에서 화면에 보여지는 데이터를 추출하기 위해 다운로드 받아서 사용
3) 웹에서 데이터 가져오기
- urllib와 urllib2라는 파이썬 내장 모듈을 이용해서 웹의 데이터를 가져올 수 있음
- 내장 모듈의 request 객체의 urlopen이라는 메소드에 url을 문자열로 대입하면 url에 해당하는 데이터를 response 타입의 객체로 리턴
- response객체의 getheaders()를 이용하면 제공하는 데이터의 정보를 읽을 수 있고 read()를 호출하면 내용을 읽을 수 있다.
- read().decode("인코딩정보"): 읽온 내용이 한글이 포함되어 있다면 인코딩 설정
import urllib.request
from urllib.parse import quote
keyword = quote("네이버")
result = urllib.request.urlopen("https://search.hani.co.kr/search?searchword="+ keyword)
print(result.read())
- URL 한글 인코딩
- 문자열을 인코딩하고자 하면 urllib.parse 모듈의 quote_plus와 qoute 함수 이용
- 두 함수의 차이는 공백을 +로 처리하느냐 %20으로 처리하느냐의 차이
- 한겨례 신문사에서 '네이버' 검색 결과 가져오기
https://search.hani.co.kr/search?searchword=%EB%84%A4%EC%9D%B4%EB%B2%84
- https://search.hani.co.kr/search?searchword=검색어
- 한글을 치면 인코딩 에러가 나기 때문에 변수 keyword
import urllib.request
from urllib.parse import quote
keyword = quote("네이버")
result = urllib.request.urlopen("https://search.hani.co.kr/search?searchword="+ keyword)
print(result.read())
- requests 패키지를 활용한 웹의 데이터 가져오기
- GET, POST, PUT, DELETE 요청을 사용할 수 있고 데이터 인코딩이 편리한 패키지
- 파라미터로 넘겨줄 데이터를 dict로 만들어서 GET이나 POST 등에서 사용하면 인코딩을 자동으로 수행
requests.get("url")- 웹 페이지의 결과를 Response 객체를 리턴
- Response.txt를 이용하면 문자열을 가져올 수 있고
- content 속성을 호출하면 bytes를 리턴
pip install requests
import requests
resp = requests.get("http://httpbin.org/get")
print(resp.text)| { "args": {}, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate, br", "Host": "httpbin.org", "User-Agent": "python-requests/2.31.0", "X-Amzn-Trace-Id": "Root=1-65c46116-58a3d4551f99f24768fa4fe0" }, "origin": "118.131.111.158", "url": "http://httpbin.org/get" } |
#파라미터 만들기
param = {"id":"itstudy", "name":"군계", "age":53}
resp = requests.post('http://httpbin.org/post', data=param)
print(resp.text)| { "args": {}, "data": "", "files": {}, "form": { "age": "53", "id": "itstudy", "name": "\uad70\uacc4" }, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate, br", "Content-Length": "41", "Content-Type": "application/x-www-form-urlencoded", "Host": "httpbin.org", "User-Agent": "python-requests/2.31.0", "X-Amzn-Trace-Id": "Root=1-65c4619a-6cea70d6665e833a7d02a84f" }, "json": null, "origin": "118.131.111.158", "url": "http://httpbin.org/post" } |
- 이미지 파일 다운로드
#이미지 파일 다운로드
imageurl = "https://search.pstatic.net/common/?src=http%3A%2F%2Fblogfiles.naver.net%2FMjAyMTA1MTVfMjg1%2FMDAxNjIxMDA0ODI5MDc0.Q17_bqOFXmCDBx4kAr_UQl3vGPfvY4wNAS48RCfwja8g.UM29jj3Mra_yEHXChamjsDevclJMy13NgQRRzEbWyPAg.JPEG.gody97%2Fresized%25A3%25DFoutput%25A3%25DF1906874251.jpg&type=sc960_832"
filename ="redpanda.jpg"
try:
#다운로드
resp = requests.get(imageurl)
#파일에 저장
with open(filename, "wb") as h:
#다운로드 받은 내용을 bytes로 리턴
img = resp.content
h.write(img)
except Exception as e:
print(e)
4) json 데이터 파싱
방법
- requests를 이용해서 다운로드 받은 후 직접 파싱 - 옵션이 많을 때 좋음
- pandas.read_json을 이용해서 자동으로 파싱 - 데이터의 구조가 단순할 때 좋음
pandas.read_json을 이용해서 파싱
df = pd.read_json("http://swiftapi.rubypaper.co.kr:2029/hoppin/movies?version=1&page=1&count=30&genreId=&order=releasedateasc")
hoppin = df["hoppin"]
print(hoppin)| movies {'movie': [{'genreNames': '코미디,드라마', 'genreIds... totalCount 4266 Name: hoppin, dtype: object |
.
movies = hoppin['movies']
print(movies)
movie = movies['movie']
print(movie)
.
for item in movie:
print(item["title"] + ":" + item["ratingAverage"])| 인포먼트:6.7 엣지 오브 다크니스:6.9 베이비 돌:6 황야의 역마차:6.3 전원 교향곡:8 아버지의 깃발:8 여덟번의감정:6 레드:8.7 영광의 탈출:6.8 크로싱:8.8 맨 인 블랙:8.9 차형사:8.4 에이지 오브 드래곤:3.9 로드 오브 워리어:7.4 [메이킹 다큐] 도둑들 영화를 만들다!:7.9 괜찮아요 수달씨:7.5 파파:9 이케맨 뱅크:6.7 다중인격소녀 ISOLA:5.7 위조지폐:6.5 카인과 아벨:6.9 돌핀 블루:8.2 더 코드:7.6 철권 블러드 벤전스:8 블루 엘리펀트 (우리말 더빙):8.8 해결사 (2010):8.3 하나오니 2: 사랑의 시작:8.5 하나오니 3: 복수의 시간:8.5 아테나 전쟁의 여신 극장판:7.7 아이스 프린세스:8.8 |
- 파이썬의 기본 모듈을 이용해서 json 파싱
- jsonloads("문자열")
- json 문자열을 파싱해서 파이썬 dict나 list 생성
- { 로 시작하면 dict
- [ 로 시작하면 list
5) 카카오 검색 API 데이터를 가져와서 MySQL에 저장
2024.03.15 - [Python/Python 실전편] - [Python] Pandas 실습 _ 카카오 검색 API 데이터 가져오기
[Python] Pandas 실습 _ 카카오 검색 API 데이터 가져오기
- 카카오 검색 API developers.kakao.com - 애플리케이션 생성 후 REST API 키 복사 a89507c93f15074167c0700239d4b1d0 블로그 검색 메서드URL인증 방식 GET https://dapi.kakao.com/v2/search/blog REST API 키 헤더 Authorization Authoriz
yachae4910.tistory.com
6) XML 파싱

- 사용할 URL: https://www.hankyung.com/feed/it
- 파싱 방법:
import xml.etree.ElementTree as et
# urllib.request를 이용해서 읽어온 데이터: res
#메모리에 펼치기
tree = et.parse(res)
#루트 찾기
xroot = tree.getroot()
#특정 태그의 데이터 가져오기
items = xroot.findall('태그')
#태그는 여러개 나올 수 있으므로 반복문 수행
for node in items:
node.find(태그).text : 태그 안의 데이터import urllib.request
url = "https://www.chosun.com/arc/outboundfeeds/rss/category/economy/?outputType=xml"
request = urllib.request.Request(url)
response = urllib.request.urlopen(request)
#xml 파싱
import xml.etree.ElementTree as et
#메모리에 트리 형태로 펴맃기
tree = et.parse(response)
print(tree)
7) HTML 파싱
# BeautifulSoup 패키지 이용
!pip install beautifulsoup4* 아나콘다에는 내장
- 모듈을 import 할 때는 bs4를 import
# 메모리에 펼치기
bs4.BeautifuleSoup(파싱할 html, "html.parser")
# 태그 안의 데이터 찾기
bs.태그이름 나열.get_text*별로 쓰지 않음.
import requests
import bs4
resp = requests.get("http://finance.daum.net/")
html = resp.text
print(html)</html lang="ko"> |
...
#html 파싱
bs = bs4.BeautifulSoup(html, 'html.parser')
#html에서 body 태그 안의 span 태그의 텍스트 가져오기
print(bs.body.span.get_text())금융
- find 함수
find(태그, attributes, recursive, text, limit, keywords)- 태그: 찾고자 하는 태그를 설정
- attributes: 태그 중에서 특정 속성의 값만 가져올 때 사용
- recursive: False면 최상위 태그에서만 찾고, True면 하위로 들어가면서도 찾음
- 일치하는 태그 1개를 찾아온다.
- 일치하는 태그 여러개를 찾으려면 find_all 사용
- select 함수
선택자를 이용해서 찾아오는 함수
- bs4.element.Tag
- find와 select의 결과는 Tag 클래스의 list
- Tag 클래스에서 getText()를 호출하면 태그가 감싸고 있는 텍스트를 가져올 수 있고
- get('속성이름')은 속성의 값을 가져올 수 있다.
선택자는 앞에서부터 생략도 가능
https://news.naver.com/section/105
import requests
import bs4
resp = requests.get("https://search.hankyung.com/search/total?query=%ED%94%8C%EB%9E%AB%ED%8F%BC")
html = resp.text
# print(html)
#html 파싱
bs = bs4.BeautifulSoup(html, 'html.parser')
tags = bs.select('div > a')
#html에서 body 태그 안의 span 태그의 텍스트 가져오기
for tag in tags:
print(tag.getText())
print(tag.get('href'))
print()| 개발자 10명 중 8명 "생성형 AI, 개발 대체할 것" [Geeks' Briefing] https://www.hankyung.com/article/202402084600i https://www.hankyung.com/article/2024020844441 '공정위 혼자 왜이리 급하냐'…국회도 혀 찬 플랫폼법 독주 https://www.hankyung.com/article/2024020844441 https://www.hankyung.com/article/202402083905i |

'Python' 카테고리의 다른 글
| [Python] 크롤링 - Selenium (0) | 2024.02.14 |
|---|---|
| [Python] 크롤링 - 기사 스크래핑 (0) | 2024.02.14 |
| [Python] Numpy (0) | 2024.02.06 |
| Day10. REST API (0) | 2024.01.26 |
| Day9. 웹 서버 만들기 (1) | 2024.01.24 |