
1. Keras
- 모든 종류의 신경망을 손쉽게 만들고 훈련, 평가, 실행할 수 있는 고수준 딥러닝 API
- API 문서는 https://keras.io
- 거의 모든 딥러닝 라이브러리에서 사용 가능
2. Keras 의 Dense
- 완전 연결 층을 만들기 위한 클래스
- 완전 연결 층 : 이전 층의 모든 연산을 받아들이는 층
import tensorflow as tf
from tensorflow import keras
2-1) 생성할 때 파라미터
- unit: 뉴런의 개수
- activation: 활성화 함수로 기본값은 None 이고 sigmoid, softmax(다중 분류 문제에 사용), tanh(하이퍼볼릭 탄젠트 함수), relu 등을 설정할 수 있다.
- input_shape 는 입력 층(첫번째 층)의 경우 입력되는 데이터의 크기를 지정해야 하는 매개변수
- 샘플 데이터 생성
X = np.arange(1, 6)
y = 3 * X + 2
print(X)
print(y)| [1 2 3 4 5] [ 5 8 11 14 17] |
2-2) Tensorflow의 Keras 모델 생성 방법
- Sequential API
- Functional API
- SubClassing
2-3) Sequential API 활용
- 층을 이어 붙이듯 시퀀스에 맞게 일렬로 연결하는 방식
- 입력 레이어부터 출력 레이어까지 순서를 갖는 형태
- 입력 레이어가 첫번째 레이어가 되는데 입력 데이터가 이 레이어 투입되고 순서대로 각 층을 하나씩 통과하면서 딥러닝 연산을 수행
- 이해하기가 가장 쉬운 방법이지만 2개 이상의 다중 입력이나 다중 출력을 갖는 복잡한 구조를 만들 지 못함
- 모델 구조
- list 이용
model = tf.keras.Sequential([
tf.keras.layers.Dense(10),
tf.keras.layers.Dense(5),
tf.keras.layers.Dense(1)
]) - add 함수 이용
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(10))
model.add(tf.keras.layers.Dense(5))
model.add(tf.keras.layers.Dense(1))
- 입력 데이터 형태 지정
- 첫번째 층의 input_shape 에 튜플이나 리스트 형태로 설정
- shape 가 150, 4 인 경우 (150, 4), [150, 4] 도 가능하고 (4, ), [4] 도 가능
- 첫번째 숫자가 데이터의 개수이고 나머지 부분이 데이터의 shape 가 되므로 데이터의 개수를 생략하더라도 shape 가 설정되면 데이터의 개수는 유추할 수 있기 때문
- 단순 선형 회귀 모델 생성
- Layer가 1개면 가능
- 입력 데이터는 피처가 1개
- 출력도 하나의 숫자
첫번째 층은 입력 구조가 필수
마지막 층의 뉴런의 개수는 출력하는 데이터의 피처 개수
model = tf.keras.Sequential([
tf.keras.layers.Dense(1, input_shape=(1,))
])
- Sequential 모델은 모델의 구조를 확인하는 것이 가능 - summary()
#모델의 구조 확인
model.summary()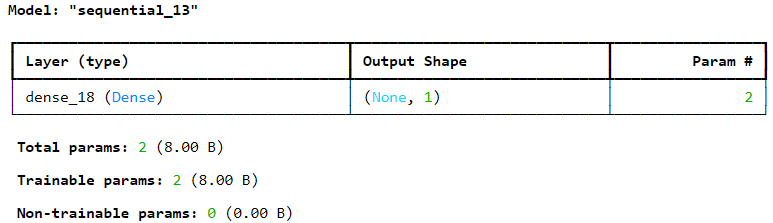 |
- 각 층에 대한 정보 리턴
- 컴파일
- 컴파일 과정에서는 Optimizer, Loss Function(손실 함수로 일반적으로 평가 지표를 작성), Metrics(평가 지표를 작성하는데 여기는 list가 가능) 를 지정
- 작성을 할 때는 긴문자열, 짧은 문자열, 클래스 인스턴스 3가지 방법이 가능한데 문자열로 설정하는 경우는 세부적인 파라미터 조정이 안되고 클래스 인스턴스를 이용하면 세부 파라미터 조정이 가능
# 모델 컴파일
model.compile(optimizer='sgd', loss='mean_squared_error',
metrics=['mean_squared_error', 'mean_absolute_error']) #긴 문자열 사용
model.compile(optimizer='sgd', loss='mse',
metrics=['mse', 'mae']) #짧은 문자열 사용
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.005),
loss = tf.keras.losses.MeanSquaredError(),
metrics = [tf.keras.metrics.MeanSquaredError(),
tf.keras.metrics.MeanAbsoluteError])
# 훈련
- 훈련을 하면 가중치를 업데이트
- 훈련 데이터 세트의 입력(X) 과 정답에 해당하는 출력(y) 그리고 반복 훈련 횟수에 해당하는 epoch 를 설정하는데 기본적으로 훈련을 할 때 마다 손실 과 평가 지표를 출력하는데 verbose=0 을 추가하면 중간 과정이 생략
- validation_data 에 검증 데이터를 설정하면 검증 데이터에 대한 손실 과 평가 지표도 같이 반환
- fit 함수가 리턴하는 객체는 epoch 별 손실 과 평가지표를 dict로 저장하고 있다.
history = model.fit(X, y, epochs=1000, verbose=0)
#훈련 과정에서 발생한 손실 과 평가지표를 시각화
plt.plot(history.history['loss'], label='loss')
plt.legend()
plt.show() |
- 검증 및 예측
- 검증은 evaluate 메서드에 훈련 데이터를 입력하면 됩니다.
model.evaluate(X, y)
- 예측
- predict(ndarray 나 tensor로 대입
model.predict(np.array([10]))
2-4) Classification 분류
- 데이터가 어느 범주(Category)에 해당하는지 판단하는 문제
- 회귀가 알고리즘의 퍼포먼스를 확인하기 위해서는 잔차 제곱의 합(SSE) 나 잔차 제곱의 평균(MSE) 등을 사용하고 이 값들은 일반적으로 실수
- 분류에서는 같은 목적으로 예측이 정답을 얼마나 맞혔는지에 대한 정확도를 측정
- 정확도는 보통 퍼센트로 나타내고 이 수치는 직관적이기 때문에 머신러닝 알고리즘의 벤치마크 역할을 분류를 가지고 판단
- ImageNet 이라는 데이터베이스를 이용해서 이미지의 범주를 분류하는 대회가 있는데 2012년 CNN이 등장하면서 2017 년에 거의 100%를 달성
- 이항 분류
- 정답의 범주가 두 개인 분류 문제
# 레드와 화이트와인 분류: 이항 분류
2024.03.20 - [Python/Python 실전편] - [딥러닝] Keras 이항분류 _ 레드와 화이트와인 분류
# 패션 이미지 분류
2024.03.20 - [Python/Python 실전편] - [딥러닝] Keras _ 패션 이미지 분류
[딥러닝] Keras _ 패션 이미지 분류
Keras 의 내장 데이터 세트 - 종류 boston housing: 보스톤 집값으로 회귀에 사용 cifar10: 이미지 분류 데이터로 종류가 10가지 cifar100: 이미지 분류 데이터로 종류가 100가지 mnist: 손 글씨 데이터 fashion mni
yachae4910.tistory.com
2-5) subclassing
- Sequential API 나 Functional API는 선언적 방식인데 사용할 층 과 연결 방식을 정의한 후 모델에 데이터를 주입해서 훈련이나 추론을 하는 방식
- 선언적 방식은 장점이 많은데 모델을 저장하거나 복사 또는 공유하기 쉬우며 모델의 구조를 출력하거나 분석하기도 좋고 프레임워크가 크기를 짐작하고 타입을 확인해서 에러를 일직 발견할 수 있고 디버깅하기도 쉬움
- 정적이라는 단점이 있음
- 수정하지 못함
- subclassing 은 기존의 클래스를 상속받아서 수정해서 사용하는 것
- Model 클래스를 상속받고 __init__ 메서드에서 필요한 층을 만들고 call 메서드 안에 수행하려는 연산을 기술하고 출력 층을 리턴하도록 작성
- subclassing 을 하고자 하면 원 클래스에 메서드들의 기능을 확인할 필요가 있습니다.
- 필요한 메서드를 오버라이딩 해서 사용
- 샘플
class WideAndDeepModel(keras.models.Model):
def __init__(self, 필요한 매개변수, **kwargs):
super().__init__(**kwargs)
self.hidden1 = keras.layers.Dense(units, activation)
self.hidden2 = keras.layers.Dense(units, activation)
self.hidden3 = keras.layers.Dense(units, activation)
self.output = keras.layers.Dense(units)
def call(self, inputs):
hidden1 = self.hidden1(input_B)
..
return self.output
model = WideAndDeepModel(매개변수)
2-6) 모델 저장과 복원
- 모델을 만들고 훈련 한 후 모델.save 함수를 호출하면 모델을 훈련한 상태로 저장할 수 있다.
- load_model 함수를 이용해서 복원이 가능
- 복원한 모델을 이용해서 예측을 할 수 도 있고 훈련을 추가로 할 수 있습니다.
- 복원한 모델을 가지고 추가 훈련을 해서 사용하는 것을 사전 훈련된 모델을 이용한다고 함
3. Keras NN
3-1) Sequential API 이용 회귀
# 데이터 가져오기
- 외부에서 데이터를 가져오면 자료형을 확인
- 디셔너리라면 모든 key를 확인 - keys()
- 클래스라면 모든 속성을 확인 - dir
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
print(type(housing))
print(dir(housing))| <class 'sklearn.utils._bunch.Bunch'> ['DESCR', 'data', 'feature_names', 'frame', 'target', 'target_names'] |
# 데이터 분할 - 훈련 / 훈련 시 검증 / 테스트
from sklearn.model_selection import train_test_split
X_train_full, X_test, y_train_full, y_test = train_test_split(housing.data, housing.target, random_state=42)
X_train, X_valid, y_train, y_valid = train_test_split(X_train_full, y_train_full, random_state=42)
# 정규화
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_valid = scaler.fit_transform(X_valid)
X_test = scaler.fit_transform(X_test)
print(X_train.shape)| (11610, 8) |
# 회귀 모델 만들기
- Sequential API를 이용해서 회귀용 MLP을 구축, 훈련, 평가, 예측하는 방법은 분류에서 했던 것 과 매우 비슷하지만
- 차이점은 출력 층이 활성화 함수가 없는 하나의 뉴런을 가져야 한다는 것, 손실 함수가 평균 제곱 오차나 평균 절대값 오차로 변경을 해야 함
import tensorflow as tf
from tensorflow import keras
#회귀 모델 만들기
#input_shape 설정할 때 데이터의 개수는 생략
model = keras.models.Sequential([
keras.layers.Dense(30, activation="relu", input_shape=X_train.shape[1:]),
keras.layers.Dense(15, activation="relu"),
keras.layers.Dense(units=1)
])
model.summary()Model: "sequential" |
# 모델 컴파일 및 훈련
model.compile(loss="mean_squared_error",
optimizer=keras.optimizers.SGD(learning_rate=0.001))
history = model.fit(X_train, y_train, epochs=20,
validation_data = (X_valid, y_valid)) Epoch 20/20 363/363 ━━━━━━━━━━━━━━━━━━━━ 1s 1ms/step - loss: 0.3844 - val_loss: 0.4524 |
# 모델 평가
print(model.evaluate(X_test, y_test)) |
# 예측
X_new = X_test[:3]
y_pred = model.predict(X_new)
print(y_pred) |
- Sequential API
- 층을 연결하고 모든 데이터가 순차적으로 층을 통과하면서 출력을 만드는 방식
3-2) Functional API를 활용한 회귀
- Functional API
- 일반적 MLP(Sequential API)는 네트워크에 있는 층 전체에 모든 데이터를 통과시키는데 이렇게 하면 간단한 패턴이 연속적인 변환으로 인해서 왜곡 될 수 있음
- 입력의 일부 또는 전체를 출력 층에 바로 연결하는 방식
- MLP가 전체를 통과하기도 하고 일부분만 통과하기도 하기 때문에 복잡한 패턴 과 단순한 패턴 모두를 학습해서 더 좋은 성과를 내기도 합니다.
- 함수형 API를 사용하게 되면 입력 데이터를 설정
- 층 간의 결합도 직접 설정
- 함수형 API를 이용해서 모델 만들기
#모델 만들기
input_ = keras.layers.Input(shape=X_train.shape[1:])
#input_ 층의 출력을 받아서 수행하는 층
hidden1 = keras.layers.Dense(30, activation="relu")(input_)
hidden2 = keras.layers.Dense(15, activation="relu")(hidden1)
#2개의 층 합치기
concat = keras.layers.concatenate([input_, hidden2])
#출력 층 생성
output = keras.layers.Dense(1)(concat)
model = keras.models.Model(inputs=[input_], outputs=[output]) |
- 함수형 API의 모델을 만들 때는 input 과 output에 list를 대입한다.
- 여러 개의 입력 과 여러 개의 출력 사용이 가능하다.
- 객체 탐지 와 같은 문제를 해결할 때는 출력이 1개가 아니라 여러 개인 경우가 많다.
- 이런 문제는 Sequential API로는 해결할 수 없다.
# 컴파일과 훈련
model.compile(loss="mean_squared_error",
optimizer=keras.optimizers.SGD(learning_rate=0.001))
history = model.fit(X_train, y_train, epochs=20,
validation_data = (X_valid, y_valid)) Epoch 20/20 363/363 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - loss: 0.4188 - val_loss: 0.4654 |
- 입력 경로 여러개 생성
#여러 경로의 input 사용
input_A = keras.layers.Input(shape=[5])
input_B = keras.layers.Input(shape=[6])
hidden1 = keras.layers.Dense(30, activation="relu")(input_B)
hidden2 = keras.layers.Dense(15, activation="relu")(hidden1)
#input_A는 하나의 hidden 층도 통과하지 않은 데이터
# hidden2는 2개의 hidden 층을
#통과한 데이터
concat = keras.layers.concatenate([input_A, hidden2])
output = keras.layers.Dense(1)(concat)
#입력을 2가지를 사용 - 데이터의 다양성을 추가해서 학습
#모든 입력이 hidden layer를 통과하게 되면 깊이가 깊어질 때 데이터의 왜곡 발생 가능
model = keras.models.Model(inputs=[input_A, input_B], outputs=[output])
# 모델의 input 데이터 수정해서 입력 데이터 수정
- 첫번째 입력은 앞의 5개를 사용하고 두번째 입력은 뒤의 6개를 이용 - 전체 데이터 사용
X_train_A, X_train_B = X_train[:, :5], X_train[:, 2:]
X_valid_A, X_valid_B = X_valid[:, :5], X_valid[:, 2:]
X_test_A, X_test_B = X_test[:, :5], X_test[:, 2:]model.compile(loss="mse", optimizer=keras.optimizers.SGD(learning_rate=0.001))
history = model.fit((X_train_A, X_train_B), y_train,
epochs=20, validation_data=((X_valid_A, X_valid_B), y_valid))
mse_test = model.evaluate((X_test_A, X_test_B), y_test) 363/363 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - loss: 0.4468 - val_loss: 0.4863 162/162 ━━━━━━━━━━━━━━━━━━━━ 0s 944us/step - loss: 0.4481 |
- 출력을 여러개 생성
필요한 이유:
- 그림에 있는 주요 물체를 분류하고 위치를 알아야 하는 경우가 있는데 이 경우는 분류 와 회귀를 동시에 수행해야 하는 경우
- 다중 분류 작업을 하고자 하는 경우
- 보조 출력을 사용하고자 할 때
- 서로 다른 입력을 받아서 딥러닝을 수행한 후 일정 비율을 적용해서 반영
다른 입력을 받아서 출력을 만든 후 0.9:0.1 비율로 반영해서 출력 만들기
- 손실 함수를 수행할 때 각 출력의 비중을 다르게 반영하도록 하기
- 여러 경로의 input 사용
input_A = keras.layers.Input(shape=[5])
input_B = keras.layers.Input(shape=[6])
hidden1 = keras.layers.Dense(30, activation="relu")(input_B)
hidden2 = keras.layers.Dense(15, activation="relu")(hidden1)
concat = keras.layers.concatenate([input_A, hidden2])
output = keras.layers.Dense(1)(concat)
aux_output = keras.layers.Dense(1)(hidden2)
model = keras.models.Model(inputs=[input_A, input_B],
outputs=[output, aux_output])#출력이 2개가 된 경우 손실을 적용할 때 비율을 설정하는 것이 가능
#이 경우는 첫번째 출력의 손실을 90% 반영하고 두번째 출력의 손실을 10% 반영
model.compile(loss="mse", optimizer=keras.optimizers.SGD(learning_rate=0.001),
loss_weights=[0.9, 0.1])
history = model.fit((X_train_A, X_train_B), y_train,
epochs=20, validation_data=((X_valid_A, X_valid_B), y_valid)) Epoch 20/20 363/363 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - loss: 0.3993 - val_loss: 0.4345 |
 |
X_new_A, X_new_B = X_test_A[:3], X_test_B[:3]
#출력이 2개 이므로 각 데이터마다 2개의 값을 리턴
y_pred_main, y_pred_aux = model.predict([X_new_A, X_new_B])
print(y_pred_main)
print(y_pred_aux)| 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 76ms/step [[0.4174796] [1.8939716] [3.5359378]] [[-0.1951855 ] [-0.06544766] [-0.6592884 ]] |
3-3) SubClassing을 이용하는 방법
- Model 클래스를 상속받아서 사용하는 방법
- __init__ 메서드를 재정의해서 필요한 층을 생성
- call 메서드를 재정의해서 출력층을 리턴
- 장점
- 모델을 생성할 때 필요한 매개변수를 직접 설정할 수 있기 때문에 동적인 모델을 만들 수 있다.
- 이전과 동일한 모델을 subclassing을 이용해서 구현
- 상위 클래스를 직접 만들지 않은 경우는 __init__ 메서드에서
- 상위 클래스의 __init__을 호출해야 합니다.
class WideAndDeepModel(keras.models.Model):
def __init__(self, units=30, activation="relu", **kwargs):
#상위 클래스의 초기화 메서드 호출
super().__init__(**kwargs)
#층을 생성
self.hidden1 = keras.layers.Dense(units, activation=activation)
self.hidden2 = keras.layers.Dense(units, activation=activation)
self.main_output = keras.layers.Dense(1)
self.aux_output = keras.layers.Dense(1)
#두번째 매개변수가 input
def call(self, inputs):
input_A, input_B = inputs
hidden1 = self.hidden1(input_B)
hidden2 = self.hidden2(hidden1)
concat = keras.layers.concatenate([input_A, hidden2])
main_output = self.main_output(concat)
aux_output = self.aux_output(hidden2)
return main_output, aux_output
model = WideAndDeepModel(30, activation="relu")
model.compile(loss="mse", optimizer=keras.optimizers.SGD(learning_rate=0.001),
loss_weights=[0.9, 0.1])
history = model.fit((X_train_A, X_train_B), y_train,
epochs=20, validation_data=((X_valid_A, X_valid_B), y_valid)) Epoch 20/20 363/363 ━━━━━━━━━━━━━━━━━━━━ 1s 1ms/step - loss: 0.3751 - val_loss: 0.4181 |
3-4) CallBack
- 어떤 사건이 발생했을 때 특정 작업을 수행하도록 하는 것
- 조기종료
- epochs 을 크게 지정하면 훈련을 많이 수행하기 때문에 성능이 좋아질 가능성이 높은데 늘리게 되면 훈련 시간이 오래 걸린다.
- 일정 에포크 동안 검증 세트에 대한 점수가 향상되지 않으면 훈련을 멈추도록 할 수 있다.
- keras.callbacks.EarlyStopping 클래스의 인스턴스를 만들 때 patience 매개변수에 원하는 에포크 지정해서 만들고 모델이 fit 메서드를 호출할 때 callbacks 파라미터에 list 형태로 대입하면 됨
#5번의 epoch 동안 점수가 좋아지지 않으면 조기 종료
early_stopping_cb = keras.callbacks.EarlyStopping(patience=5)
history = model.fit((X_train_A, X_train_B), y_train,
epochs=100, validation_data=((X_valid_A, X_valid_B), y_valid),
callbacks=[early_stopping_cb]) Epoch 45/100 363/363 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - loss: 0.3407 - val_loss: 0.3985 |
- 학습률 스케줄러
- 학습률을 동적으로 변화시켜서 수행하는 것이 가능
- LearningRateScheduler 라는 클래스를 이용하는데 이 때는 에포크 와 학습율을 매개변수로 갖는 함수를 만들어서 인스턴스를 생성할 때 대입
#5번의 epoch 동안 점수가 좋아지지 않으면 조기 종료
early_stopping_cb = keras.callbacks.EarlyStopping(patience=5)
#5번의 epoch 동안은 기존 학습률을 유지하고 그 이후에는 학습률을 감소시키는 함수
def scheduler(epoch, lr):
if epoch < 5:
return lr
else:
lr = lr - 0.0001
return lr
#학습률을 동적으로 변화시키는 체크포인트
lr_scheduler = tf.keras.callbacks.LearningRateScheduler(scheduler)
history = model.fit((X_train_A, X_train_B), y_train,
epochs=100, validation_data=((X_valid_A, X_valid_B), y_valid),
callbacks=[early_stopping_cb, lr_scheduler]) |
- 모델 저장과 복원
- 딥러닝은 fit 함수를 호출한 후 다음에 다시 fit을 호출하면 이전에 훈련한 이후 부터 다시 훈련하는 것이 가능
- 기존 모델을 저장하고 이를 읽어들여서 재훈련이 가능
# 모델 저장
- save 함수를 이용해서 저장
- 모델을 저장할 때 loss 는 반드시 full name으로 작성
- 버전에 따라서는 확장자를 제한하는 경우도 있다.
- 최신 버전에서 이 부분이 적용
model = keras.models.Sequential([
keras.layers.Dense(30, activation="relu", input_shape=[8]),
keras.layers.Dense(15, activation="relu"),
keras.layers.Dense(1)
])
model.compile(loss="mse", optimizer=keras.optimizers.SGD(learning_rate=0.001))
history=model.fit(X_train, y_train, epochs=10, validation_data=(X_valid, y_valid))
mse_test = model.evaluate(X_test, y_test)
#모델 저장
model.save("my_model.keras") |
- 모델 가져오기
- load 함수 이용
# 모델 복원
m = keras.models.load_model("my_model.keras")
#복원 된 모델과 기존의 모델이 같은 결과를 만들어 냅니다.
print(m.predict(X_new))
print(model.predict(X_new)) |
- 복원된 모델과 기존의 모델이 같은 결과를 만들어냄
- 모델의 가중치를 저장하고 복원
- save_weights 와 load_weights를 이용
model.save_weights("my_model.weights.h5")
model.load_weights("my_model.weights.h5")
- 모델을 저장하는 체크 포인트 사용
- ModelCheckPoint 라는 클래스를 이용해서 모델의 이름을 설정
- 체크 포인트를 만들 때 이름만 설정하면 마지막 모델이 저장
- 마지막 모델은 최상의 모델이 아닐 수 있다.
- save_best_only=True를 설정하면 최상의 모델을 저장한다.
checkpoint_cb = keras.callbacks.ModelCheckpoint('my_model.keras',
save_best_only=True)
history = model.fit(X_train, y_train, epochs=10,
validation_data=(X_valid, y_valid),
callbacks=[checkpoint_cb]) |
3-5) 사용자 정의 콜백
- Callback 클래스를 상속받아서 원하는 콜백을 생성할 수 있는 기능
- on_train_begin, on_train_end, on_epoch_begin, on_epoch_end, on_batch_bigin, on_batch_end 이 메서드들은 훈련전후 그리고 한 번의 에포크 전후 그리고 배치 전후에 작업을 수행시키고자 하는 경우에 사용
- on_test 로 시작하는 메서드를 오버라이딩 하면 검증 단계에서 작업을 수행
3-6) 신경망의 하이퍼 파라미터 튜닝
- 신경망의 유연성은 단점이 되기도 하는데 조정할 하이퍼 파라미터가 많음
- 복잡한 네트워크 구조에서 뿐 만 아니라 간단한 다층 퍼셉트론에서도 층의 개수, 층마다 존재하는 뉴런의 개수, 각 층에서 사용하는 활성화 함수, 가중치 초기화 전략 등 많은 것을 바꿀 수 있는데 어떤 하이퍼 파라미터 조합이 주어진 문제에 대해서 최적인지 확인
- 이전 머신러닝 모델들은 GridSearchCV 나 RandomizedSearchCV를 이용해서 하이퍼 파라미터 공간을 탐색할 수 있었는데 딥러닝에서는 이 작업을 할려면 Keras 모델을 sklearn 추정기 처럼 보이도록 바꾸기
- 신경망의 하이퍼 파라미터 튜닝
keras.backend.clear_session()
np.random.seed(42)
tf.random.set_seed(42)
# 딥러닝 모델을 만드는 함수
def build_model(n_hidden=1, n_neurons=30, learning_rate=0.003, input_shape=[8]):
model = keras.models.Sequential()
#입력 레이어 추가
model.add(keras.layers.InputLayer(input_shape=input_shape))
#n_hidden 만큼 히든 층 추가
for layer in range(n_hidden):
model.add(keras.layers.Dense(n_neurons, activation="relu"))
#출력 층 추가
model.add(keras.layers.Dense(1))
#최적화 함수 생성
optimizer = keras.optimizers.SGD(learning_rate = learning_rate)
model.compile(loss="mean_squared_error", optimizer=optimizer, metrics=['mse'])
return model
# 하이퍼 파라미터 튜닝을 위해 scikit-learn 추정기로 딥러닝 모델 생성
!pip install scikerasfrom scikeras.wrappers import KerasRegressor
keras_reg = KerasRegressor(build_model())
from sklearn.model_selection import RandomizedSearchCV
param_distribs = {
"epochs":[100, 200, 300, 400, 500, 600]
}
#랜더마이즈드 cv를 생성
rnd_search_cv = RandomizedSearchCV(keras_reg, param_distribs, n_iter=10, cv=3,
verbose=2)
#하이퍼파라미터 튜닝
rnd_search_cv.fit(X_train, y_train, epochs=100,
validation_data=(X_valid, y_valid),
callbacks=[keras.callbacks.EarlyStopping(patience=10)])
- 은닉 층 개수
- 이론적으로는 은닉 층이 하나인 다층 퍼셉트론이라도 뉴런 개수가 충분하다면 아주 복잡한 함수도 모델링할 수 있지만 심층 신경망이 얕은 신경망보다 파라미터 효율성이 좋다.
- 심층 신경망은 복잡한 함수를 모델링하는데 얕은 신경망보다 적은 수의 뉴런을 사용하기 때문에 동일한 양의 훈련 데이터에서 더 높은 성능을 낼 수 있다.
- 심층 신경망을 만들면 아래쪽 은닉 층은 저수준의 구조를 모델링하고
중간 은닉 층은 저수준의 구조를 연결해서 중간 수준의 구조를 모델링하고
가장 위쪽 은닉 층 과 출력 층은 중간 수준의 구조를 연결해서 고수준의 구조를 모델링 - MNIST 데이터 세트에서 하나의 은닉층에 수백개의 뉴런을 사용한 경우 정확도가 97% 정도 나왔는데 동일한 수의 뉴런을 사용하고 은닉층을 2개로 늘렸을 때 98% 정도의 정확도
- 복잡한 문제들은 훈련 세트에 과대 적합이 될 때 까지 점진적으로 은닉 층의 개수를 늘릴 수 있는데 대규모 이미지 분류나 음성 인식 분야에서는 수십개에서 수백개의 은닉층을 가지게 되는데 이런 경우는 훈련 데이터가 아주 많이 필요함
- 일반적으로 이런 네트워크를 처음부터 훈련하는 경우는 거의 없음
- 비슷한 작업에서 가장 뛰어난 성능을 낸 미리 훈련된 네트워크 일부를 재사용
- 은닉 층의 뉴런 개수
- 입력 층 과 출력 층의 뉴런의 개수는 수정할 수 없음
- 은닉 층의 뉴런의 개수는 일반적으로 각 층의 뉴런의 개수를 줄여가면서 깔대기처럼 구성하는데 저수준의 많은 특성이 고수준의 적은 특성으로 합쳐질 수 있기 때문
- 뉴런의 개수는 일단 많이 가지고 시작을 하다가 조기 종료 나 규제를 이용해서 조정
- 학습률
- 좋은 학습률을 찾는 방법은 아주 작은 학습률(0.00001) 에서 시작해서 점진적으로 큰 학습률(10) 까지 수백 번 반복하여 모델을 훈련
- 보통의 경우는 0.00001 ~ 10 까지 exp(log (10의 6승 / 500)) 을 곱해가면서 조정
- Optimiazer
- SGD 보다는 최근에 등장한 Optimizer 사용을 권장
- Batch_Size
- 32 이하의 크기를 사용하는 권장하지만 최근에는 학습률을 작은 값에서 큰 값으로 변경해가면서 수행하는 경우는 192 정도의 크기도 괜찮다.
- 배치 크기가 커지면 훈련 시간을 단축할 수 있음
- 학습률을 변경하면서 수행할 때 큰 배치 크기를 사용하고 훈련이 불안정해지면 작은 배치 크기를 선택
- 활성화 함수
- 일반적으로 ReLU 가 좋은 값
- 반복 횟수
- 대부분 크게 설정하고 조기 종료를 설정
3-7) 딥러닝에서의 문제점과 해결책
- 그라디언트 소실 과 폭주 문제
- 역전파 알고리즘:
출력 층에서 입력 층으로 오차 그라디언트를 전파하면서 진행되는데 알고리즘이 신경망의 모든 파라미터에 대한 오차 함수의 그라디언트를 계산하면 경사 하강법 단계에서 이 그라디언트를 사용해서 파라미터를 수정 - vanishing gradient(그라디언트 소실) :
알고리즘이 하위 층으로 진행될수록 그라디언트는 점점 작아지는 경우가 많은데 경사 하강법이 하위 층의 연결 가중치를 변경하지 않은채로 둔다면 훈련이 좋은 솔루션을 찾지 못하게 되는 현상. - exploding gradient(폭주):
그라디언트가 점점 더 커져서 여러 층이 비정상적으로 큰 가중치를 가지되면 알고리즘은 발산한다고 하는데 RNN에서 주로 나타남 - 원인
- 활성화 함수로 로지스틱 시그모이드 함수를 사용하고 가중치 초기화를 할 때 평균이 0이고 표준 편차가 1인 정규 분포에서 추출한 값으로 한 것
- 로지스틱 시그모이드 함수는 평균이 0이 아니고 0.5 이기 때문에 이 문제가 발생한다고 보고 하이퍼볼릭 탄젠트 함수(평균이 0)를 사용
- 글로럿과 He 초기화
- 딥러닝 초창기에는 가중치 초기화를 할 때 평균이 0이고 표준 편차가 1인 정규 분포에서 추출한 값을 가지고 사용
- 글러럿 초기화 또는 세이비어 초기화
- 평균이 0이고 분산이 1/fan(avg) 인 정규 분포 나 제곱근(3/fan(avg)) 한 값에 -1 과 1을 곱한 값의 균등 분포에서 초기화
fan-in: 입력의 개수
fan-out: 출력의 개수
fan(avg) = (fan-in + fan-out)/2 - 훈련 속도도 향상
- fan(avg) 대신에 fan-in을 사용하면 르쿤 초기화라고 함
- 평균이 0이고 분산이 1/fan(avg) 인 정규 분포 나 제곱근(3/fan(avg)) 한 값에 -1 과 1을 곱한 값의 균등 분포에서 초기화
- He 초기화
- ReLU와 그 변종들
- 2/fan-in 인 정규분포를 가지고 초기화
- keras 에서 지원하는 목록: https://www.tensorflow.org/api_docs/python/tf/keras/initializers
- 기본값은 Glorot 초기화 인데 다른 방법을 사용하고자 하면 kernel_initializer="초기화 방법" 을 지정하거나 클래스의 인스턴스로 지정
- 지원 가능한 목록
- print([name for name in dir(keras.initializers) if not name.startswith("_")])
- 사용
- keras.layers.Dense(10, activation="relu", kernel_initializer = "he_normal")
- 수렴하지 않는 활성화 함수
- 딥러닝 모델을 만들 때 잘못된 활성화 함수를 선택하면 그라디언트 소실이나 폭주 문제가 발생할 수 있음
- 초창기에는 sigmoid 함수가 최선이라고 생각을 했지만 이후에 다양한 활성화 함수가 등장
- 많이 사용되는 것은 relu, softmax, tanh 등ㅍ
- ReLU
- 특정 양수 값에 수렴하지 않는다는 장점이 있음
- 계산이 빠름
- 학습률을 너무 높게 설정하면 가중치의 합이 음수가 되서 뉴런이 죽어 버림
- 뉴런이 죽는 문제를 해결하기 위해서 max(알파*x, x)를 적용하는 방식이 있는데 이것이 LeakyReLU
- 활성화 함수로 적용해도 되지만 층을 만들어서 추가해도 됨
- 최근의 Tensorflow에서 제공하는 Keras API는 문자열로 설정하는 부분을 인스턴스를 생성해서 적용하는 부분으로 변경되고 있다.
- LeakyReLU를 적용한 패션 MNIST 분류
# 활성화 함수의 초기화 변경
(X_train_full, y_train_full), (X_test, y_test) = keras.datasets.fashion_mnist.load_data()X_train_full = X_train_full / 255.0
X_test = X_test / 255.0
X_valid, X_train = X_train_full[:5000], X_train_full[5000:]
y_valid, y_train = y_train_full[:5000], y_train_full[5000:]tf.random.set_seed(42)
np.random.seed(42)
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.Dense(250, kernel_initializer="he_normal"),
keras.layers.LeakyReLU(),
keras.layers.Dense(100, kernel_initializer="he_normal"),
keras.layers.LeakyReLU(),
keras.layers.Dense(50,kernel_initializer="he_normal"),
keras.layers.LeakyReLU(),
keras.layers.Dense(10, activation="softmax"),
])
model.compile(loss="sparse_categorical_crossentropy",
optimizer=keras.optimizers.SGD(learning_rate=0.001),
metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=10,
validation_data=(X_valid, y_valid)) |
print(model.evaluate(X_test, y_test))| 313/313 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.8340 - loss: 0.4829 [0.4901731014251709, 0.8281000256538391] |
- 알파를 무작위로 선택하고 테스트 할 때는 평균을 사용하는 방식인 RReLU 방식도 제안
- 알파 값을 훈련하는 동안 역전파에 의해서 변경하는 PReLU 도 등장
- 대규모 이미지 세트에서는 매우 잘 동작을 하는데 소규모 데이터에서는 과대 적합이 발생하는 경우가 있음
- PReLU를 적용해서 비교
#PReLU 사용
tf.random.set_seed(42)
np.random.seed(42)
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.Dense(250, kernel_initializer="he_normal"),
keras.layers.PReLU(),
keras.layers.Dense(100, kernel_initializer="he_normal"),
keras.layers.PReLU(),
keras.layers.Dense(50,kernel_initializer="he_normal"),
keras.layers.PReLU(),
keras.layers.Dense(10, activation="softmax"),
])
model.compile(loss="sparse_categorical_crossentropy",
optimizer=keras.optimizers.SGD(learning_rate=0.001),
metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=10,
validation_data=(X_valid, y_valid))
print(model.evaluate(X_test, y_test)) |
- ELU 함수
- ReLU 와 유사한데 0보다 작을 때 알파(exp(데이터) - 1) 로 계산
- Dense 층에 activation 매개변수에 "elu"로 바로 적용
- 훈련 속도는 좋은데 검증 속도가 느림
#PReLU 사용
tf.random.set_seed(42)
np.random.seed(42)
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.Dense(250, kernel_initializer="he_normal", activation="relu"),
keras.layers.Dense(100, kernel_initializer="he_normal", activation="relu"),
keras.layers.Dense(50,kernel_initializer="he_normal", activation="relu"),
keras.layers.Dense(10, activation="softmax"),
])
model.compile(loss="sparse_categorical_crossentropy",
optimizer=keras.optimizers.SGD(learning_rate=0.001),
metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=10,
validation_data=(X_valid, y_valid))
print(model.evaluate(X_test, y_test))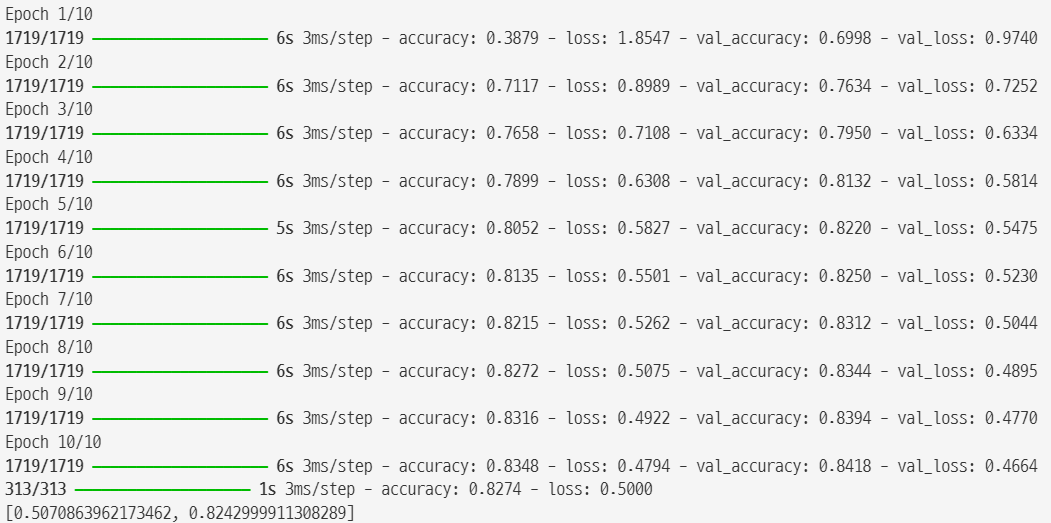 |
- SELU
- Scaled ELU
- 출력을 평균이 0이고 표준 편차가 1이 되도록 만들어주는 활성화 함수
- 다른 활성화 함수보다 뛰어난 성능을 발휘
- 제약조건
- 입력 특성이 반드시 표준화 되어 이어야 함(평균이 0이고 표준편차가 1)
- 가중치 초기화는 르쿤 초기화가 되어 있어야 함
- Sequential API로 생성된 모델이어야 함
- 단점
- 훈련 시간이 오래 걸림
- activation 매개변수에 selu를 설정
- 컴퓨팅 자원이 허락한다면 여러가지 초기화 방법을 적용해서 훈련을 하면 의미있는 결과를 얻어 낼 수 있다.
- 배치 정규화
- 활성화 함수를 변경하고 초기화 기법을 변경을 해서 그라디언트 소실 문제 나 폭주 문제를 어느 정도 해결할 수 있는데 훈련을 많이 하게 되면 완전히 해결했다고 보기는 어려움
- 활성화 함수에 대입하기 전 이나 후에 데이터를 원점에 맞추고 정규화 한 다음 2개의 새로운 파라미터를 추가해서 값의 스케일을 조정하고 이동시킴
- 새로 만들어진 2개의 파라미터는 하나는 스케일 조정에 사용하고 하나는 원점 이동에 사용
- 배치 정규화 층을 신경망의 첫번째 층으로 사용하면 훈련 세트를 표준화 할 필요가 없음
- 이 역할을 BatchNoramlization 이라는 층을 이용해서 수행
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.BatchNormalization(),
keras.layers.Dense(250, activation="relu"),
keras.layers.BatchNormalization(),
keras.layers.Dense(100, activation="relu"),
keras.layers.BatchNormalization(),
keras.layers.Dense(50, activation="relu"),
keras.layers.BatchNormalization(),
keras.layers.Dense(10, activation="softmax"),
])
model.compile(loss="sparse_categorical_crossentropy",
optimizer=keras.optimizers.SGD(learning_rate=0.001),
metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=10,
validation_data=(X_valid, y_valid))
print(model.evaluate(X_test, y_test)) |
- 배치 정규화를 이용하면 일부 뉴런이 죽는 현상을 거의 해소하기 때문에 성능이 좋아질 가능성이 높다.
- 그라디언트 클리핑
- 역전파 될 때 일정 임계값을 넘어서는 못하게 그라디언트를 잘라 내는 것
- RNN 에서는 배치 정규화를 사용하기가 어려움
- 이 경우에는 Optimizer를 만들 때 clipvalue 나 clipnorm 매개변수를 이용해서 Gradient 값을 제한하는 방법으로 유사한 효과를 나타낸다.
- 배치 정규화가 -1 ~ 1 사이의 값으로 정규화하므로 임계값은 1.0을 사용한다.
- 그라디언트의 값이 -1 보다 작거나 1보다 크면 -1 이나 1로 수정해서 기울기가 소실되는 것을 방지
- 사전 훈련된 층 재사용
- 전이학습 (Transfer Learning) : 큰 규모의 NN을 처음부터 훈련시키는 것은 많은 자원을 소모하게 되는데 이런 경우 해결하려는 것과 비슷한 유형의 문제를 처리한 신경망이 있는지 확인해보고 그 신경망의 하위층을 재사용하는 것이 효율적
- 전이 학습을 이용하게 되면 훈련 속도를 개선할 수 있고 훈련 데이터의 양도 줄어들게 된다.
- 동일한 이미지 분류 모델이라면 하위 층에서 유사하게 점이나 선 들의 모형을 추출하는 작업을 할 가능성이 높으므로 하위 층을 공유해도 유사한 성능을 발휘하게 된다.
- 출력 층은 하고자 하는 마지막 작업이 서로 다를 가능성이 높고(ImageNet 의 이미지를 분류하는 모델은 20,000 개의 카테고리를 가지고 있고 우리는 개와 고양이를 분류하는 이진 분류의 경우) 상위 층은 거의 출력 과 유사한 형태가 만들어 진 것이므로 역시 재사용할 가능성은 낮다.
- 샌달 과 셔츠를 제외한 모든 이미지를 가지고 분류 모델을 만들고 이를 이용해서 샌달과 셔츠 이미지 중 200개 만 가진 작은 훈련 세트를 훈련해서 정확도를 확인
#데이터 셋 분할
def split_dataset(X, y):
y_5_or_6 = (y == 5) | (y == 6)
#5 나 6이 아닌 데이터
y_A = y[~y_5_or_6]
y_A[y_A > 6] -= 2 #6보다 큰 레이블은 2를 빼서 연속된 레이블로 만들기
y_B = (y[y_5_or_6] == 6).astype(np.float32)
return ((X[~y_5_or_6], y_A), (X[y_5_or_6], y_B))(X_train_A, y_train_A), (X_train_B, y_train_B) = split_dataset(X_train, y_train)
(X_valid_A, y_valid_A), (X_valid_B, y_valid_B) = split_dataset(X_valid, y_valid)
(X_test_A, y_test_A), (X_test_B, y_test_B) = split_dataset(X_test, y_test)
X_train_B = X_train_B[:200]
y_train_B = y_train_B[:200]X_train_A.shape #훈련 데이터 전체| (43986, 28, 28) |
X_train_B.shape #훈련 데이터 중 200개| (200, 28, 28) |
y_train_A[:50] #8가지 모양| array([4, 0, 5, 7, 7, 7, 4, 4, 3, 4, 0, 1, 6, 3, 4, 3, 2, 6, 5, 3, 4, 5, 1, 3, 4, 2, 0, 6, 7, 1, 3, 7, 0, 3, 7, 4, 2, 7, 0, 6, 3, 3, 2, 2, 0, 6, 3, 1, 7, 1], dtype=uint8) |
y_train_B[:50] #2가지 모양| array([1., 1., 0., 0., 0., 0., 1., 1., 1., 0., 0., 1., 1., 0., 0., 0., 0., 0., 0., 1., 1., 0., 0., 1., 1., 0., 1., 1., 1., 1., 1., 0., 1., 0., 1., 1., 1., 0., 1., 0., 0., 0., 1., 1., 1., 0., 1., 0., 0., 0.], dtype=float32) |
- 많은 양의 데이터로 모델 훈련
- 이 작업은 실제로는 우리는 검색하고 모델을 load 하면 됨
tf.random.set_seed(42)
np.random.seed(42)
#모델 생성
model_A = keras.models.Sequential()
#입력 층
model_A.add(keras.layers.Flatten(input_shape=[28, 28]))
#히든 층
for n_hidden in (300, 100, 50, 50, 50):
model_A.add(keras.layers.Dense(n_hidden, activation="selu"))
#출력 층
model_A.add(keras.layers.Dense(8, activation="softmax"))
model_A.compile(loss = "sparse_categorical_crossentropy",
optimizer=keras.optimizers.SGD(learning_rate=0.001),
metrics=['accuracy'])
history = model_A.fit(X_train_A, y_train_A, epochs=20,
validation_data=(X_valid_A, y_valid_A)) |
# 모델 저장
model_A.save("my_model_A.keras")#실제 해결을 하고자 하는 모델
model_B = keras.models.Sequential()
#입력 층
model_B.add(keras.layers.Flatten(input_shape=[28, 28]))
#히든 층
for n_hidden in (300, 100, 50, 50, 50):
model_B.add(keras.layers.Dense(n_hidden, activation="selu"))
#출력 층: 2개를 분류하는 것은 2가지 방법이 있음
#1일 확률을 구하는 것 과 0 과 1일 확률을 구하는 것
model_B.add(keras.layers.Dense(1, activation="sigmoid"))
model_B.compile(loss = "binary_crossentropy",
optimizer=keras.optimizers.SGD(learning_rate=0.001),
metrics=['accuracy'])
history = model_B.fit(X_train_B, y_train_B, epochs=20,
validation_data=(X_valid_B, y_valid_B)) |
- 기존 모델인 model_A를 이용해서 해결
#기존 모델 가져오기
model_A = keras.models.load_model("my_model_A.keras")
#기존 모델에서 출력 층을 제외한 레이어를 가져오기
model_B_on_A = keras.models.Sequential(model_A.layers[:-1])
#출력 층 추가
model_B_on_A.add(keras.layers.Dense(1, activation='sigmoid'))
#모든 레이어가 다시 훈련하지 않도록 설정
for layer in model_B_on_A.layers[:-1]:
layer.trainable = False
model_B_on_A.compile(loss = "binary_crossentropy",
optimizer=keras.optimizers.SGD(learning_rate=0.001),
metrics=['accuracy'])
history = model_B_on_A.fit(X_train_B, y_train_B, epochs=20,
validation_data=(X_valid_B, y_valid_B)) |
# 모든 레이어가 다시 훈련하도록 설정
#기존 모델에서 출력 층을 제외한 레이어를 가져오기
model_B_on_A = keras.models.Sequential(model_A.layers[:-1])
#출력 층 추가
model_B_on_A.add(keras.layers.Dense(1, activation='sigmoid'))
#모든 레이어가 다시 훈련하도록 설정
for layer in model_B_on_A.layers[:-1]:
layer.trainable = True
model_B_on_A.compile(loss = "binary_crossentropy",
optimizer=keras.optimizers.SGD(learning_rate=0.001),
metrics=['accuracy'])
history = model_B_on_A.fit(X_train_B, y_train_B, epochs=20,
validation_data=(X_valid_B, y_valid_B)) |
# 일반화 오차 비교
print(model_B.evaluate(X_test_B, y_test_B))
print(model_B_on_A.evaluate(X_test_B, y_test_B)) |
- 고속 옵티마이저 사용
- 모멘텀 최적화: SGD를 사용할 때 momentum 이라는 파라미터에 값을 설정하면 성능이 좋아짐
- 모멘텀 최적화에서 훈련 속도를 향상시키고자 할 때는 네스테로프 가속 경사를 이용하게 되는데 이 경우에는 use_nestrov=True를 추가
- Adagrad, RMSProp, Adam, Nadam 등의 옵티마이저가 추가
- 완전 연결층에 규제를 가하는 방법
- l1 이나 l2 규제를 추가
- kernel_regularizer 파라미터에 keras.regularizers.l1 이나 l2(값)
- Dropout
- 입력 뉴런은 그대로 사용하고 출력 뉴런은 임시적으로 Drop 될 확률을 설정
- 이전 레이어에서 전달되는 데이터를 일부분 제거하는 방식
- 확률은 일반적으로 10 ~ 50% 사이로 설정하는데 RNN에서는 20~30 정도로 설정하고 CNN에서는 40~50% 로 설정
- 이를 사용하고자 할 때는 Dropout 이라는 클래스에 rate로 확률을 설정
- 입력 층 앞에는 넣으면 안되고 입력층 다음부터 추가해서 사용
'Python' 카테고리의 다른 글
| [Python] 딥러닝 _ Tensorflow (0) | 2024.03.20 |
|---|---|
| [Python] 연관 분석 (0) | 2024.03.18 |
| [Python] 연관분석 실습 _ 네이버 지식인 크롤링 (4) | 2024.03.15 |
| [Python] 감성 분석 실습 (3) | 2024.03.14 |
| [Python] 차원 축소 (0) | 2024.03.12 |