
1. Kaggle 자전거 대여 수요 예측
- 예측 모델 및 분석 대회 플랫폼
- 현재는 구글이 운영
- url - https://www.kaggle.com/c/bike-sharing-demand
Bike Sharing Demand | Kaggle
www.kaggle.com
- 미션: 날짜, 계절, 근무일 여부, 온도, 체감온도, 풍속 등의 데이터를 이용해서 자전거 대여 수요 예측
- 유형: 회귀
- 평가 지표: RMSLE

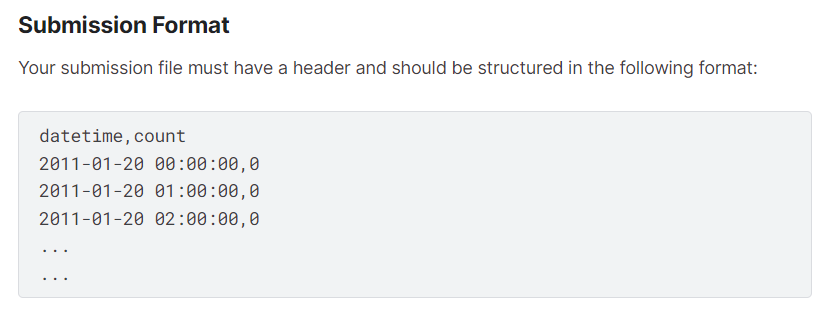
- sampleSubmission.csv 참고
실제 데이터 확인
* test 데이터에 없는 train 데이터의 피처는 삭제 해야함
2. 데이터 탐색
# 데이터 가져오기
import pandas as pd
train = pd.read_csv('./bike/train.csv')
test = pd.read_csv('./bike/test.csv')
submission = pd.read_csv('./bike/sampleSubmission.csv')
# 훈련 데이터 구조 확인
train.info() |
- 훈련 데이터에는 결측치가 없다.
- datetime이 진짜 객체 타입인지 확인 (dtype)
# 테스트 데이터 구조 확인
test.info() |
- train 데이터에는 존재하지만 test 데이터에는 존재하지 않는 컬럼을 발견
- casual, registered, count
- count는 타겟이라서 없는 것
- 훈련을 할 때 casual과 registered는 제외
- 피처에 대한 설명
- datetime - hourly date + timestamp
- season - 1 = spring, 2 = summer, 3 = fall, 4 = winter
- holiday - whether the day is considered a holiday *0: 공휴일 아닌 날 / 1: 공휴일
- workingday - whether the day is neither a weekend nor holiday *0: 주말 및 국경일 / 1: 근무날
- weather
1: Clear, Few clouds, Partly cloudy, Partly cloudy
2: Mist + Cloudy, Mist + Broken clouds, Mist + Few clouds, Mist
3: Light Snow, Light Rain + Thunderstorm + Scattered clouds, Light Rain + Scattered clouds
4: Heavy Rain + Ice Pallets + Thunderstorm + Mist, Snow + Fog - temp - temperature in Celsius
- atemp - "feels like" temperature in Celsius
- humidity - relative humidity
- windspeed - wind speed
- casual - number of non-registered user rentals initiated *예약하지 않은 사용자의 대여 횟수
- registered - number of registered user rentals initiated *예약 사용자의 대여 횟수
- count - number of total rentals
- 날짜의 경우는 DateTime으로 변환해서 분할해보는 것이 좋다.
train['datetime'] = train.datetime.apply(pd.to_datetime)| 0 datetime 10886 non-null datetime64[ns] |
train ['year'] = train['datetime'].apply(lambda x:x.year)
train ['month'] = train['datetime'].apply(lambda x:x.month)
train ['day'] = train['datetime'].apply(lambda x:x.day)
train ['hour'] = train['datetime'].apply(lambda x:x.hour)
train ['minute'] = train['datetime'].apply(lambda x:x.minute)
train ['second'] = train['datetime'].apply(lambda x:x.second)
train ['weekday'] = train['datetime'].apply(lambda x:x.weekday()) |
- 범주형은 원래 이름으로 변경해 두는 것이 좋다.
- 탐색을 할 때는 시각화를 많이 하게 되는데 시각화할 때 0이나 1같은 숫자보다는 spring이나 fall 같은 명시적인 의미를 가진 데이터가 보기 좋기 때문이다.
- season, weather 변환
train['season'] = train['season'].map({
1:'봄', 2:'여름', 3:'가을', 4:'겨울'
})
train['weather'] = train['weather'].map({
1:'맑음', 2:'흐림', 3:'약한 눈/비', 4:'강한 눈/비'
}) |
#시각화를 위한 설정
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
#한글을 위한 설정
#시각화에서 한글을 사용하기 위한 설정
import platform
from matplotlib import font_manager, rc
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font', family=font_name)
#경진대회에서만 사용
import warnings
warnings.filterwarnings(action='ignore')
- 타겟 확인
- 타겟이 범주형인 경우 확인해서 특정 범주의 데이터가 아주 많거나 작으면 층화 추출이나 오버샘플링이나 언더샘플링 고려
- 타겟이 연속형인 경우 정규 분포에 가까운지 확인해서 한쪽으로 몰려있으면 로그변환으로 분포 변경
sns.displot(train['count'])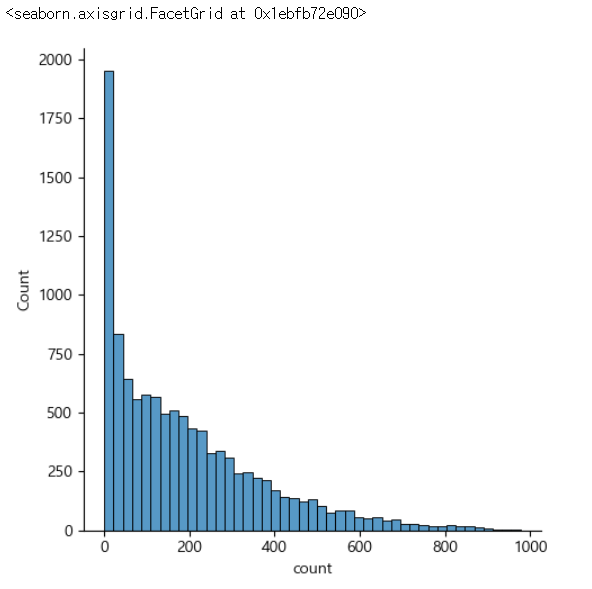 |
- 데이터의 분포가 왼쪽으로 치우쳐져 있다.
# 타겟을 로그 변환해서 시각화
import numpy as np
sns.distplot(np.log(train['count']))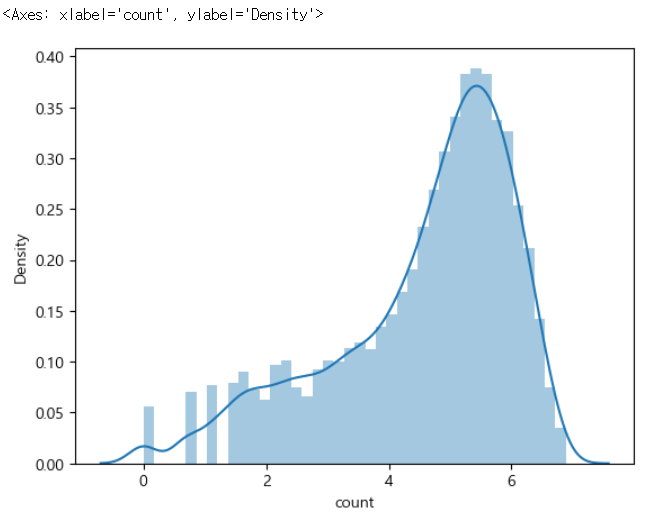 |
# 년월일 시분초에 따른 타겟의 변환
figure, axes = plt.subplots(nrows=3, ncols=2)
sns.barplot(x='year', y='count', data=train, ax=axes[0, 0])
sns.barplot(x='month', y='count', data=train, ax=axes[0, 1])
sns.barplot(x='day', y='count', data=train, ax=axes[1, 0])
sns.barplot(x='hour', y='count', data=train, ax=axes[1, 1])
sns.barplot(x='minute', y='count', data=train, ax=axes[2, 0])
sns.barplot(x='second', y='count', data=train, ax=axes[2, 1])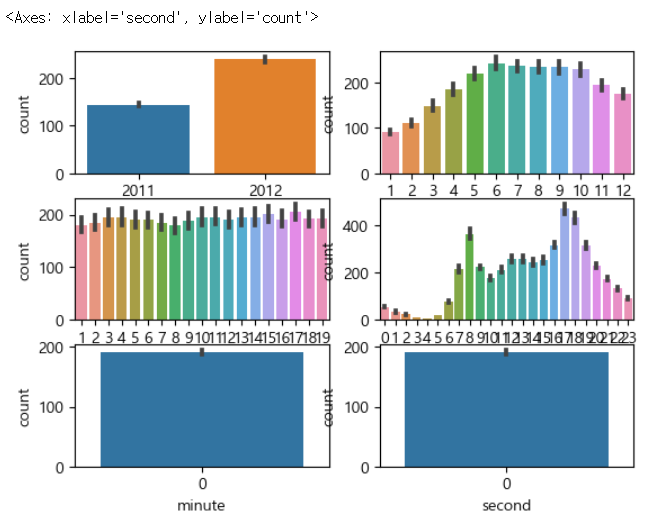 |
- 각 데이터가 유의미한 변화를 가져오면 훈련에 사용을 해야 하고 거의 변화가 없다면 제거
- 분산이 아주 작다면 유의미한 변화를 가져올 수 없기 때문에 제거
- 일은 별로 상관이 없음 - 제거
- 시간은 유의미한 변화가 있음
- 분하고 초는 0인걸 보니 빌릴 때 시간까지만 기록해놨음 - 제거
# 계절, 날씨, 공휴일 여부, 근무일 별 대여 수량 시각화
figure, axes = plt.subplots(nrows=2, ncols=2)
sns.barplot(x='season', y='count', data=train, ax=axes[0, 0])
sns.barplot(x='weather', y='count', data=train, ax=axes[0, 1])
sns.barplot(x='holiday', y='count', data=train, ax=axes[1, 0])
sns.barplot(x='workingday', y='count', data=train, ax=axes[1, 1])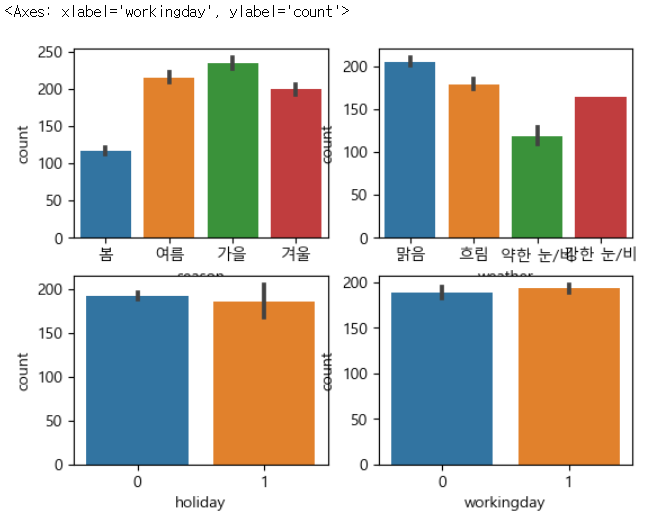 |
- holiday, workingday 여부는 상관이 없는듯함
- 직선이 분산이기도 하다.
# 박스플롯 - 이상치 분포 여부 확인 가능
figure, axes = plt.subplots(nrows=2, ncols=2)
sns.boxplot(x='season', y='count', data=train, ax=axes[0, 0])
sns.boxplot(x='weather', y='count', data=train, ax=axes[0, 1])
sns.boxplot(x='holiday', y='count', data=train, ax=axes[1, 0])
sns.boxplot(x='workingday', y='count', data=train, ax=axes[1, 1])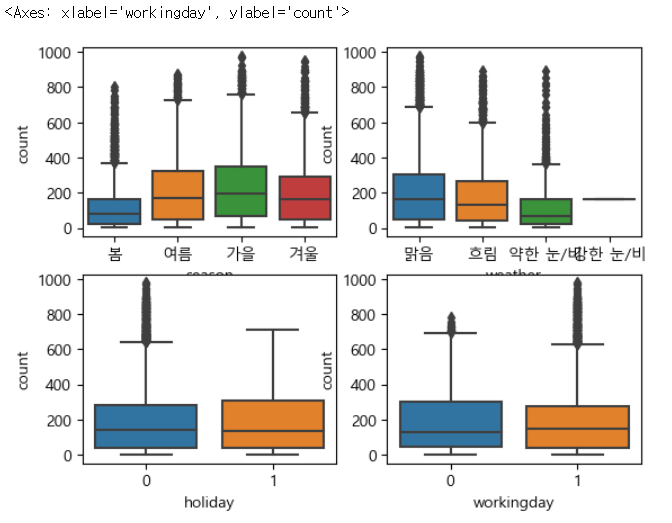 |
# 근무일, 공휴일, 요일, 계절, 날씨에 따른 시간대별 대여수량 확인
figure, axes = plt.subplots(nrows=5)
sns.pointplot(x='hour', y='count', hue='workingday', data=train, ax=axes[0])
sns.pointplot(x='hour', y='count', hue='holiday', data=train, ax=axes[1])
sns.pointplot(x='hour', y='count', hue='weekday', data=train, ax=axes[2])
sns.pointplot(x='hour', y='count', hue='season', data=train, ax=axes[3])
sns.pointplot(x='hour', y='count', hue='weather', data=train, ax=axes[4])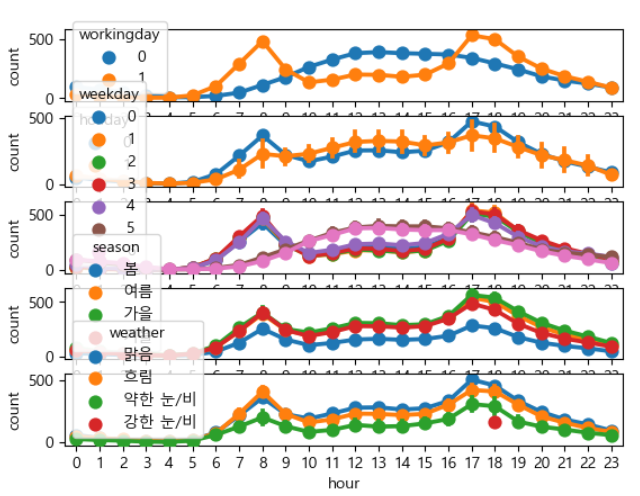 |
- workingday는 출퇴근 시간에, 휴일은 낮에 많다.
- 연속형 데이터는 피처와 상관관계를 파악할 필요가 있다.
- 상관관계가 거의 없다면 제거 가능
- 상관관계 파악 방법
- 상관계수 확인
- 산포도(regplot: 선형회귀 직선을 같이 출력)
- 상관계수 확인 이후 히트맵 같은 도구로 시각화 함
# 온도, 체감온도, 풍속, 습도별 대여수량 확인
figure, axes = plt.subplots(nrows=2, ncols=2)
sns.regplot(x='temp', y='count', scatter_kws={'alpha':0.2},
line_kws={'color':'red'}, data=train, ax=axes[0,0])
sns.regplot(x='atemp', y='count', scatter_kws={'alpha':0.2},
line_kws={'color':'red'}, data=train, ax=axes[0,1])
sns.regplot(x='windspeed', y='count', scatter_kws={'alpha':0.2},
line_kws={'color':'red'}, data=train, ax=axes[1,0])
sns.regplot(x='humidity', y='count', scatter_kws={'alpha':0.2},
line_kws={'color':'red'}, data=train, ax=axes[1,1])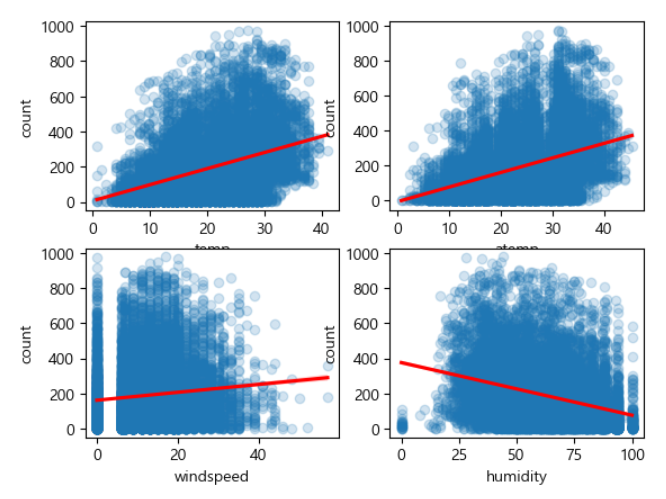 |
3. 규제가 없는 선형회귀 적용
- 이전에 데이터 탐색을 할 때 변경된 내용이 있을 수 있기 때문에 다시 가져오기
# 데이터 가져오기
import pandas as pd
train = pd.read_csv('./bike/train.csv')
test = pd.read_csv('./bike/test.csv')
# 데이터 전처리
- 이상치 제거
- 범주형에서 기본값 이외의 데이터나 수치형 데이터에서 범위에 맞지 않는 데이터 혹은 극단치
- 도메인에 따라 정상적인 입력이라도 이상치로 판단할 수 있다.
ex. 심한 눈이나 비가 내리는데 자전거를 대여하는 상황 등
train = train[train['weather'] != 4]
# train 데이터와 test 데이터 합치기 (동일한 구조 만들기)
- 일반적인 경우 train 데이터와 test 데이터 구조가 같다.
- 경진대회의 경우 train.csv와 test.csv 구조가 다르기도 하다. test.csv에는 타겟이 없다.
- 경진대회는 train 데이터를 가지고 모델을 만들어서 test 데이터의 타겟을 예측해서 제출하고 채점하기 때문
all_data_temp = pd.concat([train, test]) |
- 여러개의 데이터를 행 방향으로 결합할 때 주의할 점!
- 별도의 인덱스를 설정하지 않으면 인덱스는 0부터 시작하는 일련 번호라서
인덱스를 설정하지 않은 상태로 만든 DataFrame을 행 방향으로 결합하면 인덱스가 중첩될 수 있다. - 행은 분명 17383개인데, 번호는 6492번까지밖에 없는 상황
인덱스가 중복돼서 나오기 때문에 데이터 구별이 안될 수 있으므로 기존 인덱스는 무시하고 결합한다.
# 기존 인덱스 무시하고 결합
all_data_temp = pd.concat([train, test], ignore_index=True)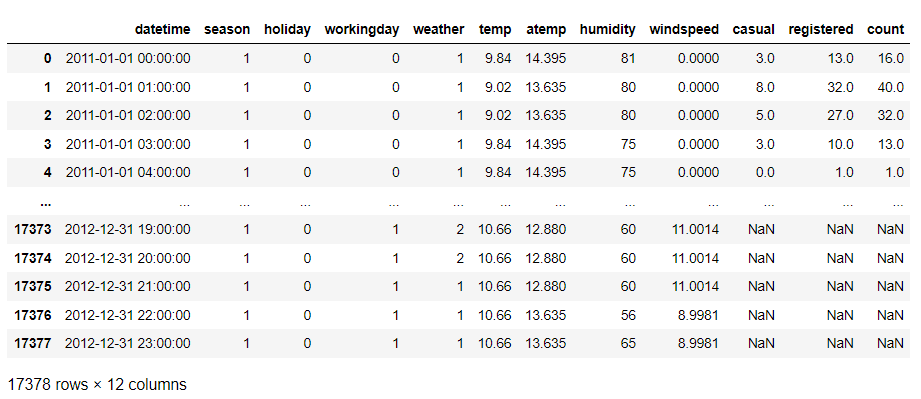 |
# 파생 피처 생성
- datetime을 이용해서 새로운 열 (년 월 일 시 분 초 요일) 생성
- 탐색했을 때 필요 없었던 일, 분, 초 제거
- 년월일, 년, 시, 요일 생성해보기
all_data['datetime'] |
- 공백단위로 쪼개기 _ split 사용 - 정규표현식
- 문자 개수만큼 읽어오기 _ substring(위치, 개수)
from datetime import datetime
#datetime 필드에서 앞의 날짜 부분만 잘라서 date 필드 생성
all_data['date'] = all_data['datetime'].apply(lambda x : x.split()[0])
#datetime 필드에서 앞의 년도 부분만 잘라서 year 필드 생성
all_data['year'] = all_data['datetime'].apply(lambda x : x.split()[0].split('-')[0])
#datetime 필드에서 앞의 시간 부분만 잘라서 hour 필드 생성
all_data['hour'] = all_data['datetime'].apply(lambda x : x.split()[1].split(':')[0])
#datetime 필드에서 요일로 weekday 필드 생성
#날짜 컬럼을 datetime으로 변환하고 weekday 메소드를 호출해서 요일 리턴
all_data['weekday'] = all_data['date'].apply(
lambda x : datetime.strptime(x, '%Y-%m-%d').weekday())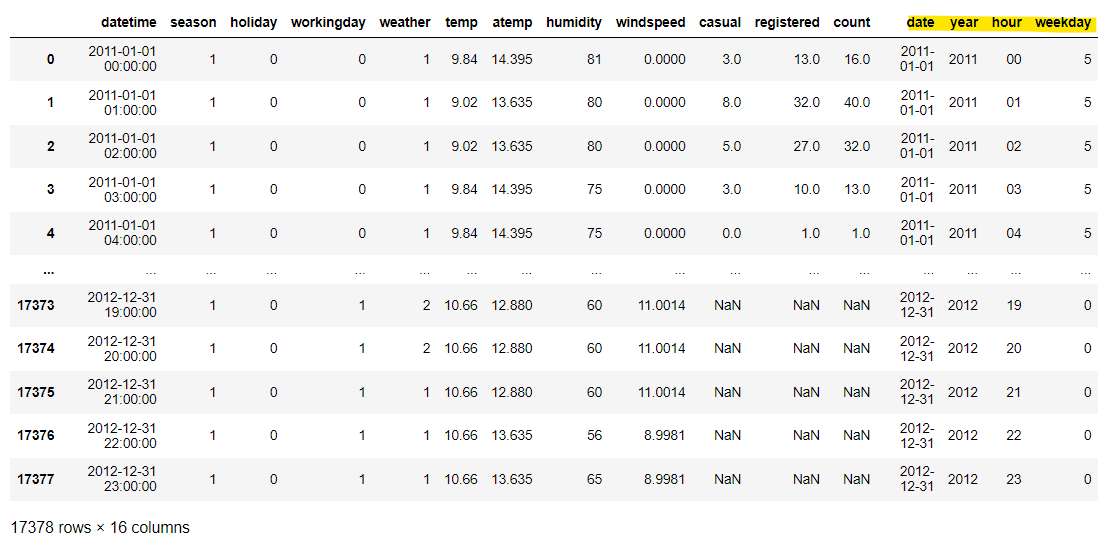 |
# 불필요한 피처 제거
- casual, registered, datetime, date, windspeed
<초보자의 코딩>
all_data = all_data.drop(['casual', 'registered', 'datetime', 'date', 'windspeed'], axis=1)- literal을 많이 쓴다. 그냥 지워버린다.
- 어떤 컬럼을 지웠는지 찾고 싶을 때 나중에 찾아봐야 한다.
<숙련자의 코딩>
all_data = all_data.drop(drop_features, axis=1)- 삭제 작업을 할 때는 내가 무엇을 지웠는지를 변수에 저장해두는 것이 좋다.
- 리터럴을 직접 이용하는 것보다 변수 이용
# 모델 생성 및 훈련
#훈련 데이터와 테스트 데이터 분리
X_train = all_data[~pd.isnull(all_data['count'])]
X_test = all_data[pd.isnull(all_data['count'])]
#피처와 타겟 분리
X_train = X_train.drop(['count'], axis=1)
X_test = X_test.drop(['count'], axis=1)
#원천 데이터에서 count 추출 후 타겟으로 만들기
y = train['count'] |
#평가 지표 함수 생성
- 평가지표: RMSLE
- 타겟이 치우쳐 있어서 로그 변환을 수행하는 것이 좋은 모델을 만들 수 있다.
import numpy as np
#y_true는 실제 값, y_pred는 예측 값, convertExp는 로그 변환 여부
def rmsle(y_true, y_pred, convertExp=True):
#로그 변환을 한 경우에는 원래 값으로 복원
if convertExp:
y_true = np.exp(y_true)
y_pred = np.exp(y_pred)
#로그 변환을 할 때 1을 더해주지 않으면 0이 될 수 있고 에러 발생
#로그 변환을 할 때는 1을 더해서 이를 방지해야 한다.
log_true = np.nan_to_num(np.log(y_true + 1))
log_pred = np.nan_to_num(np.log(y_pred + 1))
#RMSLE 계산
output = np.sqrt((np.mean(log_true-log_pred)**2))
#모델 생성 및 훈련
#모델 생성 및 훈련
from sklearn.linear_model import LinearRegression
linear_reg_model = LinearRegression()
#타겟의 로그 변환
log_y = np.log(y)
#훈련
linear_reg_model.fit(X_train, log_y)
#예측
preds = linear_reg_model.predict(X_train)
print("일반 선형 회귀의 RMSLE:", rmsle(log_y, preds, True))| 일반 선형 회귀의 RMSLE: 1.0204980189305026 |
답안 생성 후 제출
linearreg_preds = linear_reg_model.predict(X_test)
#로그변환을 원래 데이터로 복원
submission['count'] = np.exp(linearreg_preds)
submission.to_csv('submission.csv', index=False)
4. 규제가 있는 모델
- Ridge(가중치 감소)
- Lasso(제거 가능)
- ElasticNet(절충형) : alpha라는 규제 강도가 있음
# 모델 생성 및 하이퍼 파라미터 튜닝
from sklearn.linear_model import Ridge
from sklearn.model_selection import GridSearchCV
from sklearn import metrics
#기본 모델
ridge_model = Ridge()
#파라미터 생성
ridge_params = {
'max_iter' : [3000],
'alpha' : [0.1, 1, 2, 3, 4, 10, 30, 100, 200, 300, 400, 800, 900, 1000]
}
#사용자 정의 함수를 평가 지표로 사용
rmsle_scorer = metrics.make_scorer(rmsle, greater_is_better=False)
gridsearch_ridge_model = GridSearchCV(estimator = ridge_model,
param_grid = ridge_params,
scoring = rmsle_scorer,
cv=5)
log_y = np.log(y)
gridsearch_ridge_model.fit(X_train, log_y)
# Ridge
#최적의 모델로 예측
preds = gridsearch_ridge_model.best_estimator_.predict(X_train)
print("릿지 적용한 RMSLE:", rmsle(log_y, preds, True))| 릿지 적용한 RMSLE: 1.020497980747181 |
- 이전 선형 회귀와 별 차이가 없네.. 규제를 줬는데도?
- 그럼 얘는 선형이 아니구먼
- 비선형으로 예측허자
결론
규제를 추가해도 별 다른 성능 현상이 없으면 대부분의 경우 비선형이기 때문에 규제로 성능 향상을 꾀하기는 어려운 상황
5. 부스팅 모델
RandomForest, AdaBoosting, GradientBoosting, HistGradientBoosting, XGBM, LightGBM, CatBoost
pip install xgboost
pip install lightGBM
pip install catboostfrom sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.ensemble import HistGradientBoostingRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
from catboost import CatBoostRegressor
#인스턴스 생성
rf_reg = RandomForestRegressor()
gbm_reg = GradientBoostingRegressor(n_estimators=500)
hgbm_reg = HistGradientBoostingRegressor(max_iter=500)
xgb_reg = XGBRegressor(n_estimators=500)
lgbm_reg = LGBMRegressor(n_estimators=500)
catgbm_reg = CatBoostRegressor(iterations=500)
#파라미터 값 생성
params = {'random_state':[42], 'n_estimators': [100, 300, 500, 700]}
hgbm_params = {'random_state':[42], 'max_iter': [100, 300, 500, 700]}
catgbm_params = {'random_state':[42], 'iterations': [100, 300, 500, 700]}
#타겟 값 생성
log_y = np.log(y)
#랜덤 포레스트
gridsearch_random_forest_model = GridSearchCV(estimator=rf_reg,
param_grid=params,
scoring=rmsle_scorer,
cv=5)
gridsearch_random_forest_model.fit(X_train, log_y)
preds = gridsearch_random_forest_model.best_estimators_.predict(X_train)
print("랜덤 포레스트의 RMSLE 값:", rmsle(log_y, preds, True))| 랜덤 포레스트의 RMSLE 값: 0.11124607292494956 |
#XGB
gridsearch_xgb_model = GridSearchCV(estimator=xgb_reg,
param_grid=params,
scoring=rmsle_scorer,
cv=5)
gridsearch_xgb_model.fit(X_train.values, log_y.values)
preds = gridsearch_xgb_model.best_estimator_.predict(X_train.values)
print("XGB의 RMSLE 값:", rmsle(log_y, preds, True))- XBG는 데이터프레임을 사용할 수 없다. numpy의 ndarray만 가능
| XGB의 RMSLE 값: 0.19626309218676358 |
#GBM
gridsearch_gbm_model = GridSearchCV(estimator=gbm_reg,
param_grid=params,
scoring=rmsle_scorer,
cv=5)
gridsearch_gbm_model.fit(X_train, log_y)
preds = gridsearch_gbm_model.best_estimator_.predict(X_train)
print("GBM의 RMSLE 값:", rmsle(log_y, preds, True))| GBM의 RMSLE 값: 0.27007893677151384 |
#LGBM
gridsearch_lgbm_model = GridSearchCV(estimator=lgbm_reg,
param_grid=params,
scoring=rmsle_scorer,
cv=5)
gridsearch_lgbm_model.fit(X_train.values, log_y.values)
preds = gridsearch_lgbm_model.best_estimator_.predict(X_train.values)
print("LGBM의 RMSLE 값:", rmsle(log_y, preds, True))| LGBM의 RMSLE 값: 0.25772337517896476 |
# HistGradientBoosting
- 피처를 255개 구간으로 나누어 학습
gridsearch_hgbm_model = GridSearchCV(estimator=hgbm_reg,
param_grid=hgbm_params,
scoring=rmsle_scorer,
cv=5)
gridsearch_hgbm_model.fit(X_train.values, log_y.values)
preds = gridsearch_hgbm_model.best_estimator_.predict(X_train.values)
print("Hist의 RMSLE 값:", rmsle(log_y, preds, True))| Hist의 RMSLE 값: 0.23245216702971983 |
#CatBoost
gridsearch_catgbm_model = GridSearchCV(estimator=catgbm_reg,
param_grid=catgbm_params,
scoring=rmsle_scorer,
cv=5)
gridsearch_catgbm_model.fit(X_train.values, log_y.values)
preds = gridsearch_catgbm_model.best_estimator_.predict(X_train.values)
print("Catboost의 RMSLE 값:", rmsle(log_y, preds, True)) ... Catboost의 RMSLE 값: 0.23012371614685823 |
- 부스팅 사용 결과
- RF: 0.111
- GBM: 0.27
- XGBM: 0.196
- LGBM: 0.257
- Hist: 0.232
- Cat: 0.230
* 시간 때문에 n_estimators의 값만 하이퍼 파라미터 튜닝을 했는데 학습률이나 max_depth 등의 매개변수도 파라미터 튜닝을 하게 되면 더 좋은 성능을 기대할 수 있다.
* 필요하다면 피처 엔지니어링도 수행해보는 것이 좋다.
result = gridsearch_random_forest_model.best_estimator_.predict(X_test)
#로그변환을 원래 데이터로 복원
submission['count'] = np.exp(result)
submission.to_csv('submission.csv', index=False)

'Python' 카테고리의 다른 글
| [Python] 분류 (0) | 2024.03.07 |
|---|---|
| [Python] 머신러닝 (0) | 2024.03.07 |
| [Python] 벡터 연산에서 기억할 부분 (0) | 2024.02.27 |
| [Python] 샘플링 _ 표본 추출 (1) | 2024.02.26 |
| [Python] 확률 분포 모형 (1) | 2024.02.26 |