
1. 문장의 유사도 측정
1-1) 코사인 유사도
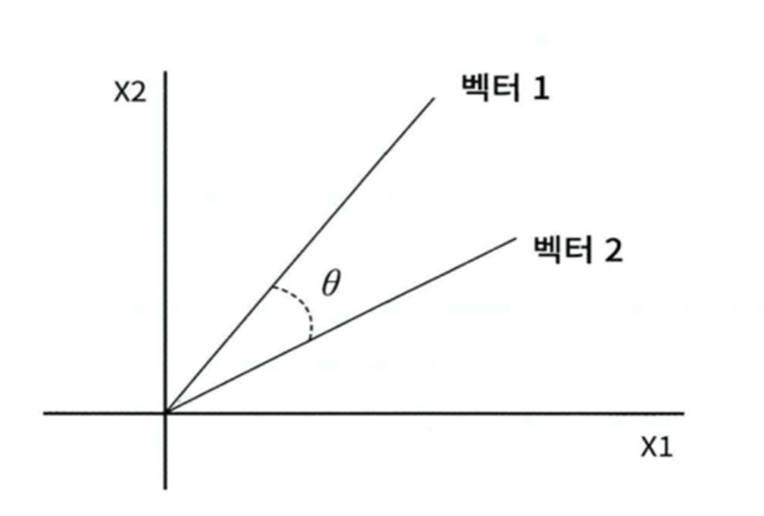
- 문장을 벡터로 만들어서 거리 측정
- 벡터의 크기보다는 벡터의 방향성이 얼마나 유사한지에 기반
- 두 벡터 사이의 사잇각을 구해서 얼마나 유사한지 수치로 적용
- 유사한 벡터들은 방향이 같고 관련성이 없는 벡터들은 방향이 일치하지도 않고 반대 방향도 아닌 경우
1-2) 코사인 유사도 API
- sklearn.feature_extration.text 패키지를 이용해서 전처리
- sklearn.metrics.pairwise 패키지의 cosin_similarity 함수를 이용해서 측정
def cos_similarity(v1, v2):
dot_product = np.dot(v1, v2)
l2_norm = (np.sqrt(sum(np.square(v1))) * np.sqrt(sum(np.square(v2))))
similarity = dot_product / l1_norm
return similarity
#피처 벡터화
doc_list = ['I love you', 'I like you', 'I love movie']
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vect_simple = TfidfVectorizer()
feature_vect_simple = tfidf_vect_simple.fit_transform(doc_list)
print(feature_vect_simple)| (0, 3) 0.7071067811865476 (0, 1) 0.7071067811865476 (1, 0) 0.7959605415681652 (1, 3) 0.6053485081062916 (2, 2) 0.7959605415681652 (2, 1) 0.6053485081062916 |
- shape : (3, 4) 3개의 문장 4개의 단어
- 'I'는 자동으로 불용어 처리함
- love you, like you, love movie 만 존재
# TFidfVectorizer로 transform()한 결과는 Sparse Matrix이므로 Dense Matrix로 변환
feature_vect_dense = feature_vect_simple.todense()
print(feature_vect_dense) |
# 밀집 행렬로 변환
- 희소행렬은 1인 것만의 데이터를 가져오기 떄문에 거리 계산이 불가하다. 그래서 밀집행렬 변환은 필수 작업
# TFidfVectorizer로 transform()한 결과는 Sparse Matrix이므로 Dense Matrix로 변환.
feature_vect_dense = feature_vect_simple.todense()
#첫번째 문장과 두번째 문장의 feature vector 추출
vect1 = np.array(feature_vect_dense[0]).reshape(-1,)
vect2 = np.array(feature_vect_dense[1]).reshape(-1,)
vect3 = np.array(feature_vect_dense[2]).reshape(-1,)
print(cos_similarity(vect1, vect2))
print(cos_similarity(vect1, vect3))
print(cos_similarity(vect2, vect3))| 0.4280460350631186 0.4280460350631186 0.0 |
- 유사도는 1이 가장 가깝고 0이 가장 멀다.
# API 활용
- 거리를 측정할 벡터 2개를 대입
from sklearn.metrics.pairwise import cosine_similarity
similarity_simple_pair = cosine_similarity(feature_vect_simple[0] , feature_vect_simple)
print(similarity_simple_pair)| [[1. 0.42804604 0.42804604]] |
- feature_vect_simple 전체와의 거리
- feature_vect_simple[n] n번째 문장과의 거리
- 희소행렬을 대입하면 밀집행렬로 변환해서 유사도 측정
1-3) 문서 군집에서 유사도 값이 큰 것끼리 묶기
# 한글 문장의 유사도 측정
### 훈련 데이터 만들기
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(min_df = 1)
contents = ['우리 김치찌개 먹으러 가자!',
'나는 고기김치찌개 좋아해.',
'계란찜도 좋아합니다.'
'먹고 나서 잠깐 산책할까?',
'산책하면서 라우브 신곡 듣고 싶어.']
#좋아해-좋아합니다. 다른 말로 인식하니 어근추출 해주기
from konlpy.tag import Okt
okt = Okt()
contents_tokens = [okt.morphs(row) for row in contents]
print(contents_tokens)| [['우리', '김치찌개', '먹으러', '가자', '!'], ['나', '는', '고기', '김치찌개', '좋아해', '.'], ['계란찜', '도', '좋아합니다', '.', '먹고', '나서', '잠깐', '산책', '할까', '?'], ['산책', '하면서', '라우', '브', '신곡', '듣고', '싶어', '.']] |
# 형태소 분석 후 문장 변환
contents_for_vectorize = []
for content in contents_tokens:
sentence = ''
for word in content:
sentence = sentence + ' ' + word
contents_for_vectorize.append(sentence)
print(contents_for_vectorize)| [' 우리 김치찌개 먹으러 가자 !', ' 나 는 고기 김치찌개 좋아해 .', ' 계란찜 도 좋아합니다 . 먹고 나서 잠깐 산책 할까 ?', ' 산책 하면서 라우 브 신곡 듣고 싶어 .'] |
tfidf_vect = TfidfVectorizer()
feature_vect = tfidf_vect.fit_transform(contents_for_vectorize)
print(tfidf_vect.get_feature_names_out())
print(feature_vect.toarray().transpose())| ['가자' '계란찜' '고기' '김치찌개' '나서' '듣고' '라우' '먹고' '먹으러' '산책' '신곡' '싶어' '우리' '잠깐' '좋아합니다' '좋아해' '하면서' '할까']  |
new_post = ['우리 김치찌개 먹자']
new_post_tokens = [okt.morphs(row) for row in new_post]
new_post_for_vectorize = []
for content in new_post_tokens:
sentence=''
for word in content:
sentence = sentence + ' ' + word
new_post_for_vectorize.append(sentence)
print(new_post_for_vectorize)
new_post_vec = tfidf_vect.transform(new_post_for_vectorize)
print(new_post_vec)| [' 우리 김치찌개 먹자'] (0, 12) 0.7852882757103967 (0, 3) 0.6191302964899972 |
cos_similarity_value = cosine_similarity(new_post_vec, feature_vect)
print(cos_similarity_value)| [[0.66914631 0.30147576 0. 0. ]] |
- '우리 김치찌개 먹으러 가자 !', ' 나는 고기김치찌개 좋아해 .', 두 문장에서 유사도가 나옴!
#가장 유사한 인덱스
print(np.argmax(cos_similarity_value))| 0 |
result = ['사과', '배', '한라봉', '천혜향', '감귤']
text = result[np.argmax(cos_similarity_value)]
print(text)| 사과 |
- 원래 챗봇은 {질문 : 답, 질문 : 답 .. } 형태로 해서 유사한 답을 반응하는 방식
2. Word2Vec
- 단어나 문장을 가지고 다음 단어를 예측하는 것
2-1) Continuous Bag of Words
- 여러개의 단어를 가지고 다음 단어를 예측하는 것
- 안녕하세요 반갑습니다 나는 오늘 응봉산을 오를 예정입니다.
- 위의 문장을 학습한 후 (나는 오늘 응봉산에) -> '오를' 을 예측
2-2) Skip-Gram
- 특정 단어를 가지고 다음 단어나 문장을 예측하는 것
- window size가 있어서 현재 위치에서 몇 개를 예측할 것인지 설정
- 안녕하세요 반갑습니다 나는 오늘 응봉산을 오를 예정입니다.
- window size가 1이면
- 나는 -> 오늘
- 나는 -> 반갑습니다
- window size가 2라면
- 나는 -> 오늘
- 나는 -> 반갑습니다.
- 나는 -> 신사역에
- 나는 -> 안녕하세요
2-3) API
- gensim 패키지에 Word2Vec 클래스로 구현
- similarity 함수를 이용해서 2개의 단어의 유사도를 측정해주고 most_similar 함수를 이용해서 가장 유사한 단어를 리턴,
- positive 인수와 negative 인수를 이용해서 단어간 관계도 찾을 수 있다.
2-4) 네이버 지식인 검색 결과 가장 유사한 단어 찾기
2024.03.15 - [Python] - [Python] 네이버 지식인 크롤링 _ 연관분석 실습
[Python] 네이버 지식인 크롤링 _ 연관분석 실습
1. 데이터 가져오기 # 고양이 질문 데이터 from bs4 import BeautifulSoup #HTML 파싱 import urllib #검색어 인코딩 import time #슬립 사용 import requests #HTML 가져오기 from tqdm import tqdm_notebook #크롤링 결과 저장할
yachae4910.tistory.com
3. 연관 규칙 분석
- 원본 데이터에서 대상들의 연관된 규칙을 찾는 무방향성 데이터마이닝 기법
- 하나의 거래나 사건에 포함된 항목 간의 관련성을 파악해서 둘 이상의 항목들로 구성된 연관성 규칙을 찾는 탐색적인 방법
- 트랜잭션을 대상으로 트랜잭션 내의 연관성을 분석해서 상품 거래의 규칙이나 패턴을 찾아 상품 간의 연관성을 도출해내는 분석 방법
- 장점
- 조건 반응 표현식의 결과를 이해하기 쉽다.
- 편리한 분석 데이터 형태
- 단점
- 계산 과정에서 연산 많이 수행
- 순차분석
- 연관 규칙 분석은 무방향성이라서 A를 산 사람이 B를 살 확률을 확인하는 것
- 순차분석은 A를 사고 B를 살 확률
- 시간의 개념이 있다.
3-1) 과정
- 거래 내역 데이터를 가지고 트랜잭션 객체 생성
- 품목과 트랜잭션 ID를 관찰
- 지지도, 신뢰도, 향상도를 이용한 연관 규칙 발견
- 시각화
- 업무 적용
3-2) 평가지표
- Support(지지도)
- 전체 거래 건수 중에서 X와 Y가 모두 포함된 건수의 비
- X와 Y 모두 포함한 거래 건수 / 전체 거래 건수
- 전체 품목에서 관련 품목의 거래 확률
- 지지도가 낮다는 것은 해당 규칙이 자주 발생하지 않는다는 의미
- Confidence(신뢰도)
- X를 구매한 거래 중에서 Y를 포함하는 거래의 건수 비
- X와 Y 모두 포함한 거래 건수 / X를 포함하는 거래 건수
- Lift(향상도)
- 신뢰도를 지지도로 나눈 값
- 두 항목의 독립성 여부를 판단하는 수치
- 1이면 서로 독립, 1보다 작으면 음의 상관관계, 1보다 크면 양의 상관관계 의미
값이 클수록 연관성이 높은 것
3-3) API
- apyori 패키지 apriri 모듈
- min_support
- min_confidence
- min_lift
- 일반 텍스트 데이터에 적용 가능
3-4) network 패키지
- 그래프를 다루기 위한 패키지
- 그래프를 만드는 클래스
- Graph: 방향이 없음
- DiGraph: 방향성 그래프
- node와 edge로 구성
2024.03.15 - [Python/Python 실전편] - [Python] 연관분석 실습 _ 손흥민
[Python] 연관분석 실습 _ 손흥민
설치 !pip install apyori 1. 데이터 읽어오기 df = pd.read_csv("./python_machine_learning-main/data/tweet_temp.csv") df.head() #한글 정제 함수 import re # 한글만 추출 def text_cleaning(text): hangul = re.compile('[^ ㄱ-ㅣ가-힣]+') #
yachae4910.tistory.com
4. 추천 시스템
4-1) 추천 시스템 알고리즘
- 콘텐츠 기반 필터링
- 협업 필터링
- 최근접 이웃 협업 필터링
- 잠재 요인 협업 필터링
초창기에는 콘텐츠 기반 필터링이나 최근접 이웃 협업 필터링을 주로 이용햇는데 넷플릭스의 추천 시스템이 행렬 분해 기법을 이용한 잠재 요인 협업 필터링을 사용하면서 최근에는 잠재 요인 협업 필터링을 주로 이용하고 두가지 알고리즘을 혼합해서 사용
4-2) 콘텐츠 기반 필터링
- 사용자가 특정한 아이템을 선호하는 경우 그 아이템과 비슷한 콘텐츠를 가진 다른 아이템을 추천하는 방식
- 어떤 영화를 보고 추천하거나 높은 평점을 제시한 경우 그 영화의 장르나 배우, 감독 등을 파악해서 유사한 다른 영화 추천
2024.03.15 - [Python/Python 실전편] - [Python] 연관분석 실습 _ 영화 콘텐츠 기반 필터링 추천 시스템
[Python] 연관분석 실습 _ 영화 콘텐츠 기반 필터링 추천 시스템
데이터 https://www.kaggle.com/tmdb/tmdb-movie-metadata 1. 데이터 읽어오기 movies =pd.read_csv('./python_machine_learning-main/data/tmdb_5000_movies.csv') print(movies.shape) movies.head() # 데이터 생성 movies_df = movies[['id','title', 'genr
yachae4910.tistory.com
4-3) 협업 필터링
- 사용자가 아이템에 매긴 평점 정보나 상품 구매 이력같은 사용자 행동 양식만을 기반으로 추천
- 사용자-아이템 평점 매트릭스와 같은 축적된 사용자 행동 데이터를 기반으로 사용자가 아직 평가하지 않은 아이템을 예측 평가하는 것
| ITEM 1 | ITEM 2 | ITEM 3 | ITEM 4 | |
| USER 1 | 3 | 3 | ||
| USER 2 | 4 | 2 | 3 | |
| USER 3 | 1 | 2 | 2 |
- USER 1은 USER2 와 USER3의 선택에서 겹치는게 있다. (ITEM1, ITEM3)
=> ITEM 4 추천
- 최근접 이웃 협업 필터링
- 사용자 기반: 나와 유사한 고객의 다음 상품도 구매하도록 만듦
- 사용자 A는 B와 다크나이트, 인터스텔라, 엣지오브투모로우에서 비슷한 평점을 줬기 때문에
- 사용자 A에게 프로메테우스를 추천해준다.
- 단점: 로그인해서 평점을 축적해야 한다.

- 아이템 기반: 이 상품을 선택한 다른 고객들은 다음 상품도 구매
- 로그인 하지 않아도 '이 책을 구입하신 분들이 함께 산 책' 등을 추천해줄 수 있다.
- 그래서 많은 기업들이 선호한다. 쿠팡, 당근 등

- 잠재 요인 협업 필터링
- 사용자-아이템 평점 매트릭스 속에 숨어있는 잠재 요인을 추출해서 추천 예측을 할 수 있게 하는 기법
- 최근접 이웃 협업 필터링을 실무에서 사용하기 어려운 이유는 사용자와 유사한 아이템을 구매한 사용자를 찾는 것은 쉽지 않다.
- 쇼핑몰이나 넷플릭스 같은 OTT 기업의 데이터는 굉장히 많아서 내가 산 상품을 전부 산, 또는 내가 본 영화를 전부 본 유저를 찾기는 쉽지 않다.

- 원본 데이터와 100% 같지는 않다.
- 원본 행렬을 가지고 주성분분석을 해서 작은 단위의 밀집 행렬 3개를 만들고 (SV, MNF 등)
- 다시 내적(product)하면 값이 채워짐.
2024.03.18 - [Python/Python 실전편] - [Python] 연관분석 실습 _ 아이템 기반 추천 시스템
[Python] 연관분석 실습 _ 아이템 기반 추천 시스템
- movies.csv: 영화 정보 데이터 - ratings.csv: 평점정보 데이터 1. 데이터 읽어오기 movies = pd.read_csv('./python_machine_learning-main/data/movielens/movies.csv') ratings = pd.read_csv('./python_machine_learning-main/data/movielens/rati
yachae4910.tistory.com
5. 행렬 분해
- 하나의 행렬을 특정한 구조를 가진 2개 이상의 행렬의 곱으로 표현하는 것
- 선형 방정식으 해를 구하거나 행렬 계산을 효율적으로 수행하기 위해서 사용
데이터 전처리에서는 None 값을 채우는 용도로 사용하기도 함
5-1) 알고리즘
- SVD(Singular Value Decompsition) : 특잇값 분해
- NMF(Non-Negative Matrix Fatorization) : 음수 미포함 행렬 분해
- SGD(Stochastic Gradient Descent) : 경사하강법
- ALS(Alterating Least Square)
5-2) SVD
- N * M 크기의 행렬 A를 3개의 행렬 곱으로 나타내는 것
- A(M * N) = U(M * N) 시그마(M * N) V(N * N)의 역행렬
- 제약조건
- U와 V는 정방행렬 ( 행과 열의 개수가 같은 행렬 )
- U와 V는 직교행렬 ( 자신의 역행렬과 곱을 하면 단위 행렬이 나옴 )
from numpy.linalg import svd
A = np.array([[3, -1], [1, 3], [1, 1]])
U, S, VT = svd(A)
print(U) #행이 3개이므로 3*3 행렬
print(VT) #열이 2개이므로 2*2 행렬
print(S) #2개의 값| [[-4.08248290e-01 8.94427191e-01 -1.82574186e-01] [-8.16496581e-01 -4.47213595e-01 -3.65148372e-01] [-4.08248290e-01 -1.94289029e-16 9.12870929e-01]] [3.46410162 3.16227766] [[-0.70710678 -0.70710678] [ 0.70710678 -0.70710678]] |
# 3개 행렬의 곱
- U @ S @ V는 안됨
- 사이즈가 다르기 때문
temp = np.diag(S, 0)
print(temp)| [[3.46410162 0. ] [0. 3.16227766]] |
- 2*2가 만들어진다.
- 그래서 옆으로 하나 더 밀어야 함
temp = np.diag(S, 1)[:, 1:]
U @ temp @ VT| array([[ 3., -1.], [ 1., 3.], [ 1., 1.]]) |
5-3) NMF
- 음수 미포함 행렬 분해
- 음수를 포함하지 않는 행렬 V를 음수 포함하지 않는 행렬 W와 H의 곱으로 분해
X = WH
- W 는 X와 동일한 모양으로 생성
- H는 열의 개수만큼의 행을 가지게 되고 데이터의 demension만큼의 열을 소유
- W는 가중치 행렬 (Weight Matrix)라고 하고 H는 특성 행렬(Feature Matrix)이라고 함
- W는 카테고리 특성의 관계를 나타내는 것이고 특성 행렬은 원래 특성에 대비한 새로운 특성에 대한 관계를 나타냄
- 차원 축소나 새로운 차원을 생성할 때도 이용
5-4) 경사 하강법
- GPU를 사용하는 것이 가능하고 결측치에 상관없이 사용 가능
- 이전 2가지 방법은 결측치가 있으면 0으로 채워서 수행해야 함
5-5) ALS (Alternating Least Square)
- 경사 하강법은 2개의 동시에 변경하면서 최적의 값을 찾아가지만 ALS는 하나의 행렬은 고정하고 다른 하나의 행렬만 변경하면 최적의 값을 찾아가는 방식
- 결측치가 있으면 안되기 때문에 결측치가 있으면 0으로 채워서 사용해야 함
5-6) 사용
- 행렬 분해에는 SVD가 자주 사용되지만 사용자-평점데이터를 가지고 행렬 분해를 하고자 하는 경우에는 None 값이 너무 많기 때문에 SGD나 ALS를 주로 이용
- 행렬분해를 이용해서 시청하지 않은 또는 구매하지 않은 상품에 대한 점수를 예측하는 방식을 잠재요인 협업 추천이라고 함
- 넷플릭스가 영화 추천에 사용하면서 유명해진 방식
- 행렬 분해 알고리즘을 이용해서 추천 시스템을 구축해주는 패키지 중의 하나로 scikit-surprise가 있고, 그 이외에 딥러닝을 이용하는 방식도 있다.
- scikit-surprise 패키지는 Dataset 클래스를 이요해서만 데이터 로딩이 가능하고 데이터가 반드시 userid, itemid, rating의 형태를 갖는 row로 구성되어 있어야 함
- 일반 파일로 만들어진 데이터가 있다면 row 형태를 맞추고 surprise.Reader라는 클래스를 이용해서 Dataset의 형태로 변경해야 가능
- 요즘은 이 방식들을 잘 사용하지 않고 lightFM 같은 딥러닝 모델들을 이용하는 경우가 많다.
- 추천 시스템을 만들고자 하는 경우는 여러 모델을 사용해보는 것이 좋다.
- 일반적으로 추천 시스템은 평가를 하기가 어렵기 때문에 여러 모델을 사용해서 추천 목록을 만드는 것이 좋다.
'Python' 카테고리의 다른 글
| [Python] 딥러닝 _ Keras (0) | 2024.03.20 |
|---|---|
| [Python] 딥러닝 _ Tensorflow (0) | 2024.03.20 |
| [Python] 연관분석 실습 _ 네이버 지식인 크롤링 (4) | 2024.03.15 |
| [Python] 감성 분석 실습 (3) | 2024.03.14 |
| [Python] 차원 축소 (0) | 2024.03.12 |