
설치
!pip install apyori1. 데이터 읽어오기
df = pd.read_csv("./python_machine_learning-main/data/tweet_temp.csv")
df.head() |
#한글 정제 함수
import re
# 한글만 추출
def text_cleaning(text):
hangul = re.compile('[^ ㄱ-ㅣ가-힣]+') # 한글의 정규표현식
result = hangul.sub('', text)
return result
#적용
# ‘tweet_text’ 피처에 적용
df['ko_text'] = df['tweet_text'].apply(lambda x: text_cleaning(x))
df.head() |
2. 불용어 처리
- https://www.ranks.nl/stopwords/korean
from collections import Counter
# 한국어 약식 불용어사전 예시 파일 - https://www.ranks.nl/stopwords/korean
korean_stopwords_path = "./python_machine_learning-main/korean_stopwords.txt"
with open(korean_stopwords_path, encoding='utf8') as f:
stopwords = f.readlines()
#앞뒤 공백 제거
stopwords = [x.strip() for x in stopwords]
print(stopwords)| ['아', '휴', '아이구', '아이쿠', '아이고', '어', '나', '우리', '저희', '따라', '의해', '을', '를', '에', '의', '가', '으로', '로', '에게', '뿐이다', '의거하여', '근거하여', '입각하여', '기준으로', '예하면', '예를 들면', '예를 들자면', '저', '소인', '소생', '저희', '지말고', '하지마', '하지마라', '다른', '물론', '또한', '그리고', ... |
# 문자열 대입받아서 명사만 추출, 1글자는 제거하고 불용어도 제거해서 리턴
from konlpy.tag import Okt
def get_nouns(x):
nouns_tagger = Okt()
nouns = nouns_tagger.nouns(x)
# 한글자 키워드를 제거
nouns = [noun for noun in nouns if len(noun) > 1]
# 불용어를 제거
nouns = [noun for noun in nouns if noun not in stopwords]
return nouns.
# ‘ko_text’ 피처에 적용
df['nouns'] = df['ko_text'].apply(lambda x: get_nouns(x))
print(df.shape)
df.head()(525, 4)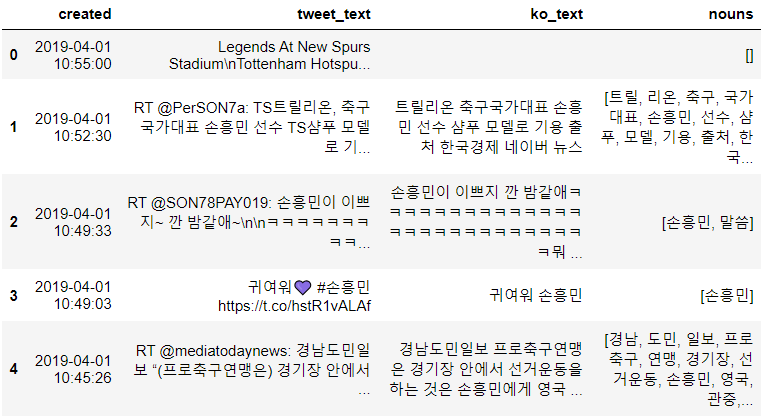 |
- 연관 규칙 분석을 할 떄는 데이터가 리스트 형태로 만들어지면 됨
- 상품 거래 연관 규칙 분석을 할 때는 구매한 상품 목록을 list로 만들면 됨 ex. ['사과', '배', '한라봉']
3. 연관 규칙 분석
from apyori import apriori
# 장바구니 형태의 데이터(트랜잭션 데이터)를 생성
transactions = [
['손흥민', '시소코'],
['손흥민', '케인'],
['손흥민', '케인', '포체티노']
]
# 연관 분석을 수행
results = list(apriori(transactions))
for result in results:
print(result)| RelationRecord(items=frozenset({'손흥민'}), support=1.0, ordered_statistics=[OrderedStatistic(items_base=frozenset(), items_add=frozenset({'손흥민'}), confidence=1.0, lift=1.0)]) RelationRecord(items=frozenset({'시소코'}), support=0.3333333333333333, ordered_statistics=[OrderedStatistic(items_base=frozenset(), items_add=frozenset({'시소코'}), confidence=0.3333333333333333, lift=1.0)]) ... RelationRecord(items=frozenset({'포체티노', '손흥민'}), support=0.3333333333333333, ordered_statistics=[OrderedStatistic(items_base=frozenset(), items_add=frozenset({'포체티노', '손흥민'}), confidence=0.3333333333333333, lift=1.0), OrderedStatistic(items_base=frozenset({'손흥민'}), items_add=frozenset({'포체티노'}), confidence=0.3333333333333333, lift=1.0), OrderedStatistic(items_base=frozenset({'포체티노'}), items_add=frozenset({'손흥민'}), confidence=1.0, lift=1.0)]) ... |
# 트랜잭션 데이터를 추출합니다.
transactions = df['nouns'].tolist()
transactions = [transaction for transaction in transactions if transaction] # 공백 문자열 방지
print(transactions)| [['트릴', '리온', '축구', '국가대표', '손흥민', '선수', '샴푸', '모델', '기용', '출처', '한국', '경제', '네이버', '뉴스'], ['손흥민', '말씀'], ['손흥민'], ['경남', '도민', '일보', '프로축구', '연맹', '경기장', '선거운동', '손흥민', '영국', '관중', '인종차별', '행위', '보고', '축구장', '선거운동', '규정', '위반', '이야기'], ['선택', '손흥민', '축구'], ['토트넘', '골수팬', '승부사', '제일', '선수', '손흥민', '입다'], ['계정', '지기', '실수', '삭제', '다시', '하리보', '손흥민', '홍보', '모델', '발탁', '기념', '해당', '추첨', '통해', '하리보', '골드바', '기간'], ['안녕하십니까', '손흥민', '트위터', '매우', '오늘', '경기도', '관심'], ... |
# 연관분석
# 연관 분석을 수행
results = list(apriori(transactions,
min_support=0.1,
min_confidence=0.2,
min_lift=5,
max_length=2))
for result in results:
print(result)| [RelationRecord(items=frozenset({'국가대표팀', '게임'}), support=0.14285714285714285, ordered_statistics=[OrderedStatistic(items_base=frozenset({'게임'}), items_add=frozenset({'국가대표팀'}), confidence=1.0, lift=7.0), OrderedStatistic(items_base=frozenset({'국가대표팀'}), items_add=frozenset({'게임'}), confidence=1.0, lift=7.0)]), RelationRecord(items=frozenset({'게임', '금메달'}), support=0.14285714285714285, ordered_statistics=[OrderedStatistic(items_base=frozenset({'게임'}), items_add=frozenset({'금메달'}), confidence=1.0, lift=7.0), OrderedStatistic(items_base=frozenset({'금메달'}), items_add=frozenset({'게임'}), confidence=1.0, lift=7.0)]), RelationRecord(items=frozenset({'모습', '게임'}), support=0.14285714285714285, ordered_statistics=[OrderedStatistic(items_base=frozenset({'게임'}), items_add=frozenset({'모습'}), confidence=1.0, lift=7.0), OrderedStatistic(items_base=frozenset({'모습'}), items_add=frozenset({'게임'}), confidence=1.0, lift=7.0)]), RelationRecord(items=frozenset({'아시아', '게임'}), support=0.14285714285714285, ordered_statistics=[OrderedStatistic(items_base=frozenset({'게임'}), items_add=frozenset({'아시아'}), confidence=1.0, lift=7.0), OrderedStatistic(items_base=frozenset({'아시아'}), items_add=frozenset({'게임'}), confidence=1.0, lift=7.0)]), ... |
- 하나의 항목은 제거
# 데이터 프레임 형태로 정리
# 데이터 프레임 형태로 정리
columns = ['source', 'target', 'support']
network_df = pd.DataFrame(columns=columns)
# 규칙의 조건절을 source, 결과절을 target, 지지도를 support 라는 데이터 프레임의 피처로 변환
for result in results:
items = [x for x in result.items]
row = [items[0], items[1], result.support]
series = pd.Series(row, index=network_df.columns)
network_df.loc[len(network_df)] = series
network_df.head()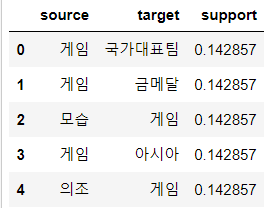 |
4. 키워드 빈도 추출
from konlpy.tag import Okt
from collections import Counter
# 명사 키워드를 추출
nouns_tagger = Okt()
nouns = nouns_tagger.nouns(tweet_corpus)
count = Counter(nouns)
# 한글자 키워드를 제거
remove_char_counter = Counter({x : count[x] for x in count if len(x) > 1})
print(remove_char_counter)| Counter({'손흥민': 560, '하리보': 245, '축구': 140, '선수': 140, '조현우': 140, '황의조': 140, '금메달': 140, '모델': 105, '한국': 105, '신제품': 105, '선거운동': 70, '보고': 70, '계정': 70, '지기': 70, '실수': 70, '삭제': 70, '다시': 70, '홍보': 70, '발탁': 70, '기념': 70, '해당': 70, '추첨': 70, '통해': 70, '골드바': 70, '기간': 70, '출국': 70, '국가대표팀': 70, '아시아': 70, '게임': 70, '모습': 70, '의조': 70, '진짜': 70, '트릴': 35, '리온': 35, '국가대표': 35, '샴푸': 35, '기용': 35, '출처': 35, '경제': 35, '네이버': 35, '뉴스': 35, '말씀': 35, '경남': 35, '도민': 35, '일보': 35, '프로축구': 35, '연맹': 35, '경기장': 35, '영국': 35, '관중': 35, '인종차별': 35, '행위': 35, '축구장': 35, '규정': 35, '위반': 35, '이야기': 35, '선택': 35, '토트넘': 35, '골수팬': 35, '승부사': 35, '제일': 35, '입다': 35, '안녕하십니까': 35, '트위터': 35, '매우': 35, '오늘': 35, '경기도': 35, '관심': 35, '긴급': 35, '속보': 35, '개시': 35, '샤인': 35, '가장': 35, '먼저': 35, '팔로우': 35, '알림': 35, '설정': 35, '두기': 35}) |
# 단어와 등장횟수를 가지고 DataFrame 생성
# 키워드와 키워드 빈도 점수를 ‘node’, ‘nodesize’ 라는 데이터 프레임의 피처로 생성
node_df = pd.DataFrame(remove_char_counter.items(), columns=['node', 'nodesize'])
node_df = node_df[node_df['nodesize'] >= 50] # 시각화의 편의를 위해 ‘nodesize’ 50 이하는 제거합니다.
node_df.head() |
# networkx
import networkx as nx
plt.figure(figsize=(12,12))
# networkx 그래프 객체
G = nx.Graph()
# node_df의 키워드 빈도수를 데이터로 하여, 네트워크 그래프의 ‘노드’ 역할을 하는 원을 생성
for index, row in node_df.iterrows():
G.add_node(row['node'], nodesize=row['nodesize'])
# network_df의 연관 분석 데이터를 기반으로, 네트워크 그래프의 ‘관계’ 역할을 하는 선을 생성
for index, row in network_df.iterrows():
G.add_weighted_edges_from([(row['source'], row['target'], row['support'])])
# 그래프 디자인과 관련된 파라미터를 설정
pos = nx.spring_layout(G, k=0.6, iterations=50)
sizes = [G.nodes[node]['nodesize']*25 for node in G]
nx.draw(G, pos=pos, node_size=sizes, node_color='yellow')
#레이블 출력 (한글폰트)
nx.draw_networkx_labels(G, pos=pos, font_family='Malgun Gothic', font_size=25)
# 그래프 출력
ax = plt.gca()
plt.show()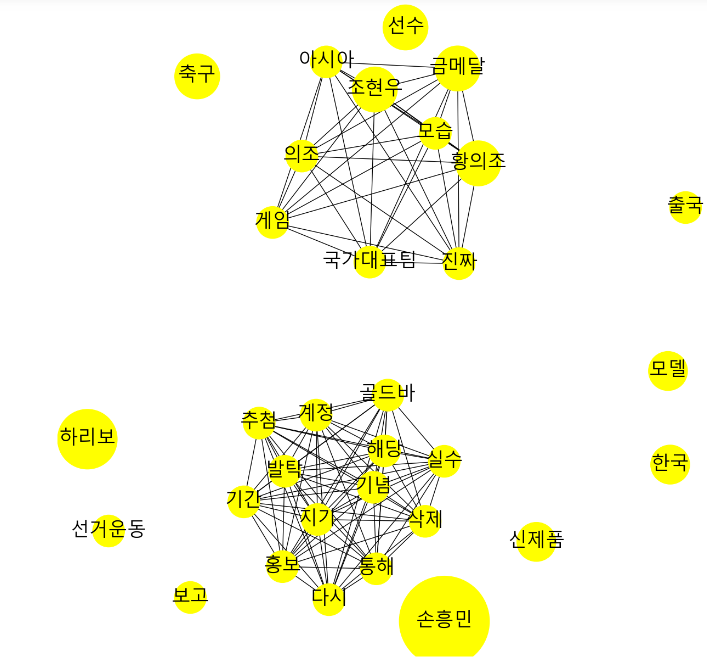 |
'Python > Python 실전편' 카테고리의 다른 글
| [딥러닝] Keras 이항분류 _ 레드와 화이트와인 분류 (0) | 2024.03.20 |
|---|---|
| [Python] 선형회귀 실습 _ 보스톤 주택 가격에 대한 선형 회귀 (0) | 2024.03.18 |
| [Python] 연관분석 실습 _ 아이템 기반 추천 시스템 (1) | 2024.03.18 |
| [Python] 연관분석 실습 _ 영화 콘텐츠 기반 필터링 추천 시스템 (1) | 2024.03.15 |
| [Python] Pandas 실습 _ 카카오 검색 API 데이터 가져오기 (0) | 2024.03.15 |