
1. 개요
- 무작위로 선택된 수천명의 사람에게 복잡한 질문을 하고 대답을 모은다고 가정하면 이렇게 모은 답이 전문가의 답보다 나을 가능성이 높은데, 이를 대중의 지혜 혹은 집단지성이라고 한다.
- 하나의 좋은 예측기를 이용하는 것보다 일반적인 여러 예측기를 이용해서 예측을 하면 더 좋은 결과를 만들 수 있다는 것을 앙상블 기법이라고 한다.
- Decision Tree는 전체 데이터를 이용해서 하나의 트리를 생성해서 결과를 예측하지만, Random Forest는 훈련 세트로부터 무작위로 각기 다른 서브 세트를 이용해서 여러개의 트리 분류기를 만들고 예측할 때 가장 많은 선택을 받은 클래스나 평균 이용
- 머신러닝에서 가장 좋은 모델은 앙상블을 이용하는 모델
2. 투표기반 분류기
- 분류기 여러개를 가지고 훈련을 한 후 투표를 해서 다수결의 원칙으로 분류하는 방식
- law of large numbers(큰 수의 법칙)
- 동전을 던졌을 때 앞면이 나올 확률이 51%이고 뒷면이 나올 확률이 49%인 경우 일반적으로 1000번을 던진다면 앞면이 510번 뒷면이 490번 나올 것이다.
- 이런 경우 앞면이 다수가 될 가능성은 확률적으로 75% 정도 된다.
- 이를 10000번으로 확장하면 확률은 97%가 된다.
- 앙상블 기법을 이용할 때 동일한 알고리즘을 사용하는 분류기를 여러 개 만들어도 되고 서로 다른 알고리즘의 분류기를 여러개 만들어도 됨
- 동일한 알고리즘을 사용하는 분류기를 여러개 만들어서 사용할 때는 훈련 데이터가 달라야 한다.
2-1) 직접 투표 방식
- 분류를 할 때 실제 분류된 클래스를 가지고 선정
2-2) 간접 투표 방식
- 분류를 할 때 클래스 별 확률 가지고 선정
- 이 방식을 사용할 때는 모든 분류기가 predict_proba 함수 사용 가능
- 이 방식의 성능이 직접 투표 방식보다 높음
2-3) API
- sklearn.ensemble.VotingClassifier 클래스
- 매개변수로는 estimators 가 있는데 여기에 list로 이름과 분류기를 튜플의 형태로 묶어서 전달하고 voting 매개변수에 hard와 soft를 설정해서 직접 투표 방식인지 간접 투표 방식인지 설정
2-4) 투표 기반 분류기 (클래스를 가지고 선정)
# 직접 투표 방식
# 데이터 생성
from sklearn.model_selection import train_test_split #훈련 데이터와 테스트 데이터 분할
from sklearn.datasets import make_moons #샘플 데이터 생성
X, y = make_moons(n_samples=500, noise=0.30, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)#개별 분류기
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
#모델 생성 및 훈련
log_clf = LogisticRegression(solver="lbfgs", random_state=42)
rnd_clf = RandomForestClassifier(n_estimators=100, random_state=42)
svm_clf = SVC(gamma="scale", random_state=42)
#직접 투표 기반 분류기
from sklearn.ensemble import VotingClassifier
voting_clf = VotingClassifier(
estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)],
voting='hard')
#평가 지표 확인
from sklearn.metrics import accuracy_score
for clf in (log_clf, rnd_clf, svm_clf, voting_clf):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__, accuracy_score(y_test, y_pred))| LogisticRegression 0.864 RandomForestClassifier 0.896 SVC 0.896 VotingClassifier 0.912 |
# 간접 투표 방식
- 확률을 가지고 분류할 때는 모든 예측기가 predict_proba()를 호출할 수 있어야 한다.
- SVM은 기본적으로 predict_proba()를 가지고는 있지만 사용을 못한다.
- 인스턴스를 만들 때 probability=True를 추가해 주어야 확률을 계산한다.
# log_clf = LogisticRegression(solver="lbfgs", random_state=42)
# rnd_clf = RandomForestClassifier(n_estimators=100, random_state=42)
svm_clf = SVC(gamma="scale", probability=True, random_state=42)
voting_clf = VotingClassifier(
estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)],
voting='soft')
from sklearn.metrics import accuracy_score
for clf in (log_clf, rnd_clf, svm_clf, voting_clf):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__, accuracy_score(y_test, y_pred))| LogisticRegression 0.864 RandomForestClassifier 0.896 SVC 0.896 VotingClassifier 0.92 |
- 성능 조금 더 향상
직접 간접
log_clf 2 (0.49, 0.51)
svm_clf 2 (0.49, 0.51)
rnd_clf 1 (0.60, 0.40)
간접 투표 기반이 더 효율이 좋다.
100%는 아닐테니까 오류가 발생하고, 다른 모델에서 공통으로 발생할 가능성은 크지 않으니까 여러개를 돌리면 효율이 좋아질 것이라는게 투표기반 모델의 가정.
2-5) 배깅과 페이스팅
- 동일한 알고리즘을 사용하고 훈련 세트에 서브 세트를 무작위로 구성해서 예측기를 각기 다르게 학습시키는 것
- bagging(bootstrap aggregating): 훈련 세트에서 중복을 허용하고 샘플링하는 방식
- pasting: 훈련 세트에서 중복을 허용하지 않고 샘플링하는 방식
- 하나의 샘플링 데이터는 여러개의 예측기에 사용 가능한데
bagging은 하나의 예측기에 동일한 샘플이 포함될 수 있다.
pasting은 하나의 예측기 안에는 동일한 샘플이 포함될 수 없다. - 모든 예측기가 훈련을 마치면 모든 예측을 모아서 새로운 샘플에 대한 예측을 생성하는데, 이때 수집 함수는 분류일 때 최빈값이고 회귀일 때 평균을 계산
- 개별 예측기는 원본 데이터 전체로 훈련한 것보다 편향이 심하지만 수집 함수를 통과하면 편향과 분산이 모두 감소
- 예측기들은 동시에 다른 CPU 코어나 컴퓨터에서 병렬로 학습 가능
- API: BaggingClassifier
- 기본적으로 bagging을 사용. bootstrap 매개변수를 False로 설정하면 페이스팅 수행
- 샘플이 많으면 페이스팅 사용, 샘플의 개수가 적으면 bagging 사용
- n_jobs 매개변수: sklearn이 훈련과 예측에 사용할 CPU 코어 수를 설정 (-1을 설정하면 모든 코어 사용)
- n_estimators 매개변수: 예측기의 개수 설정
- max_sample 매개변수: 샘플의 최대 개수를 지정
- predict_proba 함수를 가진 경우에는 분류에서 간접 투표 방식 사용 가능
# DecisionTree와 DecisionTree의 Bagging 정확도 확인
- 하나가 나은가 여러개가 나은가
- 전체 데이터를 하나의 훈련데이터로
- 전체 데이터를 쪼개서 트리를 여러개로
from sklearn.metrics import accuracy_scorefrom sklearn.tree import DecisionTreeClassifier
tree_clf = DecisionTreeClassifier(random_state=42)
tree_clf.fit(X_train, y_train)
y_pred_tree = tree_clf.predict(X_test)
print(accuracy_score(y_test, y_pred_tree))| 0.856 #정확도 |
from sklearn.ensemble import BaggingClassifier
bag_clf = BaggingClassifier(
DecisionTreeClassifier(), n_estimators=500, #결정 트리 500개 생성
max_samples=100, bootstrap=True, random_state=42) #각 트리의 샘플 데이터 수 최대 100개, 복원 추출
bag_clf.fit(X_train, y_train)
y_pred = bag_clf.predict(X_test)
from sklearn.metrics import accuracy_score
print(accuracy_score(y_test, y_pred))| 0.904 #정확도 |
- 앙상블의 예측이 결정 트리 하나의 예측보다 일반화가 잘 됨
- 앙상블은 비슷한 편향을 가지지만 더 작은 분산을 만듦
- 부트스트래핑은 각 예측기가 학습하는 서브 세트에 다양성을 증가시키므로 배깅이 페이스팅보다 편향이 조금 더 높지만 다양성을 추가하게 되면 예측기들의 상관관계를 줄이므로 앙상블의 분산을 감소
- 일반적으로는 배깅이 페이스팅보다 더 좋은 성능을 나타내지만 되도록이면 교차검증으로 모두 평가하는게 좋다.
- oob 평가
- 배깅에서 어떤 샘플은 한 예측기를 위해서 여러번 샘플링 되고, 어떤 데이터는 전혀 선택되지 않을 수 있다.
- 전체 데이터에서 63% 정도만 사용된다.
- 선택되지 않은 37%를 oob(out-of-bag) 샘플이라고 한다.
- 예측기마다 데이터가 다르다.
- 별도로 테스트 데이터 생성 없이 훈련에 사용하지 않은 37%의 데이터를 이용해서 검증 작업을 수행할 수 있다.
- 앙상블의 평가는 각 예측기의 oob 평가를 평균해서 얻는다.
- BaggingClassifier를 만들 때 oob_score = True로 설정하면 훈련이 끝난 후 자동으로 oob 평가 수행
- 그 결과를 oob_score_ 에 저장
bag_clf = BaggingClassifier(
DecisionTreeClassifier(), n_estimators=500, max_samples=100,
bootstrap=True, oob_score=True, random_state=42)
bag_clf.fit(X_train, y_train)
bag_clf.oob_score_| 0.9253333333333333 |
- BaggingClassifier는 특성 샘플링도 지원
- max_features, bootstrap_features라는 매개변수 이용해서 특성 샘플링 지원
- 최대 사용하는 피처의 개수와 피처의 중복 허용 여부를 설정
- 각 예측기는 무작위로 선택한 입력 특성의 일부분으로 훈련된다.
- 이미지와 같은 고차원의 데이터 세트에서 이용
- 훈련 특성과 샘플을 모두 샘플링하는 것을 Random Patches Method라고 한다.
- 샘플을 모두 사용하고 특성만 샘플링하는 것은 Random Subspaces Method라고 한다.
- 특성 샘플링을 하게 되면 더 다양한 예측기가 만들어지므로 편향을 늘리는 대신 분산을 낮춘다.
3. RandomForest
- 같은 알고리즘으로 여러 개의 분류기를 만들어서 보팅으로 최종 결정하는 배깅의 대표적인 알고리즘
- 알고리즘은 DecisionTree를 이용
- bootstrap 샘플을 생성해서 샘플 데이터 각각에 결정 트리를 적용한 뒤 학습 결과를 취합하는 방식으로 작동
- 각각의 DecisionTree들은 전체 특성 중 일부만 학습
- random_state 값에 따라 예측이 서로 다른 모델이 만들어지는 경우가 있는데 트리의 개수를 늘리면 변동이 적어진다.
- 각 트리가 별개로 학습되므로 n_jobs를 이용해서 동시에 학습하도록 할 수 있다.
3-1) 장점
- 단일 트리의 단점 보완
- 매개변수 튜닝을 하지 않아도 잘 작동하고 데이터의 스케일을 맞출 필요가 없다.
- 매우 큰 데이터 세트에도 잘 작동
- 여러 개의 CPU 코어를 사용하는 것이 가능
3-2) 단점
- 대량의 데이터에서 수행하면 시간은 많이 걸린다.
- 차원이 매우 높고 (특성의 개수가 많음) 희소한 데이터(유사한 데이터가 별로 없는) 일수록 잘 작동하지 않는다.
- 이런 경우 선형 모델을 사용하는 것이 적합
- 희소한 데이터는 리프 노드에 있는 샘플의 개수가 적은 경우
3-3) 배깅과 랜덤 포레스트 비교
- 랜덤 포레스트는 Decision Tree의 배깅
- 배깅에서 부트 스트래핑을 사용하고 특성 샘플링을 이용하는 것이 랜덤 포레스트
- 부트 스트래핑은 하나의 훈련 세트에서 일부분의 데이터를 추출하는데 복원 추출 이용해서 수행
- 특성 샘플링은 비율을 설정해서 특성을 전부 이용하지 않고 일부분만을 이용해서 학습하는 방식
- 랜덤 포레스트에서는 특성의 비율을 기본적으로 제곱근만큼 사용
#배깅을 이용한 random forest 만들기
bag_clf = BaggingClassifier(
DecisionTreeClassifier(max_features="sqrt", max_leaf_nodes=16),
n_estimators=500, random_state=42)
bag_clf.fit(X_train, y_train)
y_pred = bag_clf.predict(X_test)#random forest 분류기
from sklearn.ensemble import RandomForestClassifier
rnd_clf = RandomForestClassifier(n_estimators=500, max_leaf_nodes=16, random_state=42)
rnd_clf.fit(X_train, y_train)
y_pred_rf = rnd_clf.predict(X_test)print(np.sum(y_pred == y_pred_rf) / len(y_pred))| 1.0 |
- 2개 모두 일치하면 1.0
- RandomForest 알고리즘은 트리의 노드를 분할할 때 전체 특성 중에서 최선의 특성을 찾는 것이 아니라 무작위로 선택한 특성 후보 중에서 최적의 특성을 찾는 식으로 무작위성 주입
- 이러한 방식은 트리의 다양성을 높여서 편향을 손해보는 대신에 분산을 낮추는 방식으로 더 좋은 모델을 만들어간다.
3-4) 특성 중요도
- 트리 모델은 특성의 상대적 중요도를 측정하기 쉬움
- sklearn은 어떤 특성을 사용한 노드가 평균적으로 불순도를 얼마나 감소시켰는지 확인해서 특성의 중요도 판단
- 가중치의 평균이며 노드의 가중치는 연관된 훈련 샘플의 수와 같음
- 훈련 샘플의 수를 전체 합이 1이 되도록 결과값을 정규화한 후 feature_importances_에 저장
from sklearn.datasets import load_iris
iris = load_iris()
#data라는 속성에 피처 4가지 있음
#target이라는 속성의 꽃의 종류에 해당하는 범주형 데이터 3가지
#featre_names 속성에 피처 이름이 저장되어 있고 class_names에 클래스 이름 저장
rnd_clf = RandomForestClassifier(n_estimators=500, random_state=42)
rnd_clf.fit(iris["data"], iris["target"])
for name, score in zip(iris["feature_names"], rnd_clf.feature_importances_):
print(name, score)| sepal length (cm) 0.11249225099876378 sepal width (cm) 0.02311928828251033 petal length (cm) 0.4410304643639577 petal width (cm) 0.42335799635476823 |
- 이미지에서 특성의 중요도 확인해보면 이미지의 어느 부분이 다르게 보이는지 확인 가능
- MNIST 데이터에서 분류할 때 가장 크게 다른 부분은 가운데 부분
- 특성의 중요도를 파악한 후 전체 피처를 전부 사용하지 않고 일부분만 사용해도 거의 동일한 정확도를 만들어낼 수 있다.
#특성 중요도 시각화 - MNIST
from sklearn.datasets import fetch_openml
#28*28 이미지 가져오기
mnist = fetch_openml('mnist_784', version=1) # 28*28=784, 피처의 개수
mnist.target = mnist.target.astype(np.uint8) #정수변환
#랜덤포레스트 분류기
rnd_clf = RandomForestClassifier(n_estimators=100, random_state=42)
rnd_clf.fit(mnist["data"], mnist["target"])
#중요도를 시각화 하기 위한 함수
def plot_digit(data):
image = data.reshape(28, 28)
plt.imshow(image, cmap = mpl.cm.hot,
interpolation="nearest")
plt.axis("off")
plot_digit(rnd_clf.feature_importances_)
cbar = plt.colorbar(ticks=[rnd_clf.feature_importances_.min(), rnd_clf.feature_importances_.max()])
cbar.ax.set_yticklabels(['Not important', 'Very important'])
save_fig("mnist_feature_importance_plot")
plt.show() |
- 이미지의 외곽 부분은 분류에 미치는 효과가 거의 없고 중앙 부분의 데이터가 이미지 분류에 영향을 많이 주므로 이 이미지는 가운데 부분만 잘라서 학습을 해도 무방
- 이런 경우 이미지를 자르면 피처의 개수가 줄어들기 때문에 나중에 학습할 때 학습 시간이 줄어들고 예측할 때 일반화 가능성이 높아진다.
3-5) 하이퍼 파라미터 튜닝
- RandomForest는 DecisionTree처럼 하이퍼 파라미터가 다양하다.
- GridSearchCV나 RandomSearchCV를 이용해서 최적의 파라미터를 찾는 작업이 중요
- 샘플의 개수가 많거나 피처의 개수가 많으면 시간이 오래 걸린다.
- 따라서 n_jobs를 -1로 설정해주는 것이 좋다.
# 하이퍼 파라미터 튜닝을 위한 파라미터 생성
- 기본은 dictionary(문자열 - 하이퍼 파라미터 이름과 리스트 - 값들로 구성)
- dictionary 내부의 list들은 전부 곱한 만큼의 조합
- 이러한 dictionary들을 list로 묶으면 별개로 동작
# GridSearchCV를 이용해 랜덤 포레스트의 하이퍼 파라미터를 튜닝
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators':[100, 200, 300],
'max_depth' : [4, 6, 8, 10],
'min_samples_leaf' : [4, 6, 10],
'min_samples_split' : [8, 16, 20]
}
# RandomForestClassifier 모델 생성
rf_clf = RandomForestClassifier(random_state=42, n_jobs=-1)
#GridSearchCV 인스턴스 생성
grid_cv = GridSearchCV(rf_clf , param_grid=params , cv=3, n_jobs=-1 )
grid_cv.fit(X_train , y_train)
print('최적 하이퍼 파라미터:\n', grid_cv.best_params_)
rn_clf = grid_cv.best_estimator_
print('최적 분류기:\n', rn_clf)| 최적 하이퍼 파라미터: {'max_depth': 6, 'min_samples_leaf': 4, 'min_samples_split': 8, 'n_estimators': 100} 최적 분류기: RandomForestClassifier(max_depth=6, min_samples_leaf=4, min_samples_split=8, n_jobs=-1, random_state=42) |
3-6) Extra Tree
- RandomForest에서는 트리를 만들 때 무작위로 특성의 서브 세트를 만들어서 분할에 이용하는데
분할을 하기 위해서 어떤 특성을 이용해서 분할하는 것이 효과적인지 판단하는 작업을 거치게 된다.
- 오래걸림
- 최적의 특성을 찾는 것이 아니고 일단 아무 특성이나 선택해서 분할하고 그 중에서 최상의 분할을 선택하는 방식의 트리
- 무작위성을 추가하는 방식
- RandomForest에 비해서 훈련 속도가 빠름
- 성능은 어떤 것이 좋을지 알 수 없기 때문에 모델을 만들어서 비교해야 한다.
- API: sklearn.ExtraTreesClaassifier
- 사용법은 RandomForest와 동일
from sklearn.ensemble import ExtraTreesClassifier
iris = load_iris()
rnd_clf = RandomForestClassifier(n_estimators=500, random_state=42)
rnd_clf.fit(iris["data"], iris["target"])
for name, score in zip(iris["feature_names"], rnd_clf.feature_importances_):
print(name, score)| sepal length (cm) 0.11249225099876375 sepal width (cm) 0.02311928828251033 petal length (cm) 0.4410304643639577 petal width (cm) 0.4233579963547682 |
4. Boosting
- 원래 이름은 hypothesis boosting
- 약한 학습기를 여러개 연결해서 강한 학습기를 만드는 앙상블 방법
- Bagging이나 Pasting은 여러 개의 학습기를 가지고 예측한 후 그 결과를 합산해서 예측
- 앞의 모델을 보완해 나가면서 예측기를 학습
- 종류는 여러가지
4-1) Ada Boost
- 이전 모델이 과소 적합했던 훈련 샘플의 가중치를 더 높이는 것으로 이 방식을 이용하면 새로 만들어진 예측기는 학습하기 어려운 샘플에 점점 더 맞춰지게 된다.
- 먼저 알고리즘의 기반이 되는 첫번째 분류기를 훈련 세트로 훈련시키고 예측을 만들고 그 다음에 알고리즘이 잘못 분류한 훈련 샘플의 가중치를 상대적으로 높인다.두번째 분류기는 업데이트된 가중치를 사용해서 훈련 세트에서 다시 훈련하고 다시 예측을 만들고 그 다음에 가중치를 업데이트 하는 방식
- 투표 방식이 아닌 것임
 |  |
- API: sklearn. AdaBoostClassifier
- 기반 알고리즘이 predict_proba 함수를 제공한다면 클래스 확률을 기반으로 분류가 가능
- algorithm 매개변수에 SAMME.R 값 설정
- 확률을 이용하는 방식이 예측 값을 이용하는 방식보다 성능이 우수할 가능성이 높다.
# moons 데이터에 AdaBoost 적용
X, y = make_moons(n_samples=500, noise=0.30, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
from sklearn.ensemble import AdaBoostClassifier
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=1), n_estimators=200,
algorithm="SAMME.R", learning_rate=0.5, random_state=42)
ada_clf.fit(X_train, y_train)
plot_decision_boundary(ada_clf, X, y) |
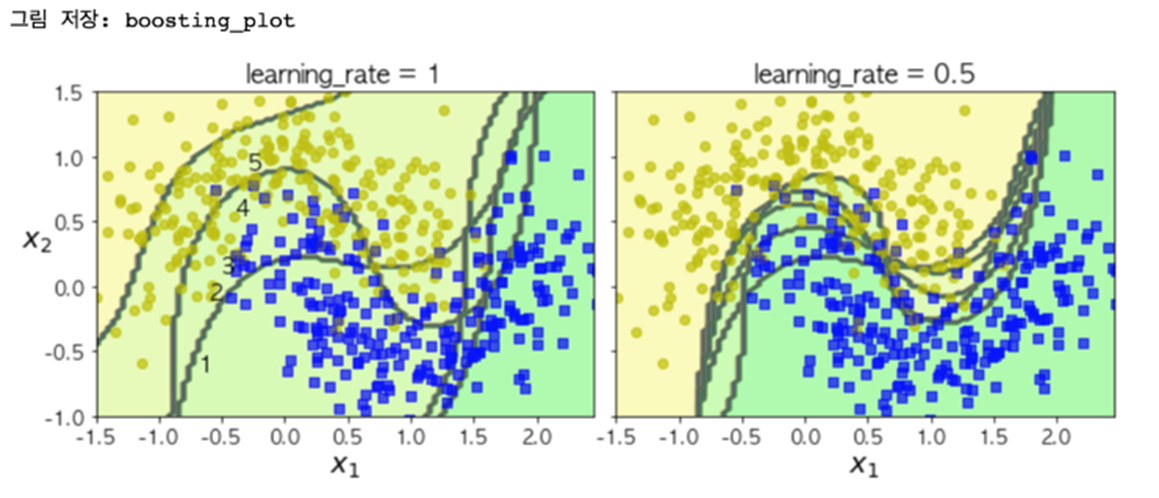
- learning_rate(학습률)는 훈련을 할 때 스텝의 크기로 이 값이 크면 최적화에 실패할 가능성이 높아지고, 낮으면 최적화에는 성공할 가능성이 높지만 훈련 속도가 느려지고 과대적합 가능성이 높아진다.
- 따라서 학습률은 그리드서치로 최적값을 찾을 필요가 있다.
4-2) Gradient Boosting
- 여러 개의 결정 트리를 묶어서 강력한 모델을 만드는 앙상블 기법
- 회귀와 분류 모두 가능
- RandomForest도 여러 개의 결정 트리를 이용하는 것은 같지만, Gradient Boosting은 이전 트리의 오차를 보완하는 방식으로 순차적으로 트리 생성
- 무작위성이 없다. 이전에 오분류한 샘플에 가중치를 부여한다. 대신 강력한 사전 가지 치기를 사용한다.
- 보통 1~5 정도 깊이의 트리를 사용하기 때문에 메모리를 적게 사용하고 에측도 빠르다.
- RandomForest 보다 매개변수 설정에 조금 더 민감하지만 잘 조정하면 더 높은 정확도를 제공한다.
- AdaBoost 가중치 업데이트를 경사 하강법을 이용해서 조정한다.
- 예측 속도는 빠르지만 훈련 속도(수행 시간)는 느리고 하이퍼 파라미터 튜닝도 좀더 어렵다.
랜덤 포레스트는 각각 훈련하기 때문에 병렬이 된다. n_jobs여럿 지정 가능.
그런데 부스팅은 순차적으로 가야하기 때문에 병렬이 불가하다.
GB의 장점은 메모리가 적고 예측도 빠르고 성능이 좋지만 훈련 시간이 문제임.
- API: sklean. GradientBoostingClassifier
from sklearn.ensemble import GradientBoostingClassifier
import time
# GBM 수행 시간 측정을 위함. 시작 시간 설정.
start_time = time.time()
gb_clf = GradientBoostingClassifier(random_state=0)
gb_clf.fit(X_train , y_train)
gb_pred = gb_clf.predict(X_test)
gb_accuracy = accuracy_score(y_test, gb_pred)
print('GBM 정확도: {0:.4f}'.format(gb_accuracy))
print("GBM 수행 시간: {0:.1f} 초 ".format(time.time() - start_time))| GBM 정확도: 0.8880 GBM 수행 시간: 0.2 초 |
- 하이퍼 파라미터
- max_depth: 트리의 깊이
- max_features: 사용하는 피처의 비율
- n_estimators: 학습기의 개수로 기본은 100
- learning_rate: 학습률. 기본은 0.1이며 0~1사이로 설정 가능
- subsample: 샘플링 비율. 기본 값은 1인데 과대적합 가능성이 보이면 숫자를 낮추면 된다.기본은 모든 데이터로 학습
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators':[100, 500],
'learning_rate' : [ 0.05, 0.1]
}
grid_cv = GridSearchCV(gb_clf , param_grid=params , cv=2 ,verbose=1)
grid_cv.fit(X_train , y_train)
print('최적 하이퍼 파라미터:\n', grid_cv.best_params_)
print('최고 예측 정확도: {0:.4f}'.format(grid_cv.best_score_))- cv의 숫자는 교차검증에 사용할 fold의 개수로 실제 사용할 때는 조금 더 큰값 사용
- verbose는 훈련 가정에서 로그 출력 여부
| Fitting 2 folds for each of 4 candidates, totalling 8 fits 최적 하이퍼 파라미터: {'learning_rate': 0.05, 'n_estimators': 100} 최고 예측 정확도: 0.8960 |
- 타이타닉
- deck 열에는 결측치가 많다.
embarked와 embark_town은 동일한 의미를 가진 컬럼
# 전처리
# load_dataset 함수를 사용하여 데이터프레임으로 변환
df = sns.load_dataset('titanic')
# IPython 디스플레이 설정 - 출력할 열의 개수 한도 늘리기
pd.set_option('display.max_columns', 15)
# NaN값이 많은 deck 열을 삭제, embarked와 내용이 겹치는 embark_town 열을 삭제
rdf = df.drop(['deck', 'embark_town'], axis=1)
# age 열에 나이 데이터가 없는 모든 행을 삭제 - age 열(891개 중 177개의 NaN 값)
rdf = rdf.dropna(subset=['age'], how='any', axis=0)
# embarked 열의 NaN값을 승선도시 중에서 최빈값으로 치환하기
# 각 범주의 개수를 구한 후 가장 큰 값의 인덱스를 가져오기
most_freq = rdf['embarked'].value_counts(dropna=True).idxmax()
# 치환
rdf['embarked'].fillna(most_freq, inplace=True) |
#피처 선택
# 타겟은 survived
ndf = rdf[['survived', 'pclass', 'sex', 'age', 'sibsp', 'parch', 'embarked']]
# 원핫인코딩 - 범주형 데이터를 모형이 인식할 수 있도록 숫자형으로 변환
onehot_sex = pd.get_dummies(ndf['sex'])
ndf = pd.concat([ndf, onehot_sex], axis=1)
onehot_embarked = pd.get_dummies(ndf['embarked'], prefix='town')
ndf = pd.concat([ndf, onehot_embarked], axis=1)
ndf.drop(['sex', 'embarked'], axis=1, inplace=True) |
# 속성(변수) 선택
X=ndf[['pclass', 'age', 'sibsp', 'parch', 'female', 'male',
'town_C', 'town_Q', 'town_S']] #독립 변수 X
# X=ndf.drop(['survived'], axis=1)
y=ndf['survived'] #종속 변수 Y
#피처의 스케일 확인
X.describe() #숫자 컬럼의 기술 통계량 확인 |
- 숫자 컬럼의 값들의 범위가 차이가 많이 나면 scaling을 수행하는 것이 좋다.
# 스케일링
# 설명 변수 데이터를 정규화(normalization)
from sklearn import preprocessing
X = preprocessing.StandardScaler().fit(X).transform(X) |
# 훈련
# train data 와 test data로 구분(7:3 비율)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=10)
# 평가지표
gbrt = GradientBoostingClassifier(random_state=0)
gbrt.fit(X_train, y_train)
print("훈련 세트 정확도: {:.3f}".format(gbrt.score(X_train, y_train)))
print("테스트 세트 정확도: {:.3f}".format(gbrt.score(X_test, y_test)))| 훈련 세트 정확도: 0.894 테스트 세트 정확도: 0.795 |
- 과대적합 발생: 훈련 데이터는 높고 테스트는 오히려 떨어졌다.
- n_estimators를 조정한다. 100개 정도가 적당
- max_depth도 높아지면 과대적합 가능
# 하이퍼 파라미터 변경
gbrt = GradientBoostingClassifier(n_estimators=100, max_depth=1, random_state=42)
gbrt.fit(X_train, y_train)
print("훈련 세트 정확도: {:.3f}".format(gbrt.score(X_train, y_train)))
print("테스트 세트 정확도: {:.3f}".format(gbrt.score(X_test, y_test)))| 훈련 세트 정확도: 0.810 테스트 세트 정확도: 0.805 |
# 피처의 중요도 파악
# 특성 중요도 확인
print('pclass', 'age', 'sibsp', 'parch', 'female', 'male',
'town_C', 'town_Q', 'town_S')
print(gbrt.feature_importances_)| pclass age sibsp parch female male town_C town_Q town_S [0.22911763 0.11503979 0.02325801 0.01771038 0.2245367 0.38466583 0.00567166 0. 0. ] |
#별 연관이 없는 애들은 빼고 다시 훈련
X = ndf.drop(['survived', 'town_C', 'town_Q', 'town_S'], axis=1)
X = preprocessing.StandardScaler().fit(X).transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=10)
gbrt = GradientBoostingClassifier(n_estimators=100, max_depth=1, random_state=42)
gbrt.fit(X_train, y_train)
print("훈련 세트 정확도: {:.3f}".format(gbrt.score(X_train, y_train)))
print("테스트 세트 정확도: {:.3f}".format(gbrt.score(X_test, y_test)))| 훈련 세트 정확도: 0.816 테스트 세트 정확도: 0.805 |
- 특징
- 일반적으로 성능이 우수하지만 처음부터 이 모델을 사용하는 것을 권장하지는 않는데 이유는 훈련 시간이 길기 때문
- 랜덤 포레스트나 선형 모델을 이용해서 훈련하고 평가한 후 성능이 나쁘거나 경진대회에서 마지막 성능까지 뽑아내고자 할 때 이용
- 트리 모델이므로 희소한 고차원 데이터에는 잘 작동하지 않음
- 가장 중요한 파라미터는 n_estimators, learning_rate, max_depth
gbrt = GradientBoostingClassifier(n_estimators=100, learning_rate=0.2, max_depth=2, random_state=42)
gbrt.fit(X_train, y_train)
print("훈련 세트 정확도: {:.3f}".format(gbrt.score(X_train, y_train)))
print("테스트 세트 정확도: {:.3f}".format(gbrt.score(X_test, y_test)))| 훈련 세트 정확도: 0.880 테스트 세트 정확도: 0.823 |
- 회귀에 적용
- 분류에서는 잘못 분류된 데이터를 다음 학습기에서 다시 예측하는 형태로 구현
- 회귀에서는 첫번째 결정 트리 모델을 가지고 학습한 후 잔차를 구하여 다음 결정 트리 모델이 잔차를 타겟으로 해서 다시 학습을 수행하고 잔차를 구한 후 이 결과를 가지고 다음 결정 트리 모델이 훈련을 하는 방식으로 구현
- 예측값은 모든 결정 트리 모델의 예측을 더하면 됨
- GradientBoostingRegressor 제공
#샘플 데이터 생성
np.random.seed(42)
X = np.random.rand(100, 1) - 0.5
y = 3*X[:, 0]**2 + 0.05 * np.random.randn(100)
print(X[0])
print(y[0])| [-0.12545988] 0.05157289874841034 |
#첫번째 트리로 훈련
from sklearn.tree import DecisionTreeRegressor
#의사 결정 나무를 이용한 회귀
tree_reg1 = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg1.fit(X, y)
print(y[0])
print(tree_reg1.predict(X[0].reshape(1, 1)))| 0.05157289874841034 [0.12356613] |
#첫번째 예측기에서 생긴 잔여 오차에 두번째 DecisionTreeRegresssor를 훈련
y2 = y - tree_reg1.predict(X)
#잔차를 타겟으로 훈련
tree_reg2 = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg2.fit(X, y2)
print(tree_reg2.predict(X[0].reshape(1, 1)))| [-0.09039794] |
#두번째 예측기에서 생긴 잔여 오차에 세번째 DecisionTreeRegresssor를 훈련
y3 = y2 - tree_reg2.predict(X)
tree_reg3 = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg3.fit(X, y3)
print(tree_reg3.predict(X[0].reshape(1, 1)))| [0.00704347] |
#이제 세 개의 트리를 포함하는 앙상블 모델이 생겼습니다.
#새로운 샘플에 대한 예측을 만들려면 모든 트리의 예측을 더하면 됩니다.
X_new = np.array([[0.8]])
y_pred = sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2, tree_reg3))
print(y_pred)| [0.75026781] |
#이제 세 개의 트리를 포함하는 앙상블 모델이 생겼습니다.
#새로운 샘플에 대한 예측을 만들려면 모든 트리의 예측을 더하면 됩니다.
X_new = np.array([[0.05]])
y_pred = sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2, tree_reg3))
print(y_pred)| [0.04021166] |
- API 활용
from sklearn.ensemble import GradientBoostingRegressor
gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=100, learning_rate=0.05, random_state=42)
gbrt.fit(X, y)
print(gbrt.predict(X_new))| [0.00710809] |
- 확률적 그라디언트 부스팅
- 훈련 샘플의 비율을 설정하는 것
- subsample 매개변수에 훈련 샘플의 비율 설정
- 편향이 높아지는 대신 분산이 낮아지고 훈련 속도가 빨라진다.
4-3) Histogram-based Gradient Boosting
- sklearn에서 제공하는 다른형태의 Gradient Boosting
- 입력 특성을 구간으로 나누어서 정수로 대체하는 형식
- 구간의 개수는 max_bins 속성으로 설정 가능한데 기본값은 255이고 그 이상의 값은 안됨
- 구간 분할을 사용하면 학습 알고리즘이 평가해야 하는 임계값의 개수가 줄어들게 되고 정수로 작업을 수행하기 때문에 속도가 빠르다.
- 대규모 데이터 셋에서 빠르게 훈련할 때 사용
- API: HistGradientBoostingRegressor, HistGradientBoostingClassifier
- 사용 방법 거의 동일
- 일반 그라디언트 부스팅과의 차이점
- 샘플의 개수가 1000개가 넘으면 자동 조기종료 기능 활성화
- 조기종료 기능은 훈련을 하다가 현재 점수보다 그다지 좋아지지 않으면 훈련 종료
- n_estimators 매개변수 대신에 max_iter로 변경
- 조정할 수 있는 파라미터도 줄어듬
from sklearn.ensemble import HistGradientBoostingClassifier
hgbrt = HistGradientBoostingClassifier(max_iter=100, max_depth=3, random_state=42)
hgbrt.fit(X_train, y_train)
print("훈련 세트 정확도: {:.3f}".format(hgbrt.score(X_train, y_train)))
print("테스트 세트 정확도: {:.3f}".format(hgbrt.score(X_test, y_test)))| 훈련 세트 정확도: 0.957 테스트 세트 정확도: 0.888 |
5. XG Boosting (eXtra Gradient Boosting)
- https://github.com/dmlc/xgboost
- 트리 기반의 앙상블 학습
- 케글 경연 대회에서 상위를 차지한 경우에 이 모델 많이 사용
- 분류에 있어서 다른머신러닝 알고리즘보다 뛰어난 예측 성능
- Gradient Boosting에 기반하지만 느린 훈련속도와 과적합 규제에 대한 부분 보완
- 병렬 학습 가능
- 자체 내장된 교차 검증 수행
- 결측값도 자체 처리
5-1) 하이퍼 파라미터
- 일반 파라미터: 일반적으로 실행 시 스레드의 개수 silent 모드 (로그 출력x) 등의 선택을 위한 파라미터로 기본 값을 거의 변경하지 않음
- 부스터 파라미터: 트리 최적화, 규제 등의 파라미터
- 학습 태스크 파라미터: 학습 수행 시의 객체 함수나 평가를 위한 지표 등을 설정
#설치
pip install xgboost
5-2) 훈련과 검증에 사용하는 데이터
- API: DMatrix
- data 매개변수에 피처, label 매개변수에 타겟 설정
- 위스콘신 유방암 데이터
- X-ray 촬영한 사진을 수치화한 데이터
- 사진을 직접 이용하는게 아니라 사진에서 필요한 데이터를 추출해서 수치화해서 사용하는 경우가 많다.
- 이러한 라벨링 작업에 Open CV를 많이 활용한다.
- 타겟이 0이면 악성(malignant), 1이면 양성(benign)
# 데이터 가져오기
import xgboost as xgb
from xgboost import plot_importance
from sklearn.datasets import load_breast_cancer
dataset = load_breast_cancer()
X_features= dataset.data
y_label = dataset.target
cancer_df = pd.DataFrame(data=X_features, columns=dataset.feature_names)
cancer_df['target']= y_label
cancer_df.head(3) |
#레이블 분포 확인 - 층화 추출이나 오버나 언더샘플링 여부를 판단하기 위해서 수행함
print(dataset.target_names)
print(cancer_df['target'].value_counts())| ['malignant' 'benign'] target 1 357 0 212 Name: count, dtype: int64 |
#훈련 데이터와 테스트 데이터 분리
# 전체 데이터 중 80%는 학습용 데이터, 20%는 테스트용 데이터 추출
X_train, X_test, y_train, y_test=train_test_split(X_features, y_label,
test_size=0.2, random_state=156 )
print(X_train.shape , X_test.shape)| (455, 30) (114, 30) |
#xgboost가 사용할 수 있는 형태로 데이터 변경
dtrain = xgb.DMatrix(data=X_train , label=y_train)
dtest = xgb.DMatrix(data=X_test , label=y_test)
#하이퍼 파라미터 생성
params = { 'max_depth':3,
'eta': 0.1, #학습률
'objective':'binary:logistic', #0하고 1이니까 이진분류
'eval_metric':'logloss' #평가지표
}
num_rounds = 500 #예측횟수
#모델 생성 후 훈련
# train 데이터 셋은 ‘train’ , evaluation(test) 데이터 셋은 ‘eval’ 로 명기합니다.
wlist = [(dtrain,'train'),(dtest,'eval') ]
# 하이퍼 파라미터와 early stopping 파라미터를 train( ) 함수의 파라미터로 전달
xgb_model = xgb.train(params = params , dtrain=dtrain , num_boost_round=num_rounds ,early_stopping_rounds=100, evals=wlist )- early_stopping_rounds - 조기 종료 기능 설정
- 일반 그라디언트 부스팅은 예측기의 개수를 설정하면 무조건 예측기의 개수만큼 훈련 (무조건 500번)
중간에 조기종료를 하려면 매 학습시마다 점수를 가져와서 점수가 더 이상 좋아지지 않으면 종료되도록 알고리즘 구현
 |
- 더이상 해봐야 이거보다 좋아지지 않는다.
# 예측을 수행하면 1로 판정할 확률 리턴
- 예측 값을 출력할 때는 클래스로 변환해서 출력해야 함
# predict( ) 수행 결과값을 10개만 표시, 예측 확률 값으로 표시됨
print(np.round(pred_probs[:10],3)) #소수 셋째짜리까지| [0.904 0.004 0.908 0.267 0.992 1. 1. 0.999 0.994 0. ] |
# 예측 확률이 0.5 보다 크면 1 , 그렇지 않으면 0 으로 예측값 결정하여 List 객체인 preds에 저장
preds = [ 1 if x > 0.5 else 0 for x in pred_probs ]
print('예측값 10개만 표시:',preds[:10])| 예측값 10개만 표시: [1, 0, 1, 0, 1, 1, 1, 1, 1, 0] |
#범주형 평가 지표 출력
- 정확도, 정밀도, 재현율, 정밀도와 재현율의 조화 평균(f1-score), roc_auc
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.metrics import precision_score, recall_score
from sklearn.metrics import f1_score, roc_auc_score
#오차 행렬 출력
confusion = confusion_matrix( y_test, preds)
print('오차행렬:\n', confusion)
#정확도: 전체 데이터에서 맞게 분류한 것의 비율
accuracy = accuracy_score(y_test , preds)
print('정확도:', accuracy)
#정밀도: 검색된 문서들 중 관련있는 문서들의 비율 (True로 판정한 것 중 실제 True인 것의 비율)
precision = precision_score(y_test , preds)
print('정밀도:', precision)
#재현율: 관련된 문서들 중 검색된 비율 (실제 True인 것 중 True로 판정한 것의 비율)
recall = recall_score(y_test , preds)
print('재현율:', recall)
#recall과 precision의 조화 평균 (f1_score)
f1 = f1_score(y_test,preds)
print('f1_score:', f1)
#roc_auc score - area under curve. 그래프 곡선 아래 면적
#1에 가까울수록 좋은 성능
roc_auc = roc_auc_score(y_test, pred_probs)
print('roc_auc:', roc_auc)| 오차행렬: [[59 2] [12 52]] 정확도: 0.888 정밀도: 0.9629629629629629 재현율: 0.8125 f1_score: 0.8813559322033898 roc_auc: 0.9723360655737704 |
# 피처의 중요도 출력
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10, 10))
plot_importance(xgb_model, ax=ax) |
5-3) Light GBM
- XGBoost는 매우 뛰어난 부스팅이지만 여전히 학습 시간이 길다.
- GridSearchCV를 이용해서 하이퍼 파라미터 튜닝을 하다보면 수행 시간이 너무 오래 결러셔 많은 파라미터를 튜닝하기에 어려움을 겪게 된다.
- XGBoost보다 학습에 걸리는 시간이 훨씬 적고 메모리 사용량도 상대적으로 적으면서도 비슷한 성능 발휘
- 10000건 이하의 데이터 세트에 적용하면 과대적합이 발생할 가능성이 높음
- 다른 부스팅 알고리즘은 균형 트리를 만들려고 하는 경향이 있는데 이유는 과대적합을 방지하기 위해서인데 이것 때문에 훈련 시간이 오래 걸림
- Light GBM은 균형 잡히 트리를 만들려고 하지 않고 리프 중심 트리 분할을 수행
- 불균형 트리를 만들어서 사용한다.
- 데이터가 아주 많다면 리프에 배치되는 샘플의 개수도 많아질 가능성이 높기 때문에 과대 적합이 잘 발생하지 않는다.
- 설치
pip install lightgbm
- 4.x 버전이 설치가 된다.
- 조기종료가 콜백의 형태
- 로그 출력 옵션 없어짐
pip install lightgbm ==3.3.2
- 조기 종료가 파라미터 형태
- 로그 출력 옵션 있음
- 하이퍼 파라미터
- xbboost와 거의 유사
- xgboost와 다른 점은 파이썬 래퍼를 사용하면 데이터를 이전처럼 numpy의 ndarray로 지정
- 위스콘신 유방암
from lightgbm import LGBMClassifier
import lightgbm
dataset = load_breast_cancer()
ftr = dataset.data
target = dataset.target
# 전체 데이터 중 80%는 학습용 데이터, 20%는 테스트용 데이터 추출
X_train, X_test, y_train, y_test=train_test_split(ftr, target, test_size=0.2, random_state=156 )
print(X_train.shape, X_test.shape)
# 검증에 사용할 데이터 생성
evals = [(X_test, y_test)]| (455, 30) (114, 30) |
# 모델 생성 훈련
lgbm_wrapper = LGBMClassifier(n_estimators=1000)
lgbm_wrapper.fit(X_train, y_train, early_stopping_rounds=100, eval_metric="logloss",
eval_set=evals)
preds = lgbm_wrapper.predict(X_test)
#검증 이하생략| 오차행렬: [[33 4] [ 1 76]] 정확도: 0.956140350877193 정밀도: 0.95 재현율: 0.987012987012987 f1_score: 0.9681528662420381 roc_auc: 0.995085995085995 |
#피처의 중요도 시각화
# plot_importance( )를 이용하여 feature 중요도 시각화
from lightgbm import plot_importance
fig, ax = plt.subplots(figsize=(10, 12))
plot_importance(lgbm_wrapper, ax=ax) |
6. Stacking
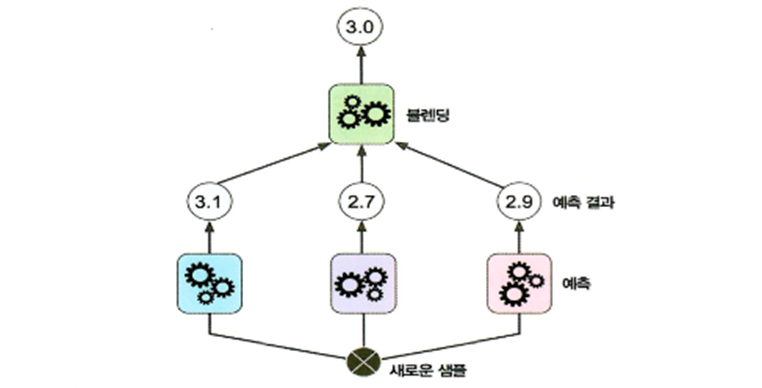
- 부스팅이나 랜덤 포레스트를 예측기의 예측을 취합해서 무언가 동작(투표, 확률, 평균 등)을 수행하는데 예측을 취합하는 모델을 훈련시키려고 하는 방식
- 개별 알고리즘의 예측 결과 데이터 세트를 최종적인 메타 데이터를 만들고 이 데이터를 가지고 별도의 ML 알고리즘으로 최종 학습을 수행하고 테스트 데이터를 기반으로 다시 최종 예측을 수행하는 방식
- 개별 알고리즘의 예측 결과를 가지고 훈련해서 최종 결과를 만들어내는 예측기 Blender 생성
- 블랜더는 홀드 아웃 세트를 이용해서 학습
- 스태킹에서는 두 종류의 모델이 필요한데 하나는 개별적인 기반 모델이고 다른 하나는 기반 모델의 예측 데이터를 학습 데이터로 만들어서 학습하는 최종 메타 모델
- API: sklearn 스태킹 지원 안함. 직접 구현하거나 오픈소스 시용
6-1) 위스콘신 유방암 데이터를 이용해서 스태킹 구현
- 개별 학습기: KNN, RandomForest, AdaBoost, DecisionTree
- 최종 학습기: LogisticRegression
# 데이터 가져오기
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
cancer_data = load_breast_cancer()
X_data = cancer_data.data
y_label = cancer_data.target
X_train , X_test , y_train , y_test = train_test_split(X_data , y_label , test_size=0.2 , random_state=0)
# 예측기 생성
# 개별 ML 모델을 위한 Classifier 생성.
knn_clf = KNeighborsClassifier(n_neighbors=4)
rf_clf = RandomForestClassifier(n_estimators=100, random_state=0)
dt_clf = DecisionTreeClassifier()
ada_clf = AdaBoostClassifier(n_estimators=100)
# 최종 Stacking 모델을 위한 Classifier생성.
lr_final = LogisticRegression(C=10)
# 개별 모델 학습
# 개별 모델들을 학습.
knn_clf.fit(X_train, y_train)
rf_clf.fit(X_train , y_train)
dt_clf.fit(X_train , y_train)
ada_clf.fit(X_train, y_train)
# 개별 학습기 가지고 예측한 후 정확도 확인
# 학습된 개별 모델들이 각자 반환하는 예측 데이터 셋을 생성하고 개별 모델의 정확도 측정.
knn_pred = knn_clf.predict(X_test)
rf_pred = rf_clf.predict(X_test)
dt_pred = dt_clf.predict(X_test)
ada_pred = ada_clf.predict(X_test)
print('KNN 정확도: {0:.4f}'.format(accuracy_score(y_test, knn_pred)))
print('Random Forest 정확도: {0:.4f}'.format(accuracy_score(y_test, rf_pred)))
print('Decision Tree 정확도: {0:.4f}'.format(accuracy_score(y_test, dt_pred)))
print('AdaBoost 정확도: {0:.4f}'.format(accuracy_score(y_test, ada_pred)))| KNN 정확도: 0.9211 랜덤 포레스트 정확도: 0.9649 결정 트리 정확도: 0.9123 에이다부스트 정확도: 0.9561 |
pred = np.array([knn_pred, rf_pred, dt_pred, ada_pred])
print(pred.shape)
# transpose를 이용해 행과 열의 위치 교환. 컬럼 레벨로 각 알고리즘의 예측 결과를 피처로 만듦.
pred = np.transpose(pred)
print(pred.shape)| (4, 114) (114, 4) |
#최종 모델의 정확도 확인
lr_final.fit(pred, y_test)
final = lr_final.predict(pred)
print('최종 메타 모델의 예측 정확도: {0:.4f}'.format(accuracy_score(y_test , final)))| 최종 메타 모델의 예측 정확도: 0.9737 |
'Python' 카테고리의 다른 글
| [Python] 차원 축소 (0) | 2024.03.12 |
|---|---|
| [Python] 지도학습 연습 _ 범주형 데이터 이진분류 (0) | 2024.03.07 |
| [Python] 회귀 - 비선형 회귀 (0) | 2024.03.07 |
| [Python] 분류 (0) | 2024.03.07 |
| [Python] 머신러닝 (0) | 2024.03.07 |