
데이터 url
red: http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv
white: http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-
white.csv
- 구분자: ;
- 피처
fixed acidity
volatile acidity
citric acid
residual sugar
chlorides
free sulfur dioxide
total sulfur dioxide
density
pH
sulphates
alcohol
quality
1. 데이터 가져오기
import pandas as pd
red = pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv',
sep=";")
red.info()| <class 'pandas.core.frame.DataFrame'> RangeIndex: 1599 entries, 0 to 1598 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 fixed acidity 1599 non-null float64 1 volatile acidity 1599 non-null float64 2 citric acid 1599 non-null float64 3 residual sugar 1599 non-null float64 4 chlorides 1599 non-null float64 5 free sulfur dioxide 1599 non-null float64 6 total sulfur dioxide 1599 non-null float64 7 density 1599 non-null float64 8 pH 1599 non-null float64 9 sulphates 1599 non-null float64 10 alcohol 1599 non-null float64 11 quality 1599 non-null int64 dtypes: float64(11), int64(1) memory usage: 150.0 KB |
white = pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv',
sep=";")
white.info()| <class 'pandas.core.frame.DataFrame'> RangeIndex: 4898 entries, 0 to 4897 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 fixed acidity 4898 non-null float64 1 volatile acidity 4898 non-null float64 2 citric acid 4898 non-null float64 3 residual sugar 4898 non-null float64 4 chlorides 4898 non-null float64 5 free sulfur dioxide 4898 non-null float64 6 total sulfur dioxide 4898 non-null float64 7 density 4898 non-null float64 8 pH 4898 non-null float64 9 sulphates 4898 non-null float64 10 alcohol 4898 non-null float64 11 quality 4898 non-null int64 dtypes: float64(11), int64(1) memory usage: 459.3 KB |
2. 기술통계량 확인
wine.describe()  |
3. 정규화
- 데이터의 값을 0 ~ 1로 정규화
wine_norm = (wine - wine.min()) / (wine.max() - wine.min())
wine_norm.describe() |
4. 데이터 셔플
#데이터를 랜덤하게 섞기
wine_shuffle = wine_norm.sample(frac=1)
wine_np = wine_shuffle.to_numpy()
print(wine_np[:5])| [[0.26446281 0.06 0.44578313 0.18711656 0.05980066 0.07986111 0.2764977 0.13668787 0.41860465 0.08988764 0.60869565 0.83333333 1. ] [0.32231405 0.37333333 0.12650602 0.02453988 0.11295681 0.10763889 0.29262673 0.16367843 0.42635659 0.12921348 0.27536232 0.33333333 0. ] [0.24793388 0.20666667 0.20481928 0.10429448 0.01827243 0.12847222 0.29262673 0.09658762 0.35658915 0.12359551 0.57971014 0.66666667 1. ] [0.20661157 0.13333333 0.28313253 0.16257669 0.05149502 0.20833333 0.4078341 0.1698477 0.31007752 0.16292135 0.2173913 0.5 1. ] [0.29752066 0.18 0.12048193 0.20398773 0.07475083 0.21527778 0.51382488 0.22691344 0.30232558 0.15730337 0.13043478 0.5 1. ]] |
5. 훈련 데이터와 테스트 데이터 만들기
#80%에 해당하는 인덱스 구하기
train_idx = int(len(wine_np) * 0.8)
#80% 기준으로 훈련 데이터 와 테스트 데이터 분리
train_X, train_Y = wine_np[:train_idx, :-1], wine_np[:train_idx, -1]
test_X, test_Y = wine_np[train_idx:, :-1], wine_np[train_idx:, -1]
#타겟을 원핫인코딩을 수행
train_Y = tf.keras.utils.to_categorical(train_Y, num_classes=2)
test_Y = tf.keras.utils.to_categorical(test_Y, num_classes=2)
print(train_Y[0])| [0. 1.] |
- 일반 머신러닝 알고리즘에서는 타겟을 원핫인코딩 하지 않음
6. 분류 모델 생성
- 마지막 층의 units 은 출력하는 데이터의 개수로 회귀는 1 분류는 2 이상
- 분류 문제의 activation 은 softmax를 많이 사용
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=48, activation='relu', input_shape=(12,)),
tf.keras.layers.Dense(units=24, activation='relu'),
tf.keras.layers.Dense(units=12, activation='relu'),
tf.keras.layers.Dense(units=2, activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.07),
loss='categorical_crossentropy',
metrics=['accuracy'])
model.summary() |
- softmax 함수는 자연 로그의 밑인 e의 지수를 사용해 계산한 뒤 모두 더한 값으로 나누는데 이렇게 나온 결과는 총합이 1.0 인 확률값
- softmax 는 분류 나 RNN 에서 다음 토큰 예측 등 결괏값으로 확률이 필요한 분야에서 사용
- 이 경우는 [0.97, 0.03] 으로 나오는데 앞이 red 와인일 확률이고 1이 white 와인일 확률
- 시그모이드 처럼 곡선 함수
#소프트맥스 함수
#소프트맥스 함수
import math
x = np.arange(-2, 2, 0.01)
e_x = math.e ** x
plt.plot(x, e_x)
plt.show() |
- entropy: 정보이론에서 정보량을 나타내기 위해 사용하는 단위
- 확률의 역수에 로그를 취한 값
- -log확률
- 확률이 높은 사건일 수 록 정보량이 적다고 판단하기 때문
- 엔트로피의 기댓값은 엔트로피에 확률을 곱해준 값
- 엔트로피가 높은 것은 높은 불확실성을 나타냄
- 분류문제에서 불확실성의 정도는 낮추는 방향으로 학습을 진행
- 분류 문제에서는 어느 한쪽의 확률이 높은 쪽으로 학습을 진행
7. 훈련
- 32개씩 가지고 학습
- 25% 검증 데이터로 만들어서 확인
- 총 25번 진행
history = model.fit(train_X, train_Y, epochs=25,
batch_size=32, validation_split=0.25) |
8. 모델 평가
model.evaluate(test_X, test_Y) |
- 이진 분류를 할 때 타겟은 2개의 속성으로 만들어져야 하고 출력 층에서 unit의 개수는 2개이고 손실 함수로 categorical_crossentropy를 사용하고 출력 층의 activation 함수는 softmax를 사용
- 다중 클래스 분류는 출력 층에서 unit 개수만 변경하면 됩니다.
9. 다중 클래스 분류
#타겟으로 사용할 만한 특성 확인
print(wine['quality'].describe())| count 6497.000000 mean 5.818378 std 0.873255 min 3.000000 25% 5.000000 50% 6.000000 75% 6.000000 max 9.000000 Name: quality, dtype: float64 |
#샘플의 타겟 비율이 5:1 정도가 넘어가면 샘플링 비율을 조정
print(wine['quality'].value_counts())| quality 6 2836 5 2138 7 1079 4 216 8 193 3 30 9 5 Name: count, dtype: int64 |
#6을 기준으로 6보다 작으면 0 6이면 1 7이상이면 2로 구간화
wine.loc[wine['quality'] <= 5, 'new_quality'] = 0
wine.loc[wine['quality'] == 6, 'new_quality'] = 1
wine.loc[wine['quality'] >= 7, 'new_quality'] = 2
print(wine['new_quality'].value_counts())| new_quality 1.0 2836 0.0 2384 2.0 1277 Name: count, dtype: int64 |
#불필요한 데이터 제거
del wine['quality']
#정규화
- 딥러닝을 할 때는 이 작업을 하지 않아도 되는데 대신에 epoch 를 늘려주던지 아니면 layer을 더 많이 쌓아 해결
wine_backup = wine.copy()
wine_norm = (wine - wine.min()) / (wine.max() - wine.min())
wine_norm['new_quality'] = wine_backup['new_quality']
#셔플
- 데이터를 읽을 때 순서대로 데이터를 읽었기 때문에 셔플을 하지 않으면 샘플링할 때 어느 한 쪽 데이터가 과표집(많이 표집) 될 수 있다.
- 여론조사는 컨벤션 효과라고 하는 것 때문에 과표집 문제가 많이 발생
wine_shuffle = wine_norm.sample(frac=1)
print(type(wine_shuffle))
wine_np = wine_shuffle.to_numpy()| <class 'pandas.core.frame.DataFrame'> |
train_idx = int(len(wine_np) * 0.8)
train_X, train_Y = wine_np[:train_idx, :-1], wine_np[:train_idx, -1]
test_X, test_Y = wine_np[train_idx:, :-1], wine_np[train_idx:, -1]- 딥러닝을 이용해서 분류를 할 때는 타겟을 원핫인코딩 하는 경우가 많다.
- 분류를 할 때는 activation 을 softmax로 설정하는 경우가 많은데 softmax는 각 클래스에 대한 기대값을 확률의 형태로 나타낸다.
- 출력이 여러 개의 값으로 구성된다.
- 가장 기대값이 높은 인덱스에 1을 설정하고 나머지는 0으로 설정
train_Y = tf.keras.utils.to_categorical(train_Y, num_classes=3)
test_Y = tf.keras.utils.to_categorical(test_Y, num_classes=3)
# 분류 모델 생성
- 마지막 층의 units 은 출력하는 데이터의 개수로 회귀는 1 분류는 2 이상
- 분류 문제의 activation 은 softmax를 많이 사용
- 분류를 할 때 3가지 모양을 가져야 하므로 마지막 층의 units 만 3으로 수정
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=48, activation='relu', input_shape=(12,)),
tf.keras.layers.Dense(units=24, activation='relu'),
tf.keras.layers.Dense(units=12, activation='relu'),
tf.keras.layers.Dense(units=6, activation='relu'),
tf.keras.layers.Dense(units=3, activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.003),
loss='categorical_crossentropy',
metrics=['accuracy'])
model.summary()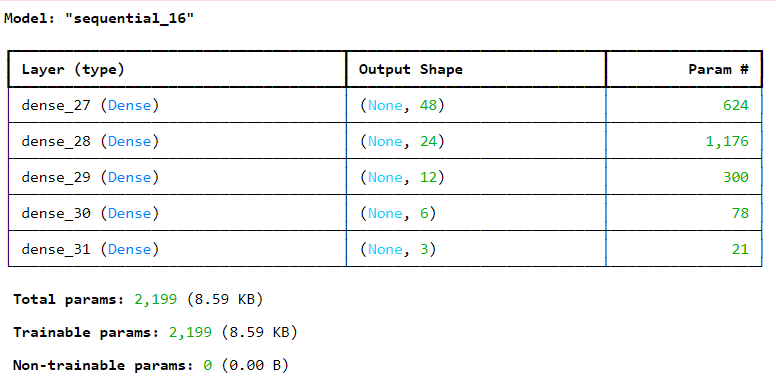 |
model.fit(train_X, train_Y, epochs=25, batch_size=32,
validation_split=0.25) |
model.evaluate(test_X, test_Y) |
'Python > Python 실전편' 카테고리의 다른 글
| [전처리] 서울시 구별 CCTV와 인구 관계 분석 (0) | 2024.03.20 |
|---|---|
| [딥러닝] Keras _ 패션 이미지 분류 (0) | 2024.03.20 |
| [Python] 선형회귀 실습 _ 보스톤 주택 가격에 대한 선형 회귀 (0) | 2024.03.18 |
| [Python] 연관분석 실습 _ 아이템 기반 추천 시스템 (1) | 2024.03.18 |
| [Python] 연관분석 실습 _ 영화 콘텐츠 기반 필터링 추천 시스템 (1) | 2024.03.15 |