
데이터
https://www.kaggle.com/tmdb/tmdb-movie-metadata
1. 데이터 읽어오기
movies =pd.read_csv('./python_machine_learning-main/data/tmdb_5000_movies.csv')
print(movies.shape)
movies.head()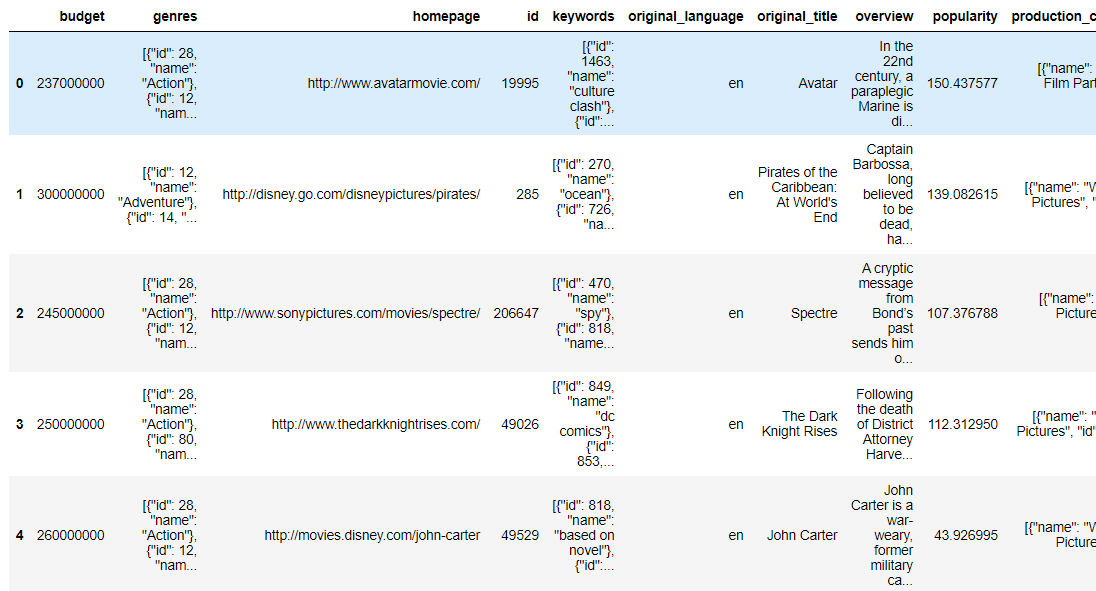  |
# 데이터 생성
movies_df = movies[['id','title', 'genres', 'vote_average', 'vote_count',
'popularity', 'keywords', 'overview']]
# pd.set_option('max_colwidth', 100)
movies_df.head(1) |
- genres와 keywords는 하나의 문자열이 아니라 list다.
- csv 파일을 만드려고 list를 문자열로 만들기 위해 " "로 감싸는 형태로 만들었다.
- 파이썬이나 자바스크립트는 json 포맷의 문자열로 데이터를 표현한다.
+ 문자열로 만들어진 데이터를 원래의 자료형으로 되돌리는 API가 제공된다.- python에서는 ast 모듈의 literal_eval 함수 이용 (직접 파싱할 필요 X)
- "[apple, pear, watermelon]" -> literal_eval(데이터) -> [apple, pear, watermelon]
print(movies_df[['genres', 'keywords']][:1])| genres \ 0 [{"id": 28, "name": "Action"}, {"id": 12, "nam... keywords 0 [{"id": 1463, "name": "culture clash"}, {"id":... |
#데이터 변환
from ast import literal_eval
#문자열을 파이썬 객체로 변환
movies_df['genres'] = movies_df['genres'].apply(literal_eval)
movies_df['keywords'] = movies_df['keywords'].apply(literal_eval)
#디셔너리에서 데이터만 추출
movies_df['genres'] = movies_df['genres'].apply(lambda x : [ y['name'] for y in x])
movies_df['keywords'] = movies_df['keywords'].apply(lambda x : [ y['name'] for y in x])
#데이터 확인
movies_df[['genres', 'keywords']][:1] |
2. 장르 유사도 측정
- 문자열을 피처로 만드는 방법은 CountVectorizer, TfidfVectorizer
- 장르 리스트 안에서 같은 단어가 나올 수 없으니 등장 횟수만을 기반으로 하는 CountVectorizer 사용
#피처 벡터화
from sklearn.feature_extraction.text import CountVectorizer
# CountVectorizer를 적용하기 위해 공백문자로 word 단위가 구분되는 문자열로 변환.
movies_df['genres_literal'] = movies_df['genres'].apply(lambda x : (' ').join(x))
print(movies_df['genres_literal'])| 0 [ { " i d " : 2 8 , " n a m e " : " A c ... 1 [ { " i d " : 1 2 , " n a m e " : " A d ... 2 [ { " i d " : 2 8 , " n a m e " : " A c ... 3 [ { " i d " : 2 8 , " n a m e " : " A c ... 4 [ { " i d " : 2 8 , " n a m e " : " A c ... ... |
count_vect = CountVectorizer(min_df=0.0, ngram_range=(1,2))
genre_mat = count_vect.fit_transform(movies_df['genres_literal'])
print(genre_mat.shape)| (4803, 276) |
# 장르의 코사인 유사도 측정
from sklearn.metrics.pairwise import cosine_similarity
genre_sim = cosine_similarity(genre_mat, genre_mat)
print(genre_sim.shape)
print(genre_sim[:2])| (4803, 4803) [[1. 0.59628479 0.4472136 ... 0. 0. 0. ] [0.59628479 1. 0.4 ... 0. 0. 0. ]] |
# 유사도 측정
genre_sim_sorted_ind = genre_sim.argsort()[:, ::-1] #전부
print(genre_sim_sorted_ind[:1])| [[ 0 3494 813 ... 3038 3037 2401]] |
# 영화 정보 데이터프레임과 영화 정보 인덱스와 영화 제목과 추천할 영화 개수를 입력하면
영화 제목과 평점을 리턴해주는 함수
def find_sim_movie(df, sorted_ind, title_name, top_n=10):
# 인자로 입력된 movies_df DataFrame에서 'title' 컬럼이 입력된 title_name 값인 DataFrame추출
title_movie = df[df['title'] == title_name]
# title_named을 가진 DataFrame의 index 객체를 ndarray로 반환하고
# sorted_ind 인자로 입력된 genre_sim_sorted_ind 객체에서 유사도 순으로 top_n 개의 index 추출
title_index = title_movie.index.values
similar_indexes = sorted_ind[title_index, :(top_n)] #자기 영화 제외하려면 1:(top_m)
# 추출된 top_n index들 출력. top_n index는 2차원 데이터
#dataframe에서 index로 사용하기 위해서 1차원 array로 변경
print(similar_indexes)
similar_indexes = similar_indexes.reshape(-1)
return df.iloc[similar_indexes]similar_movies = find_sim_movie(movies_df, genre_sim_sorted_ind, 'The Dark Knight Rises',10)
similar_movies[['title', 'vote_average', 'vote_count']].sort_values('vote_average', ascending=False) |
3. 가중 평점
- 평점을 많이 매기지 않은 데이터가 평점이 높게 나오는 경향이 있을 수 있다.
- 데이터의 개수가 작으면 극단치의 영향을 많이 받기 때문이다.
- 데이터 개수에 따른 보정을 해줄 필요가 있다.
- IMDB에서 권장
가중 평점(Weighted Rating) =(v/(v+m)) * R+ (m/(v+m)) * C
- v: 개별 영화에 평점을 투표한 횟수
- m: 평점을 부여하기 위한 최소 투표 횟수
- R: 개별 영화에 평균 평점
- C: 전체 영화에 대한 평균 평점
# 가중 평점 부여
C = movies_df['vote_average'].mean()
m = movies_df['vote_count'].quantile(0.6)
print('C:',round(C,3), 'm:',round(m,3))| C: 6.092 m: 370.2 |
def weighted_vote_average(record):
v = record['vote_count']
R = record['vote_average']
return ( (v/(v+m)) * R ) + ( (m/(m+v)) * C )
movies_df['weighted_vote'] = movies_df.apply(weighted_vote_average, axis=1)movies_df['weighted_vote'] = movies_df.apply(weighted_vote_average, axis=1)
movies_df[['title', 'vote_average', 'weighted_vote', 'vote_count']][:10] |
# 가중치 조정
def find_sim_movie(df, sorted_ind, title_name, top_n=10):
title_movie = df[df['title'] == title_name]
title_index = title_movie.index.values
# top_n의 2배에 해당하는 쟝르 유사성이 높은 index 추출
similar_indexes = sorted_ind[title_index, :(top_n*2)]
similar_indexes = similar_indexes.reshape(-1)
# 기준 영화 index는 제외
similar_indexes = similar_indexes[similar_indexes != title_index]
# top_n의 2배에 해당하는 후보군에서 weighted_vote 높은 순으로 top_n 만큼 추출
return df.iloc[similar_indexes].sort_values('weighted_vote', ascending=False)[:top_n]
similar_movies = find_sim_movie(movies_df, genre_sim_sorted_ind, 'The Godfather',10)
similar_movies[['title', 'vote_average', 'weighted_vote']] |
지금은 장르기반으로만 추천했지만, 가장 최근에 끝난 것에도 가중치 부여할 수 있다.
- ex. 범죄도시 4 개봉한다고 하면, 범죄도시 2-3를 보여주는 것처럼!
'Python > Python 실전편' 카테고리의 다른 글
| [딥러닝] Keras 이항분류 _ 레드와 화이트와인 분류 (0) | 2024.03.20 |
|---|---|
| [Python] 선형회귀 실습 _ 보스톤 주택 가격에 대한 선형 회귀 (0) | 2024.03.18 |
| [Python] 연관분석 실습 _ 아이템 기반 추천 시스템 (1) | 2024.03.18 |
| [Python] Pandas 실습 _ 카카오 검색 API 데이터 가져오기 (0) | 2024.03.15 |
| [Python] 연관분석 실습 _ 손흥민 (1) | 2024.03.15 |