
https://www.kaggle.com/competitions/cat-in-the-dat
Categorical Feature Encoding Challenge | Kaggle
www.kaggle.com
1. 범주형 데이터 이진분류
- 문제 유형: 이진분류
- 평가지표: ROC AUC
- 미션은 Target에 속할 확률
데이터
- 인위적으로 만든 데이터
- 피처와 타겟에 대한 의미를 알 수 없음
- 제공되는 데이터는 전부 범주형
- bin_: 이진 범주
- nom_: 명목형 범주
- ord_: 순서형 범주
- day와 month는 날짜 피처
데이터 읽어보기
- 데이터를 읽어봤더니 각 행을 구분하는 id 속성이 존재한다.
- DataFrame을 만들 때 각 행을 구분하는 컬럼이 있는 경우는 index로 설정하는 것이 좋다.
import pandas as pd
train = pd.read_csv('./cat/train.csv', index_col='id')
test = pd.read_csv('./cat/test.csv', index_col='id')
submission = pd.read_csv('./cat/sample_submission.csv', index_col='id') |
 |
- train 데이터의 열이 test 데이터의 열보다 1개 많다. (target)
2. 데이터 탑색
1) 타겟 분포 확인
- 로그 분포 변환을 수행할지 여부
- 층화 추출 같은 샘플링 적용 여부
print(train['target'].value_counts())| target 0 208236 1 91764 Name: count, dtype: int64 |
- 아주 큰 차이는 아니어서 층화 추출을 고려하지 않아도 된다.
- 한 쪽에 4-5베 쏠린 정도일 때 층화 추출
- 데이터수가 매우 크면 층화추출을 할 필요가 없다.
Decision Tree
----------------sklearn
- RandomF: 랜덤추출
- Ada
- GB : 경사하강법
- HistGB : 피처(연속형)의 구간(정수)화하여 경사하강법
---------외부라이브러리
- XGBoost
- LGBM
- CAT
무작위성 추가, 속도 향상 등등
딥러닝
- 데이터가 많을 때 성능 날뜀
트리 모델을 쓸 때 조심할 점
1. 트리를 만들 때는 균형을 맞춰야 한다.
- 깊이가 깊어지면 찾기가 더 힘들어지기 때문이다. 트리가 한쪽으로 치우치면 평균 조회횟수가 높아진다.
- 그래서 Balaned Tree를 만들려고 애쓰는데, LGBM은 이걸 신경쓰지 않기 때문에 훈련속도가 빠르다.
2. 이상치나 과대적합 가능성
- 하나하나는 조건인데 만약 샘플이 한개밖에 없다면 이상치이거나 과대적합의 가능성이 높다.
- 10만개 중 1개의 데이터를 맞추기 위해 알고리즘을 생성했다면 (상황에 따라 필요한 경우도 있지만) 과대적합의 가능성이 높다.
- 샘플이 적은데 비율 차이가 많이 나면 그냥 하면 안됨.
추출을 할 때 반드시 100:1로 추출해! 그럼 선택이 안되는 상황은 줄어든다. => 층화추출
max_depth 트리의 깊이가 줄어들면 조건이 세분화되지 않으니까 배치되는 샘플이 많아진다. 얕게 여러번 하자!
mean_leaf_nodes / samples같은게 있으면 배치할 수 있는 샘플 수가 있다. 최소 10개는 주자~
3. 시각화 한번 해서 확인하기!
2) 피처 확인
# 피처의 정보를 출력해주는 함수
#범주형에서 중요한 정보는 결측값 개수, 고유한 값의 개수 등
def resumetable(df):
print("데이터 프레임 구조:", df.shape)
#각 피처의 자료형 출력
summary = pd.DataFrame(df.dtypes, columns=['데이터 타입'])
summary = summary.reset_index()
summary = summary.rename(columns={'index': '피처'})
summary['결측값 개수'] = df.isnull().sum().values
summary['고유값 개수'] = df.nunique().values
summary['첫번째 값'] = df.loc[0].values
summary['두번째 값'] = df.loc[1].values
summary['세번째 값'] = df.loc[2].values
return summary |
# 순서형, 범주형 데이터 고유값 확인
for i in range(3):
feature = "ord_" + str(i)
print(f'{feature} 고유값: {train[feature].unique()}')| ord_0 고유값: [2 1 3] ord_1 고유값: ['Grandmaster' 'Expert' 'Novice' 'Contributor' 'Master'] ord_2 고유값: ['Cold' 'Hot' 'Lava Hot' 'Boiling Hot' 'Freezing' 'Warm'] |
for i in range(3, 6):
feature = "ord_" + str(i)
print(f'{feature} 고유값: {train[feature].unique()}') |
# day와 month의 고유값
print('day의 고유값:', train['day'].unique())
print('month의 고유값:', train['month'].unique())| day의 고유값: [2 7 5 4 3 1 6] month의 고유값: [ 2 8 1 4 10 3 7 9 12 11 5 6] |
- day는 요일로 판단하는구나
3) 시각화
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('font', size=15)
plt.figure(figsize=(7, 6))
# 타겟값(0, 1)의 분포 시각화
ax = sns.countplot (x='target', data=train)
ax.set(title='Target Distribution') |
# 이진 피처(bin_0 ~ bin_4)와 타겟 분포 확인
sns.countplot (x='bin_0', hue='target', data=train)
sns.countplot (x='bin_1', hue='target', data=train)
sns.countplot (x='bin_2', hue='target', data=train)
sns.countplot (x='bin_3', hue='target', data=train) |  |
 |  |
- 범주 값에 따라 타겟의 분포가 유의미하게 차이가 나므로 이진 피처는 분류에 전부 사용
# 명목형 피처(nom_)와 타겟의 분포 확인
sns.countplot (x='nom_0', hue='target', data=train)
sns.countplot (x='nom_1', hue='target', data=train)
sns.countplot (x='nom_2', hue='target', data=train)
sns.countplot (x='nom_3', hue='target', data=train) |  |
 |  |
- 각 피처들의 값에 따라 유의미한 변화가 감지됨
# 순서형 피처(ord_)와 타겟 분포 확인
sns.countplot (x='ord_0', hue='target', data=train)
sns.countplot (x='ord_1', hue='target', data=train)
sns.countplot (x='ord_2', hue='target', data=train)
sns.countplot (x='ord_3', hue='target', data=train) |  |
 |  |
# 순서가 의미를 갖는 범주형 데이터의 순서 설정
from pandas.api.types import CategoricalDtype
#범주형 데이터의 순서 설정
ord_1_value = ['Novie', 'Contributer', 'Expert', 'Master', 'Grandmaster']
ord_2_value = ['Freezing', 'Cold', 'Warm', 'Hot', 'BoillingHot', 'Lava Hot']
#범주형 데이터를 하나의 데이터 타입으로 생성
ord_1_dtype = CategoricalDtype(categories=ord_1_value, ordered=True)
ord_2_dtype = CategoricalDtype(categories=ord_2_value, ordered=True)
_
#반영
train['ord_1'] = train['ord_1'].astype(ord_1_dtype)
train['ord_2'] = train['ord_2'].astype(ord_2_dtype) |
- 탐색 결과
- 결측값 없음
- 모든 피처가 target과 유의미한 차이를 가지므로 제거할 피처를 찾지 못함
4) 기본 모델로 분류
#데이터 가져오기
#훈련 데이터와 테스트 데이터를 합쳐서 동일한 구조 만들기
all_data = pd.concat([train, test])
all_data = all_data.drop('target', axis=1) |
- 데이터가 전부 범주형이고 문자열 등이 혼합되어 있어서 원-핫 인코딩을 수행해서 숫자로 변환
- sklearn.preprocessing.OneHotEncoder나 pandas.get_dummies 사용
#피처 원핫 인코딩
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder()
all_data_encoded = encoder.fit_transform(all_data)
all_data_encoded| <500000x16552 sparse matrix of type '<class 'numpy.float64'>' with 11500000 stored elements in Compressed Sparse Row format> |
5) 훈련 데이터와 테스트 데이터 생성
num_train = len(train)
X_train = all_data_encoded[:num_train]
#답안 생성을 위한 데이터 - 새로운 데이터
X_test = all_data_encoded[num_train:]
y = train['target']
#타겟의 비율에 따라 층화추출
from sklearn.model_selection import train_test_split
X_train, X_valid, y_train, y_valid = train_test_split(X_train, y, test_size =0.3,
stratify=y, random_state=42)
# 회귀 모델을 만들어서 훈련하고 ROC, AUC 점수 출력
from sklearn.linear_model import LogisticRegression
#로지스틱 회귀를 이용해서 훈련
logistic_model = LogisticRegression(max_iter=1000, random_state=42)
logistic_model.fit(X_train, y_train)
#ROC AUC 점수 출력
y_valid_preds = logistic_model.predict_proba(X_valid)[:, 1]
from sklearn.metrics import roc_auc_score
roc_auc = roc_auc_score(y_valid, y_valid_preds)
print('ROC AUC:', roc_auc)| ROC AUC: 0.7938612279220084 |
6) 답안 생성
y_preds = logistic_model.predict_proba(X_test)[:, 1]
submission['target'] = y_preds
submission.to_csv('submission.csv')
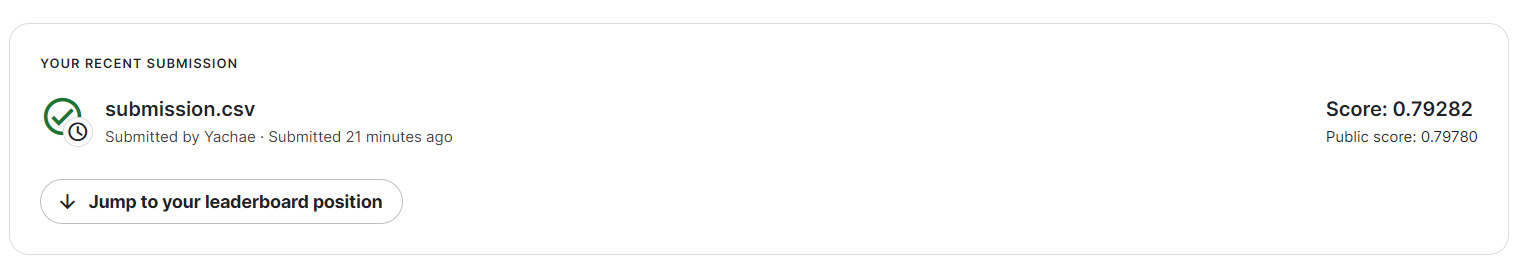
7) 인코딩 방식을 변경하고 스케일링 수행
피처 엔지니어링
# 이진 피처 중 값이 0,1이 아닌 피처의 값을 0,1로 수정
all_data['bin_3'] = all_data['bin_3'].map({'F':0, 'T':1})
all_data['bin_4'] = all_data['bin_4'].map({'N':0, 'Y':1})
#순서형 피처 데이터 변경
#순서형 피처 데이터 변경
ord1dict = {'Novice':0, 'Contributor':1, 'Expert':2, 'Master':3, 'Grandmaster':4}
ord2dict = {'Freezing':0, 'Cold':1, 'Warm':2, 'Hot':3, 'Boiling Hot':4,
'Lava Hot':5}
all_data['ord_1'] = all_data['ord_1'].map(ord1dict)
all_data['ord_2'] = all_data['ord_2'].map(ord2dict) |
#순서형 피처 라벨 인코딩
from sklearn.preprocessing import OrdinalEncoder
ord_345 = ['ord_3', 'ord_4', 'ord_5']
ord_encoder = OrdinalEncoder()
all_data[ord_345] = ord_encoder.fit_transform(all_data[ord_345]) |
# 명목형 목록은 이전처럼 원핫인코딩
nom_features = ['nom_' + str(i) for i in range(10)]
onehot_encoder = OneHotEncoder()
encoded_nom_matrix = onehot_encoder.fit_transform(all_data[nom_features])
#명목형 피처는 제거
all_data = all_data.drop(nom_features, axis=1) |
#day와 month를 원핫 인코딩하고 피처 삭제
date_features = ['day', 'month']
onehot_encoder = OneHotEncoder()
encoded_date_matrix = onehot_encoder.fit_transform(all_data[date_features])
all_data = all_data.drop(date_features, axis=1)
#순서형 피처의 값이 0 ~ 1이 아니므로 스케일링 수행
from sklearn.preprocessing import MinMaxScaler
ord_features = ['ord_' + str(i) for i in range(6)]
all_data[ord_features] = MinMaxScaler().fit_transform(all_data[ord_features])
#명목형 피처와 날짜 피처 합치기
from scipy import sparse
#원핫 인코딩 한 결과가 sparse matrix라서 희소 행렬을 합치는 API 사용
all_data_sprs = sparse.hstack([sparse.csr_matrix(all_data),
encoded_nom_matrix,
encoded_date_matrix], format='csr')
all_data_sprs| <500000x16306 sparse matrix of type '<class 'numpy.float64'>' with 9163718 stored elements in Compressed Sparse Row format> |
- 현재 작업
- 이진 피처는 숫자 0과 1로 생성
- 명목 피처는 원핫인코딩
- 순서형 피처는 순서를 만들어서 번호를 부여하거나 일련번호 형태로 인코딩한 후 스케일링 작업 수행
데이터 분할
#훈련 데이터의 개수
num_train = len(train)
#훈련용
X_train = all_data_sprs[:num_train]
#답안 제출용
X_test = all_data_sprs[num_train:]
#훈련용
y = train['target']
#ROC AUC 점수를 확인하라고 했으므로
#훈련 데이터를 다시 모델 훈련 데이터와 평가 훈련 데이터로 분할
X_train, X_valid, y_train, y_test = train_test_split(X_train, y,
test_size=0.3,
stratify=y,
random_state=42)
하이퍼 파라미터 튜닝
from sklearn.model_selection import GridSearchCV
logistic_model = LogisticRegression()
Ir_params = {'C':[0.1, 0.125, 0.2], 'max_iter':[800, 900, 1000],
'random_state':[42]}
gridsearch_logistic_model = GridSearchCV(estimator=logistic_model,
param_grid=Ir_params,
scoring='roc_auc',
cv=5)
gridsearch_logistic_model.fit(X_train, y_train)print(gridsearch_logistic_model.best_params_)| {'C': 0.125, 'max_iter': 800, 'random_state': 42} |
#ROC_AUC 점수 출력
y_valid_preds = gridsearch_logistic_model.predict_proba(X_valid)[:, 1]
roc_auc = roc_auc_score(y_valid, y_valid_preds)
print(roc_auc)| 0.8013521765689966 |
답안 생성
y_preds = gridsearch_logistic_model.best_estimator_.predict_proba(X_test)[:, 1]
submission['target'] = y_preds
submission.to_csv('submission.csv')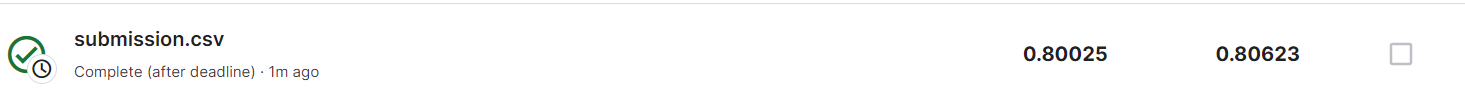
모든 데이터를 가지고 훈련
#훈련 데이터 개수
num_train = len(train)
#훈련용
X_train = all_data_sprs[:num_train]
#답안 제출용
X_test = all_data_sprs[num_train:]
#훈련용
y = train['target']
logistic_model = LogisticRegression()
Ir_params = {'C':[0.1, 0.125, 0.2], 'max_iter':[700, 800, 900, 1000],
'random_state':[42]}
gridsearch_logistic_model = GridSearchCV(estimator=logistic_model,
param_grid=Ir_params,
scoring='roc_auc',
cv=5)
gridsearch_logistic_model.fit(X_train, y)y_valid_preds = gridsearch_logistic_model.predict_proba(X_valid)[:, 1]
roc_auc = roc_auc_score(y_valid, y_valid_preds)
print(roc_auc)
print(gridsearch_logistic_model.best_params_)| 0.826168104832565 {'C': 0.125, 'max_iter': 700, 'random_state': 42} |
- 점수를 확인해서 이전보다 좋아지면 샘플의 개수가 모델의 성능에 영향을 준다는 것 확인
- 피처를 수정하면 성능이 이전보다 좋아지는 경향이 있음
'Python' 카테고리의 다른 글
| [Python] 감성 분석 실습 (3) | 2024.03.14 |
|---|---|
| [Python] 차원 축소 (0) | 2024.03.12 |
| [Python] 머신러닝_앙상블 (0) | 2024.03.07 |
| [Python] 회귀 - 비선형 회귀 (0) | 2024.03.07 |
| [Python] 분류 (0) | 2024.03.07 |