cctv.rename(columns={cctv.columns[0] : '구별'}, inplace=True)
print(cctv.head())
print()
gu = []
for x in cctv['구별']:
gu.append(x.replace(' ', ''))
cctv['구별'] = gu
pop.rename(columns={pop.columns[1] : '구별'}, inplace=True)
print(pop.head())
# 필터링
#pop에서 컬럼 추출
pop = pop[['기간', '구별', '계', '남자', '여자']]
#pop의 첫번째 행은 합계
#첫번째 행 제거
pop.drop([0], inplace=True)
#여성인구 비율을 알아보기 위해서 새로운 열 생성
pop['여성비율'] = pop['여자']/pop['계']*100
pop
# 병합
#구별 컬럼을 이용해서 2개의 frame을 합치기
df = pd.merge(cctv, pop, on='구별')
# 불필요한 컬럼 제거
del df['2011년 이전']
del df['2012년']
del df['2013년']
del df['2014년']
del df['2015년']
del df['2016년']
del df['2017년']
del df['기간']
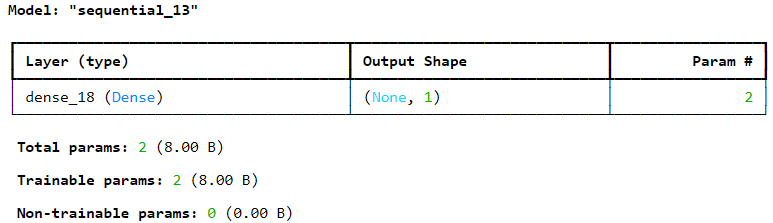
Sequential API를 이용해서 회귀용 MLP을 구축, 훈련, 평가, 예측하는 방법은 분류에서 했던 것 과 매우 비슷하지만
차이점은 출력 층이 활성화 함수가 없는 하나의 뉴런을 가져야 한다는 것, 손실 함수가 평균 제곱 오차나 평균 절대값 오차로 변경을 해야 함
import tensorflow as tf
from tensorflow import keras
#회귀 모델 만들기
#input_shape 설정할 때 데이터의 개수는 생략
model = keras.models.Sequential([
keras.layers.Dense(30, activation="relu", input_shape=X_train.shape[1:]),
keras.layers.Dense(15, activation="relu"),
keras.layers.Dense(units=1)
])
model.summary()
#여러 경로의 input 사용
input_A = keras.layers.Input(shape=[5])
input_B = keras.layers.Input(shape=[6])
hidden1 = keras.layers.Dense(30, activation="relu")(input_B)
hidden2 = keras.layers.Dense(15, activation="relu")(hidden1)
#input_A는 하나의 hidden 층도 통과하지 않은 데이터
# hidden2는 2개의 hidden 층을
#통과한 데이터
concat = keras.layers.concatenate([input_A, hidden2])
output = keras.layers.Dense(1)(concat)
#입력을 2가지를 사용 - 데이터의 다양성을 추가해서 학습
#모든 입력이 hidden layer를 통과하게 되면 깊이가 깊어질 때 데이터의 왜곡 발생 가능
model = keras.models.Model(inputs=[input_A, input_B], outputs=[output])
#출력이 2개가 된 경우 손실을 적용할 때 비율을 설정하는 것이 가능
#이 경우는 첫번째 출력의 손실을 90% 반영하고 두번째 출력의 손실을 10% 반영
model.compile(loss="mse", optimizer=keras.optimizers.SGD(learning_rate=0.001),
loss_weights=[0.9, 0.1])
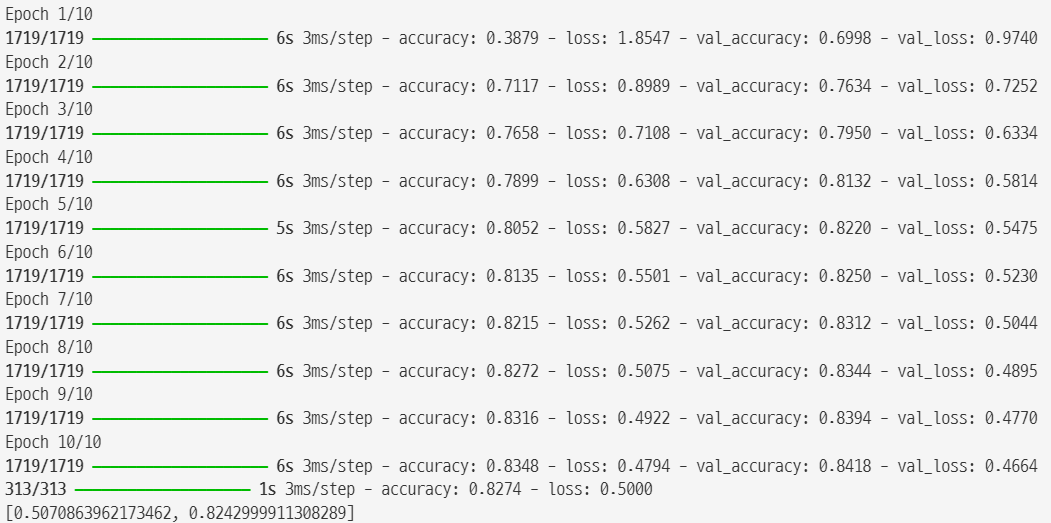
history = model.fit((X_train_A, X_train_B), y_train,
epochs=20, validation_data=((X_valid_A, X_valid_B), y_valid))
X_new_A, X_new_B = X_test_A[:3], X_test_B[:3]
#출력이 2개 이므로 각 데이터마다 2개의 값을 리턴
y_pred_main, y_pred_aux = model.predict([X_new_A, X_new_B])
print(y_pred_main)
print(y_pred_aux)
epochs 을 크게 지정하면 훈련을 많이 수행하기 때문에 성능이 좋아질 가능성이 높은데 늘리게 되면 훈련 시간이 오래 걸린다.
일정 에포크 동안 검증 세트에 대한 점수가 향상되지 않으면 훈련을 멈추도록 할 수 있다.
keras.callbacks.EarlyStopping 클래스의 인스턴스를 만들 때 patience 매개변수에 원하는 에포크 지정해서 만들고 모델이 fit 메서드를 호출할 때 callbacks 파라미터에 list 형태로 대입하면 됨
#5번의 epoch 동안 점수가 좋아지지 않으면 조기 종료
early_stopping_cb = keras.callbacks.EarlyStopping(patience=5)
history = model.fit((X_train_A, X_train_B), y_train,
epochs=100, validation_data=((X_valid_A, X_valid_B), y_valid),
callbacks=[early_stopping_cb])
LearningRateScheduler 라는 클래스를 이용하는데 이 때는 에포크 와 학습율을 매개변수로 갖는 함수를 만들어서 인스턴스를 생성할 때 대입
#5번의 epoch 동안 점수가 좋아지지 않으면 조기 종료
early_stopping_cb = keras.callbacks.EarlyStopping(patience=5)
#5번의 epoch 동안은 기존 학습률을 유지하고 그 이후에는 학습률을 감소시키는 함수
def scheduler(epoch, lr):
if epoch < 5:
return lr
else:
lr = lr - 0.0001
return lr
#학습률을 동적으로 변화시키는 체크포인트
lr_scheduler = tf.keras.callbacks.LearningRateScheduler(scheduler)
history = model.fit((X_train_A, X_train_B), y_train,
epochs=100, validation_data=((X_valid_A, X_valid_B), y_valid),
callbacks=[early_stopping_cb, lr_scheduler])
- 모델 저장과 복원
딥러닝은 fit 함수를 호출한 후 다음에 다시 fit을 호출하면 이전에 훈련한 이후 부터 다시 훈련하는 것이 가능
- on_train_begin, on_train_end, on_epoch_begin, on_epoch_end, on_batch_bigin, on_batch_end 이 메서드들은 훈련전후 그리고 한 번의 에포크 전후 그리고 배치 전후에 작업을 수행시키고자 하는 경우에 사용
on_test 로 시작하는 메서드를 오버라이딩 하면 검증 단계에서 작업을 수행
3-6) 신경망의 하이퍼 파라미터 튜닝
- 신경망의 유연성은 단점이 되기도 하는데 조정할 하이퍼 파라미터가 많음
- 복잡한 네트워크 구조에서 뿐 만 아니라 간단한 다층 퍼셉트론에서도 층의 개수, 층마다 존재하는 뉴런의 개수, 각 층에서 사용하는 활성화 함수, 가중치 초기화 전략 등 많은 것을 바꿀 수 있는데 어떤 하이퍼 파라미터 조합이 주어진 문제에 대해서 최적인지 확인
- 이전 머신러닝 모델들은 GridSearchCV 나 RandomizedSearchCV를 이용해서 하이퍼 파라미터 공간을 탐색할 수 있었는데 딥러닝에서는 이 작업을 할려면 Keras 모델을 sklearn 추정기 처럼 보이도록 바꾸기
def build_model(n_hidden=1, n_neurons=30, learning_rate=0.003, input_shape=[8]):
model = keras.models.Sequential()
#입력 레이어 추가
model.add(keras.layers.InputLayer(input_shape=input_shape))
#n_hidden 만큼 히든 층 추가
for layer in range(n_hidden):
model.add(keras.layers.Dense(n_neurons, activation="relu"))
#출력 층 추가
model.add(keras.layers.Dense(1))
#최적화 함수 생성
optimizer = keras.optimizers.SGD(learning_rate = learning_rate)
model.compile(loss="mean_squared_error", optimizer=optimizer, metrics=['mse'])
return model
배치 정규화를 이용하면 일부 뉴런이 죽는 현상을 거의 해소하기 때문에 성능이 좋아질 가능성이 높다.
- 그라디언트 클리핑
역전파 될 때 일정 임계값을 넘어서는 못하게 그라디언트를 잘라 내는 것
RNN 에서는 배치 정규화를 사용하기가 어려움
이 경우에는 Optimizer를 만들 때 clipvalue 나 clipnorm 매개변수를 이용해서 Gradient 값을 제한하는 방법으로 유사한 효과를 나타낸다.
배치 정규화가 -1 ~ 1 사이의 값으로 정규화하므로 임계값은 1.0을 사용한다.
그라디언트의 값이 -1 보다 작거나 1보다 크면 -1 이나 1로 수정해서 기울기가 소실되는 것을 방지
- 사전 훈련된 층 재사용
전이학습 (Transfer Learning) : 큰 규모의 NN을 처음부터 훈련시키는 것은 많은 자원을 소모하게 되는데 이런 경우 해결하려는 것과 비슷한 유형의 문제를 처리한 신경망이 있는지 확인해보고 그 신경망의 하위층을 재사용하는 것이 효율적
전이 학습을 이용하게 되면 훈련 속도를 개선할 수 있고 훈련 데이터의 양도 줄어들게 된다.
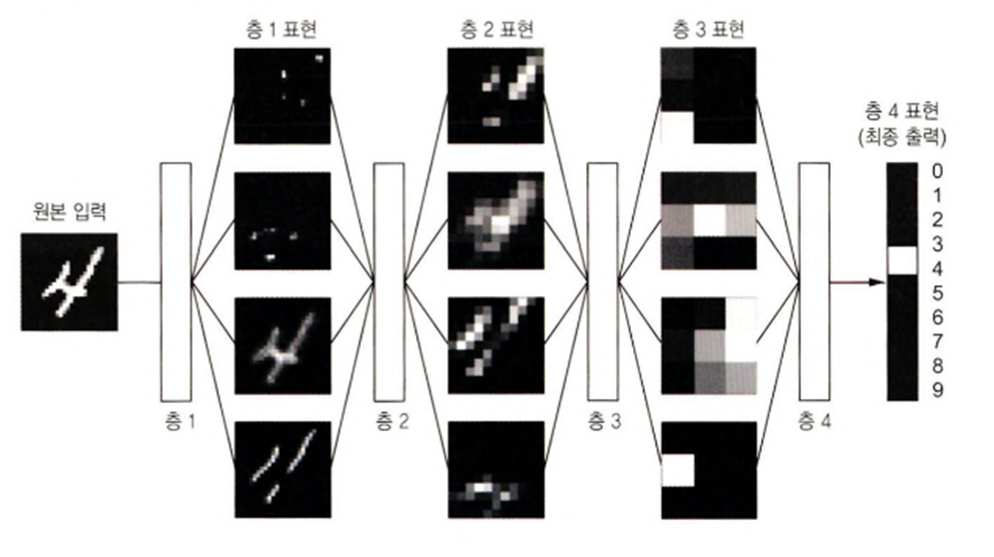
동일한 이미지 분류 모델이라면 하위 층에서 유사하게 점이나 선 들의 모형을 추출하는 작업을 할 가능성이 높으므로 하위 층을 공유해도 유사한 성능을 발휘하게 된다.
출력 층은 하고자 하는 마지막 작업이 서로 다를 가능성이 높고(ImageNet 의 이미지를 분류하는 모델은 20,000 개의 카테고리를 가지고 있고 우리는 개와 고양이를 분류하는 이진 분류의 경우) 상위 층은 거의 출력 과 유사한 형태가 만들어 진 것이므로 역시 재사용할 가능성은 낮다.
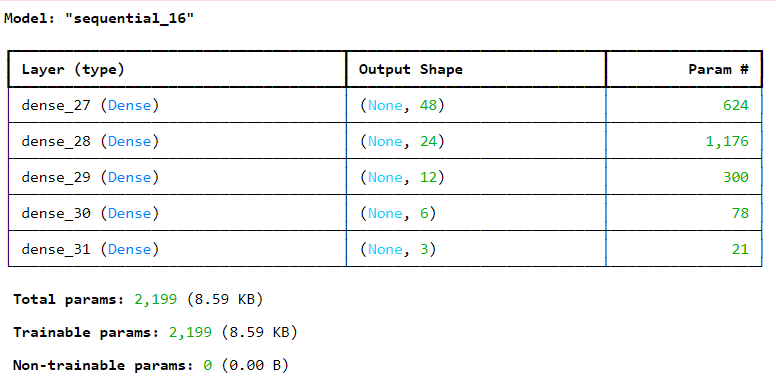
샌달 과 셔츠를 제외한 모든 이미지를 가지고 분류 모델을 만들고 이를 이용해서 샌달과 셔츠 이미지 중 200개 만 가진 작은 훈련 세트를 훈련해서 정확도를 확인
#데이터 셋 분할
def split_dataset(X, y):
y_5_or_6 = (y == 5) | (y == 6)
#5 나 6이 아닌 데이터
y_A = y[~y_5_or_6]
y_A[y_A > 6] -= 2 #6보다 큰 레이블은 2를 빼서 연속된 레이블로 만들기
y_B = (y[y_5_or_6] == 6).astype(np.float32)
return ((X[~y_5_or_6], y_A), (X[y_5_or_6], y_B))
tf.random.set_seed(42)
np.random.seed(42)
#모델 생성
model_A = keras.models.Sequential()
#입력 층
model_A.add(keras.layers.Flatten(input_shape=[28, 28]))
#히든 층
for n_hidden in (300, 100, 50, 50, 50):
model_A.add(keras.layers.Dense(n_hidden, activation="selu"))
#출력 층
model_A.add(keras.layers.Dense(8, activation="softmax"))
model_A.compile(loss = "sparse_categorical_crossentropy",
optimizer=keras.optimizers.SGD(learning_rate=0.001),
metrics=['accuracy'])
history = model_A.fit(X_train_A, y_train_A, epochs=20,
validation_data=(X_valid_A, y_valid_A))
# 모델 저장
model_A.save("my_model_A.keras")
#실제 해결을 하고자 하는 모델
model_B = keras.models.Sequential()
#입력 층
model_B.add(keras.layers.Flatten(input_shape=[28, 28]))
#히든 층
for n_hidden in (300, 100, 50, 50, 50):
model_B.add(keras.layers.Dense(n_hidden, activation="selu"))
#출력 층: 2개를 분류하는 것은 2가지 방법이 있음
#1일 확률을 구하는 것 과 0 과 1일 확률을 구하는 것
model_B.add(keras.layers.Dense(1, activation="sigmoid"))
model_B.compile(loss = "binary_crossentropy",
optimizer=keras.optimizers.SGD(learning_rate=0.001),
metrics=['accuracy'])
history = model_B.fit(X_train_B, y_train_B, epochs=20,
validation_data=(X_valid_B, y_valid_B))
- 기존 모델인 model_A를 이용해서 해결
#기존 모델 가져오기
model_A = keras.models.load_model("my_model_A.keras")
#기존 모델에서 출력 층을 제외한 레이어를 가져오기
model_B_on_A = keras.models.Sequential(model_A.layers[:-1])
#출력 층 추가
model_B_on_A.add(keras.layers.Dense(1, activation='sigmoid'))
#모든 레이어가 다시 훈련하지 않도록 설정
for layer in model_B_on_A.layers[:-1]:
layer.trainable = False
model_B_on_A.compile(loss = "binary_crossentropy",
optimizer=keras.optimizers.SGD(learning_rate=0.001),
metrics=['accuracy'])
history = model_B_on_A.fit(X_train_B, y_train_B, epochs=20,
validation_data=(X_valid_B, y_valid_B))
# 모든 레이어가 다시 훈련하도록 설정
#기존 모델에서 출력 층을 제외한 레이어를 가져오기
model_B_on_A = keras.models.Sequential(model_A.layers[:-1])
#출력 층 추가
model_B_on_A.add(keras.layers.Dense(1, activation='sigmoid'))
#모든 레이어가 다시 훈련하도록 설정
for layer in model_B_on_A.layers[:-1]:
layer.trainable = True
model_B_on_A.compile(loss = "binary_crossentropy",
optimizer=keras.optimizers.SGD(learning_rate=0.001),
metrics=['accuracy'])
history = model_B_on_A.fit(X_train_B, y_train_B, epochs=20,
validation_data=(X_valid_B, y_valid_B))
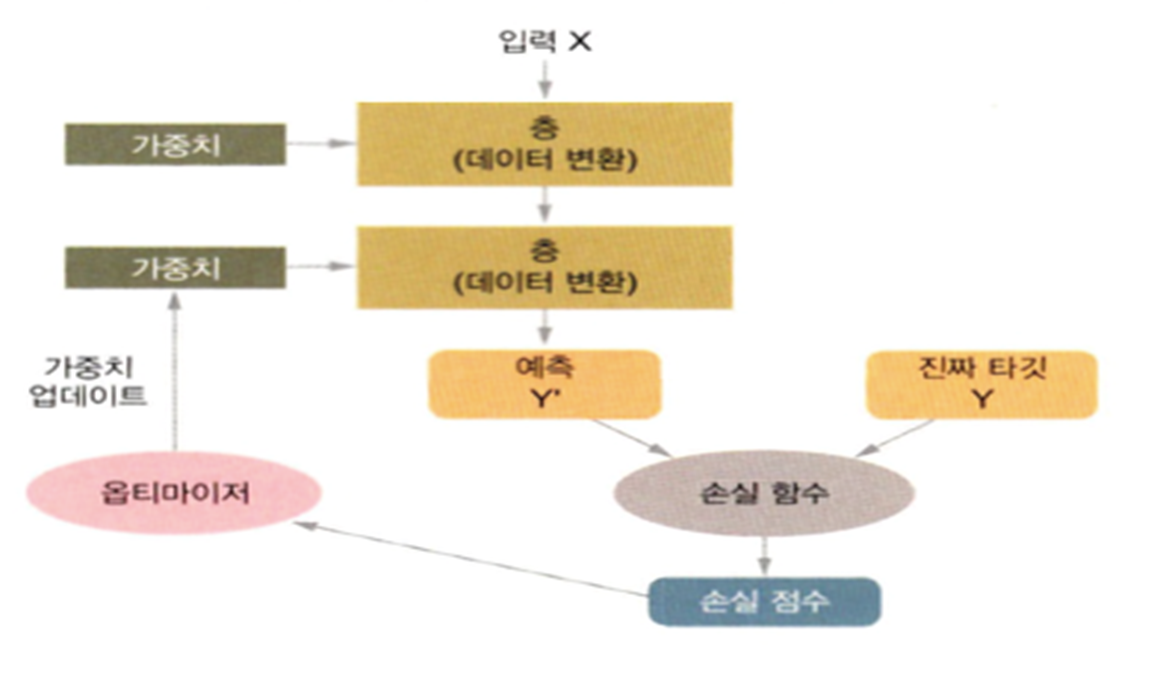
손실을 낮추기 위해서 신경망의 가중치 와 학습률 등의 신경망의 속성을 변경하는데 사용되는 최적화 방식
종류
SGD(확률적 경사하강법)
RMSprop
Adam: 가장 많이 사용되는 알고리즘으로 좋은 성능을 내는 것으로 알려져 있음
Adadelta
Adagrad
Nadam
Ftrl
- 평가 지표
분류: auc, precision, recall, accuracy
회귀: mse, mae, rmse
6. 모델 complie
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 모델 훈련
history = model.fit(X_train, y_train, epochs=30,
validation_data = (X_valid, y_valid))
#80%에 해당하는 인덱스 구하기
train_idx = int(len(wine_np) * 0.8)
#80% 기준으로 훈련 데이터 와 테스트 데이터 분리
train_X, train_Y = wine_np[:train_idx, :-1], wine_np[:train_idx, -1]
test_X, test_Y = wine_np[train_idx:, :-1], wine_np[train_idx:, -1]
#타겟을 원핫인코딩을 수행
train_Y = tf.keras.utils.to_categorical(train_Y, num_classes=2)
test_Y = tf.keras.utils.to_categorical(test_Y, num_classes=2)
print(train_Y[0])
[0. 1.]
일반 머신러닝 알고리즘에서는 타겟을 원핫인코딩 하지 않음
6. 분류 모델 생성
- 마지막 층의 units 은 출력하는 데이터의 개수로 회귀는 1 분류는 2 이상 - 분류 문제의 activation 은 softmax를 많이 사용
- tensorflow나 numpy에서 배열을 가지고 산술연산을 하는 경우 실제로는 함수 호출
python 에서는 __이름__ 형태로 메서드를 만드는 경우가 있는데 이러한 함수들은 Magic Function 이라고 부르는데 사용을 할 때 메서드 이름을 호출하는 것이 아니라 다른 연산자를 이용한다.
이렇게 연산자의 기능을 변경하는 것을 연산자 오버로딩
객체 지향에서만 가능합니다.
+ 는 숫자 두 개를 더하는 기능을 가지고 있는데 tensorflow 나 numpy 에서는 __add__를 정의해서 이 메서드를 호출하도록 한다.
- 이름이 다른 함수도 있음
np.mean -> tf.reduce_mean
- tf.float32 는 제한된 정밀도를 갖기 때문에 연산을 할 때 마다 결과가 달라질 수 있음
- 동일한 기능을 하는 함수나 클래스를 Keras 가 별도로 소유하고 있는 경우도 있음
Keras는 Tensorflow 의 저수준 API(Core 에 가까운 쪽)
4-3) Tensor와 numpy의 ndarray
2개의 데이터 타입은 호환이 되서 서로 변경이 가능
Tensor를 ndarray 로 변환하고자 하는 경우는 numpy() 메서드를 호출해도 되고 numpy 의 array 함수에 Tensor를 대입해도 된다.
ndarray를 가지고 Tensor를 만들고자 할 때는 contant 나 variable 같은 함수에 대입
ar = np.array([2, 3, 4])
print(tf.constant(ar))
tf.Tensor([2 3 4], shape=(3,), dtype=int32)
ar = np.array([2, 3, 4])
print(tf.constant(ar))
[2 3 4] [2 3 4]
4-4) 타입 변환
Data Type이 성능을 크게 감소시킬 수 있음
Tensorflow 는 타입을 절대로 자동 변환하지 않는다.
데이터 타입이 다르면 연산이 수행되지 않음
타입이 다른데 연산을 수행하고자 하는 경우에는 tf.cast 함수를 이용해서 자료형을 변경해야 함
Tensorflow 가 형 변환을 자동으로 하지 않는 이유는 사용자가 알지 못하는 작업은 수행을 하면 안된다는 원칙 때문
#ndarray는 이렇게 자료형이 다른 경우 자동으로 자료형을 변경해서 연산을 수행
print(np.array([1, 2, 3]) + np.array([1.6, 2.3, 3.4]))
[2.6 4.3 6.4]
#자료형이 달라서 에러가 발생
print(tf.constant(2.0) + tf.constant(40))
InvalidArgumentError: cannot compute AddV2 as input #1(zero-based) was expected to be a float tensor but is a int32 tensor [Op:AddV2] name:
t1 = tf.constant(40)
#형 변환 한 후 연산 수행
print(tf.constant(2.0) + tf.cast(t1, tf.float32))
tf.Tensor(42.0, shape=(), dtype=float32)
4-5) 변수
일반적인 데이터는 직접 변경을 하지 않기 때문에 constant 로 생성해서 사용하면 되는데 역전파 알고리즘을 수행하게 되면 가중치가 업데이트된다고 했는데 가중치는 수정되어야 하기 때문에 constant로 생성되면 안됨
수정되어야 하는 데이터는 tf.Variable 을 이용해서 생성
데이터를 수정하고자 하는 경우는 assign 함수를 이용
assign_add 나 assign _sub를 이용해서 일정한 값을 더하거나 빼서 수정할 수 있음
배열의 일부분을 수정할 때는 assign 함수나 scatter_update() 나 scatter_nd_update ()를 이용
#변수 생성
v = tf.Variable([[1, 2, 3], [4, 5, 6]])
print(v)
print(id(v))
#이 경우는 데이터를 수정한 것이 아니고
#기존 데이터를 복제해서 연산을 수행한 후 그 결과를 가리키도록 한 것
#참조하는 위치가 변경됨
v = v * 2
print(v)
print(id(v))
#내부 데이터 수정
v = tf.Variable([[1, 2, 3], [4, 5, 6]])
print(v)
print(id(v))
#이 경우는 id 변경없이 데이터를 수정
v.assign(2 * v)
print(v)
print(id(v))
SparseTensor: 0이 많은 Tensor를 효율적으로 나타내는데 tf.sparse 패키지에서 이 Tensor에 대한 연산을 제공
TensorArray: Tensor의 list
RaggedTensor: list 의 list
stringtensor: 문자열 텐서인데 실제로는 바이트 문자열로 저장됨
set
queue
4-7) Tensorflow 함수
일반 함수는 python 의 연산 방식에 따라 동작하지만 Tensorflow 함수를 만들게 되면 Tensorflow 프레임워크가 자신의 연산 방식으로 변경해서 수행을 하기 때문에 속도가 빨라질 가능성이 높음
- 생성방법
함수를 정의한 후 tf.function 이라는 decorator를 추가해도 되고 tf.function 함수에 함수를 대입해서 리턴받아도 됨
함수를 변경하는 과정에서 Tensorflow 함수로 변경이 불가능하면 일반 함수로 변환
4-8) 난수 생성
tf.random 모듈을 이용해서 난수를 생성
5. 뉴런 생성
뉴런을 추상화하면 Perceptron
5-1) 입력 -> 뉴런 -> 출력
이런 여러 개의 뉴런이 모이면 Layer 라고 하며 이런 Layer의 집합이 신경망
5-2) 뉴런의 구성
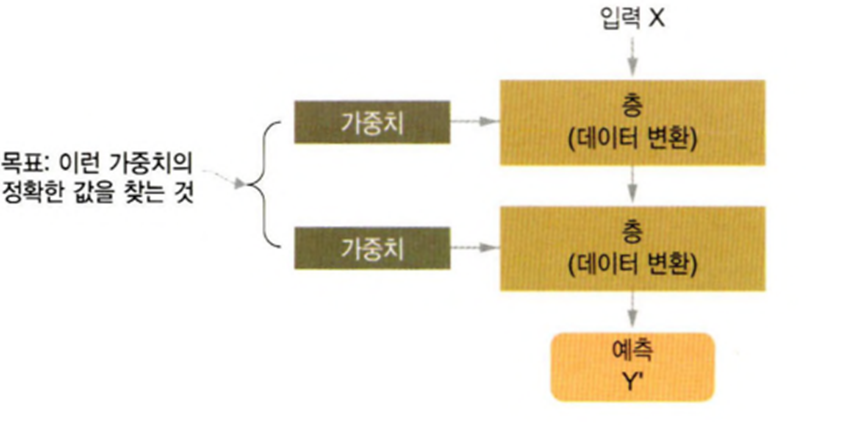
입력, 가중치, 활성화 함수, 출력으로 구성
입력과 가중치와 출력은 일반적으로 정수나 실수
활성화 함수는 뉴런의 출력 값을 정하는 함수
간단한 형태의 뉴런은 입력에 가중치를 곱한 뒤 활성화 함수를 취하면 출력을 얻어 낼 수 있음
뉴런은 가중치를 처음에는 랜덤하게 초기화를 해서 시작하고 학습 과정에서 점차 일정한 값으로 수렴
학습 할 때 변하는 것은 가중치
활성화 함수는 시그모이드나 ReLU 를 주로 이용
최근에는 주로 ReLU를 주로 이용
뉴런을 직접 생성
#시그모이드 함수
import math
def sigmoid(x):
return 1 / (1 + math.exp(-x))
#입력
x = 1
#출력
y = 0
#한번 학습
w = tf.random.normal([1], 0, 1) #가중치
output = sigmoid(x * w)
print(output)
0.5174928205334988
#학습률을 0.01 로 설정해서 경사하강법을 수행
#학습 횟수 - epoch
for i in range(1000):
#출력을 생성
output = sigmoid(x * w)
#출력 오차를 계산
error = y - output
#가중치 업데이트
w = w + x * 0.1 * error
#횟수 와 오차 그리고 출력값을 확인
if i % 100 == 0:
print(i, error, output)
입력 데이터가 0 이고 가중치를 업데이트하는 식이 w + x * 0.1 * error 라서 x 가 0이 되면 가중치를 업데이트 할 수 없음
단순하게 시그모이드 함수를 적용하면 이 경우 최적점에 도달할 수 없고 계속 0.5 만 출력
입력 데이터 0에서 기울기가 없어지는 현상 - 기울기 소실 문제(Gradient Vanishing)
이 경우에는 시그모이드 함수 대신에 0에서 기울기를 갖는 ReLU를 사용하거나 시그모이드 함수에 데이터를 대입할 때 편향을 추가해서 해결
#입력
x = 0
#출력
y = 1
#학습률을 0.01 로 설정해서 경사하강법을 수행
#학습 횟수 - epoch
for i in range(1000):
#출력을 생성
output = sigmoid(x * w)
#출력 오차를 계산
error = y - output
#가중치 업데이트
w = w + x * 0.1 * error
#횟수 와 오차 그리고 출력값을 확인
if i % 100 == 0:
print(i, error, output)
입력 피처는 2개이고 출력은 1개, 가중치는 2개가 되어야 한다. 가중치는 입력 피처마다 설정됨
#입력과 출력 데이터 생성
X = np.array([[0,0], [0,1], [1,0], [1,1]])
y = np.array([[0], [0], [0], [1]])
#가중치 초기화
w = tf.random.normal([2], 0, 1) #입력 피처가 2개이므로 가중치도 2개
b = tf.random.normal([1], 0, 1) #편향
#학습
for i in range(3000):
#샘플이 여러 개이므로 에러는 모든 샘플의 에러 합계로 계산
#에러 합계를 저장할 변수
error_sum = 0
#4는 입력 데이터의 개수
for j in range(4):
#출력
output = sigmoid(np.sum(X[j] * w)+ 1*b)
#오차
error = y[j][0] - output
#가중치 업데이트 - 학습률은 0.1
w = w + X[j] * 0.1 * error
#편향 업데이트
b = b + 1 * 0.1 * error
#에러 값을 추가
error_sum += error
#100번 훈련을 할 때 마다 에러의 합계를 출력
if i % 100 == 99:
print(i, error_sum)
#입력과 출력 데이터 생성 - 같으면 0 다르면 1
X = np.array([[0,0], [0,1], [1,0], [1,1]])
y = np.array([[0], [1], [1], [0]])
#가중치 초기화
w = tf.random.normal([2], 0, 1) #입력 피처가 2개이므로 가중치도 2개
b = tf.random.normal([1], 0, 1) #편향
#학습
for i in range(3000):
#샘플이 여러 개이므로 에러는 모든 샘플의 에러 합계로 계산
#에러 합계를 저장할 변수
error_sum = 0
#4는 입력 데이터의 개수
for j in range(4):
#출력
output = sigmoid(np.sum(X[j] * w)+ 1*b)
#오차
error = y[j][0] - output
#가중치 업데이트 - 학습률은 0.1
w = w + X[j] * 0.1 * error
#편향 업데이트
b = b + 1 * 0.1 * error
#에러 값을 추가
error_sum += error
#100번 훈련을 할 때 마다 에러의 합계를 출력
if i % 100 == 99:
print(i, error_sum)
import numpy as np
#입력과 출력 데이터 생성 - 같으면 0 다르면 1
X = np.array([[0,0], [0,1], [1,0], [1,1]])
y = np.array([[0], [1], [1], [0]])
#2개의 완전 연결층을 가진 모델을 생성
#units 는 뉴런의 개수이고 activation은 출력을 계산해주는 함수
#input_shape는 맨 처음 입력 층에서 피처의 모양
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=2, activation='sigmoid', input_shape=(2, )),
tf.keras.layers.Dense(units=1, activation='sigmoid')
])
#lr 부분이 에러가 발생하면 learning_rate 로 수정하시면 됩니다.
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.1), loss='mse')
#모델을 확인
model.summary()
# 훈련
#batch_size는 한 번에 연산되는 데이터의 크기(Mini Batch)
history = model.fit(X, y, epochs=10000, batch_size=1)
# 결과 확인
result = model.predict(X)
print(result)
# 측정치 변화량 (손실의 변화량)
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
7. Tensorflow Data API
Machine Learning을 하는 경우 대규모 데이터 세트를 사용해야 하는 경우가 있는데 이 경우 Data를 Load 하고 Preprocessing 을 수행하는 작업은 번거로운 작업이며 데이터를 어떻게 사용할 것인가 하는 것도 어려운 작업(Multi Threading, Queue, Batch, Prefetch 등) 중 하나
- Tensorflow Data API
dataset 객체를 만들고 Data를 읽어올 위치와 변환 방법을 지정하면 이러한 작업을 자동으로 처리
Data API는 텍스트 파일(csv, tsv 등), 고정 길이를 가진 이진 파일, Tensorflow의 TFRecord 포맷을 사용하는 이진 파일에서 데이터를 읽을 수 있다.
관계형 데이터베이스나 Google Big Query 와 같은 NoSQL 데이터베이스에서 데이터를 읽어올 수 있다.
Tensorflow에서는 One Hot Encoding 이나 BoW Encoding, embedding 등의 작업을 수행해주는 다양한 Preprocessing 층도 제공
7-1) 프로젝트
- TF 변환
- TF Dataset(TFDS)
dataset을 다운로드할 수 있는 편리한 함수 제공
이미지 넷과 같은 대용량 dataset이 포함되어 있음
dataset = tf.data.Dataset.range(10) #0~9 까지의 데이터를 가지고 데이터셋을 구성
print(dataset)
tfds.load 함수를 호출하면 Data를 다운로드하고 dataset 의 디셔너리로 Data를 리턴
- minist 데이터 가져오기
#!pip install tensorflow_datasets
import tensorflow_datasets as tfds
datasets = tfds.load(name="mnist")
#dict 형태로 데이터를 가져옵니다.
print(type(datasets))
#모든 키 확인
print(datasets.keys())
print(type(datasets['train']))
#하나의 데이터도 dict 로 되어 있음
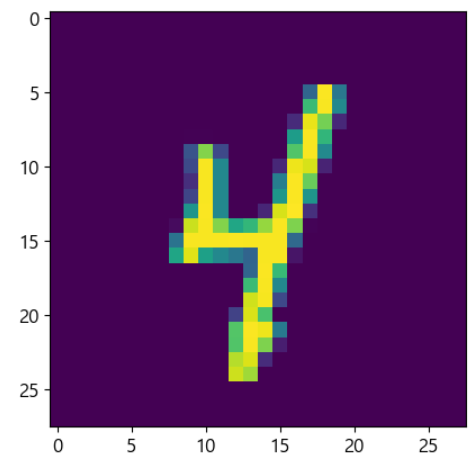
for item in datasets['train']:
#print(type(item))
#print(item.keys())
#print(item['label'])
plt.imshow(item['image'])
break
0 1 2 3 4 5 6 7 8 9 10 0 0.00632 18.00 2.31 0.0 0.538 6.575 65.2 4.0900 1.0 296.0 15.3 1 396.90000 4.98 24.00 NaN NaN NaN NaN NaN NaN NaN NaN 2 0.02731 0.00 7.07 0.0 0.469 6.421 78.9 4.9671 2.0 242.0 17.8 3 396.90000 9.14 21.60 NaN NaN NaN NaN NaN NaN NaN NaN 4 0.02729 0.00 7.07 0.0 0.469 7.185 61.1 4.9671 2.0 242.0 17.8
공백 문자 단위로 데이터를 분할해서 읽을 공백 문자가 \s 이고 +를 추가한 이유는 맨 앞에 공백이 있으면 제거하기 위해서 뒤의 3개의 데이터도 하나의 행에 포함이 되어야 하는데 뒷줄로 넘어감
# 홀수 행에 짝수 행에서 앞의 2개의 열의 데이터를 붙이고 타겟 만들기
#피처 만들기
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
#타겟 만들기
target = raw_df.values[1::2, 2]
lm_features = ["RM", "ZN", "INDUS", "NOX", "AGE", "PTRATIO", "LSTAT", "RAD"]
#한 줄에 4개씩 8개의 그래프 영역을 생성
fig, axe = plt.subplots(figsize=(16, 8), ncols=4, nrows=2)
#python에서 list를 순회할 때 인덱스를 같이 사용하는 방법
for i, feature in enumerate(lm_features):
row = int(i / 4)
col = i % 4
sns.regplot(x=feature, y="PRICE", data=bostonDF, ax=axe[row][col])
# 타겟과 피처의 상관 계수 확인
#상관 계수 구하기
cols = lm_features.copy()
cols.append("PRICE")
cm = np.corrcoef(bostonDF[cols].values.T)
print(cm)
plt.figure(figsize=(15, 7))
sns.set(font_scale=1.5) #화면 크기에 따라 변경 - 폰트 크기
hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f',
annot_kws={'size':15}, yticklabels=cols, xticklabels=cols)
plt.show()
ticklabels는 보여질 문자열
annot_kws 는 글자 크기
fmt는 포맷으로 숫자의 표시 형식
annot는 값 출력 여부
- 데이터 탐색 결과
RM 과 LSTAT 의 PRICE 영향도가 높음
RM은 양의 상관 관계를 가지고 LSTAT는 음의 상관 관계를 가짐
단변량(피처가 1개) 선형 회귀를 수행한다면 2개의 피처 중 하나를 이용하는 것이 효율적
scipy 를 이용한 RM 과 PRICE에 대한 단변량 선형 회귀
from scipy import stats
result = stats.linregress(bostonDF['RM'], bostonDF['PRICE'])
#하나의 속성 출력
print(result.pvalue)
#예측 - 방이 4개 인 경우
print("방이 4개인 경우:", result.slope * 4 + result.intercept)
from sklearn.linear_model import LinearRegression
#모델 생성 - 행렬 분해를 이용하는 선형 회귀 모델
slr = LinearRegression()
#타겟과 피처 생성
X = bostonDF[['LSTAT']].values #sklearn 에서는 피처가 2차원 배열
y = bostonDF['PRICE'].values #타겟은 일반적으로 1차원 배열
#훈련
slr.fit(X, y)
통계 패키지는 훈련의 결과를 리턴
머신러닝 패키지는 훈련의 결과를 내부에 저장
다음 데이터를 예측할 때 통계 패키지는 수식을 직접 만들어야 함
머신러닝 패키지는 수식을 만들지 않고 새로운 데이터만 predict에게 제공
API를 확인할 때 통계 패키지는 리턴하는 데이터를 확인해야 하고
머신러닝 패키지는 모델을 확인해야 함
#기울기 와 절편 출력
print("기울기:", slr.coef_[0])
print("절편:", slr.intercept_)
#예측
print(slr.coef_[0] * 4 + slr.intercept_)
print(slr.predict([[4]]))
from sklearn.metrics.pairwise import cosine_similarity
similarity_simple_pair = cosine_similarity(feature_vect_simple[0] , feature_vect_simple)
print(similarity_simple_pair)
[[1. 0.42804604 0.42804604]]
feature_vect_simple 전체와의 거리
feature_vect_simple[n] n번째 문장과의 거리
희소행렬을 대입하면 밀집행렬로 변환해서 유사도 측정
1-3) 문서 군집에서 유사도 값이 큰 것끼리 묶기
# 한글 문장의 유사도 측정
### 훈련 데이터 만들기
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(min_df = 1)
contents = ['우리 김치찌개 먹으러 가자!',
'나는 고기김치찌개 좋아해.',
'계란찜도 좋아합니다.'
'먹고 나서 잠깐 산책할까?',
'산책하면서 라우브 신곡 듣고 싶어.']
#좋아해-좋아합니다. 다른 말로 인식하니 어근추출 해주기
from konlpy.tag import Okt
okt = Okt()
contents_tokens = [okt.morphs(row) for row in contents]
print(contents_tokens)
contents_for_vectorize = []
for content in contents_tokens:
sentence = ''
for word in content:
sentence = sentence + ' ' + word
contents_for_vectorize.append(sentence)
print(contents_for_vectorize)
[' 우리 김치찌개 먹으러 가자 !', ' 나 는 고기 김치찌개 좋아해 .', ' 계란찜 도 좋아합니다 . 먹고 나서 잠깐 산책 할까 ?', ' 산책 하면서 라우 브 신곡 듣고 싶어 .']
new_post = ['우리 김치찌개 먹자']
new_post_tokens = [okt.morphs(row) for row in new_post]
new_post_for_vectorize = []
for content in new_post_tokens:
sentence=''
for word in content:
sentence = sentence + ' ' + word
new_post_for_vectorize.append(sentence)
print(new_post_for_vectorize)
new_post_vec = tfidf_vect.transform(new_post_for_vectorize)
print(new_post_vec)
[' 우리 김치찌개 먹자'] (0, 12) 0.7852882757103967 (0, 3) 0.6191302964899972
# title 컬럼을 얻기 이해 movies 와 조인 수행
rating_movies = pd.merge(ratings, movies, on='movieId')
rating_movies.head(3)
# pivot
# columns='title' 로 title 컬럼으로 pivot 수행.
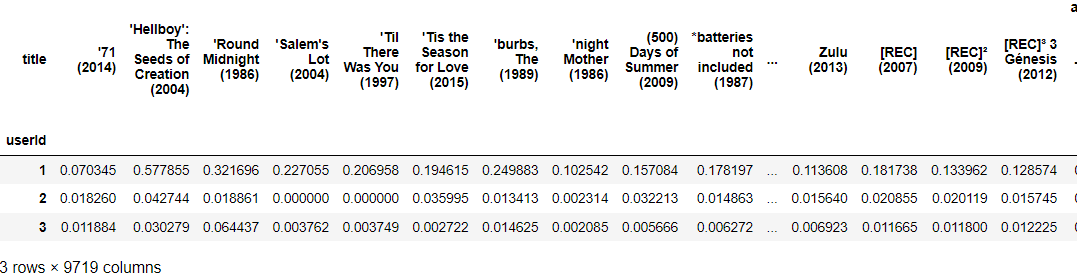
ratings_matrix = rating_movies.pivot_table('rating', index='userId', columns='title')
# NaN 값을 모두 0 으로 변환
ratings_matrix = ratings_matrix.fillna(0)
ratings_matrix.head(3)
행렬을 펼쳐낼 때 유저별로 유사도를 계산할지, 영화별로 유사도를 계산할지에 따라서 펼쳐내는 방향이 달라진다.
# cosine_similarity() 로 반환된 넘파이 행렬을 영화명을 매핑하여 DataFrame으로 변환
item_sim_df = pd.DataFrame(data=item_sim, index=ratings_matrix.columns,
columns=ratings_matrix.columns)
print(item_sim_df.shape)
item_sim_df.head(3)
# Godfather, The(1972)와 가장 유사한 영화 5개 추출
item_sim_df["Godfather, The (1972)"].sort_values(ascending=False)[:6]
title Godfather, The (1972) 1.000000 Godfather: Part II, The (1974) 0.821773 Goodfellas (1990) 0.664841 One Flew Over the Cuckoo's Nest (1975) 0.620536 Star Wars: Episode IV - A New Hope (1977) 0.595317 Fargo (1996) 0.588614 Name: Godfather, The (1972), dtype: float64
3. 아이템 기반 최근접 이웃 협업 필터링으로 개인화된 영화 추천
아이템 기반의 영화 유사도 데이터는 모든 사용자의 평점을 기준으로 영화의 유사도를 생성했기 때문에 영화를 추천할 수는 있지만 개인의 취향을 전혀 반영하지 않음
개인화된 영화 추천은 유저가 아직 관람하지 않은 영화를 추천해야 함
아직 관람하지 않은 영화에 대해서 아이템 유사도와 기존에 관람한 영화의 평점데이터를 기반으로 모든 영화의 평점을 예측하고 그중에서 높은 예측 평점을 가진 영화를 추천
- 계산식: 사용자가 본 영화에 대한 실제 평점과 다른 모든 영화와의 코사인 유사도를 내적 곱 하고 그 값을 전체 합으로 나눔
from sklearn.metrics import mean_squared_error
# 사용자가 평점을 부여한 (0이 아닌) 영화에 대해서만 예측 성능 평가 MSE 를 구함.
def get_mse(pred, actual):
pred = pred[actual.nonzero()].flatten()
actual = actual[actual.nonzero()].flatten()
return mean_squared_error(pred, actual)
print('아이템 기반 모든 인접 이웃 MSE: ', get_mse(ratings_pred, ratings_matrix.values ))
아이템 기반 모든 인접 이웃 MSE: 9.895354759094706
MSE가 너무 높다.
평점이 5.0인데, 제곱근인 3정도 차이가 난다는 건 추천 시스템으로 사용하기 어렵다는 뜻
4. 추천 수정
현재는 모든 영화와의 유사도를 이용해서 평점을 예측했는데 모든 영화보다는 유저가 본 영화 중 유사도가 가장 높은 영화 몇개를 이용해서 예측하는 것이 더 나을 가능성이 높다.
# 유사도를 계산할 영화의 개수를 배개변수로 추가
def predict_rating_topsim(ratings_arr, item_sim_arr, n=20):
# 사용자-아이템 평점 행렬 크기만큼 0으로 채운 예측 행렬 초기화
pred = np.zeros(ratings_arr.shape)
# 사용자-아이템 평점 행렬의 열 크기만큼 Loop 수행
for col in range(ratings_arr.shape[1]):
# 유사도 행렬에서 유사도가 큰 순으로 n개 데이터 행렬의 index 반환
top_n_items = [np.argsort(item_sim_arr[:, col])[:-n-1:-1]]
# 개인화된 예측 평점을 계산
for row in range(ratings_arr.shape[0]):
pred[row, col] = item_sim_arr[col, :][top_n_items].dot(ratings_arr[row, :][top_n_items].T)
pred[row, col] /= np.sum(np.abs(item_sim_arr[col, :][top_n_items]))
return pred
title Adaptation (2002) 5.0 Citizen Kane (1941) 5.0 Raiders of the Lost Ark (Indiana Jones and the Raiders of the Lost Ark) (1981) 5.0 Producers, The (1968) 5.0 Lord of the Rings: The Two Towers, The (2002) 5.0 Lord of the Rings: The Fellowship of the Ring, The (2001) 5.0 Back to the Future (1985) 5.0 Austin Powers in Goldmember (2002) 5.0 Minority Report (2002) 4.0 Witness (1985) 4.0 Name: 9, dtype: float64
# 유저가 보지 않은 영화 목록을 리턴하는 함수
def get_unseen_movies(ratings_matrix, userId):
# userId로 입력받은 사용자의 모든 영화정보 추출하여 Series로 반환함.
# 반환된 user_rating 은 영화명(title)을 index로 가지는 Series 객체임.
user_rating = ratings_matrix.loc[userId,:]
# user_rating이 0보다 크면 기존에 관람한 영화임. 대상 index를 추출하여 list 객체로 만듬
already_seen = user_rating[ user_rating > 0].index.tolist()
# 모든 영화명을 list 객체로 만듬.
movies_list = ratings_matrix.columns.tolist()
# list comprehension으로 already_seen에 해당하는 movie는 movies_list에서 제외함.
unseen_list = [ movie for movie in movies_list if movie not in already_seen]
return unseen_list
# 유저가 보지 않은 영화 목록에서 예측 평점이 높은 영화 제목을 리턴하는 함수
def recomm_movie_by_userid(pred_df, userId, unseen_list, top_n=10):
# 예측 평점 DataFrame에서 사용자id index와 unseen_list로 들어온 영화명 컬럼을 추출하여
# 가장 예측 평점이 높은 순으로 정렬함.
recomm_movies = pred_df.loc[userId, unseen_list].sort_values(ascending=False)[:top_n]
return recomm_movies
# 유저가 보지 않은 영화 목록 추출
# 사용자가 관람하지 않는 영화명 추출
unseen_list = get_unseen_movies(ratings_matrix, 9)
# 아이템 기반의 인접 이웃 협업 필터링으로 영화 추천
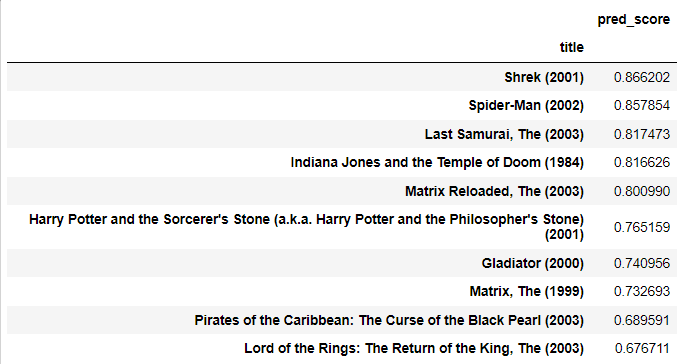
recomm_movies = recomm_movie_by_userid(ratings_pred_matrix, 9, unseen_list, top_n=10)
# 평점 데이타를 DataFrame으로 생성.
recomm_movies = pd.DataFrame(data=recomm_movies.values,index=recomm_movies.index,columns=['pred_score'])
recomm_movies
5. 작업 과정 정리
- 각 영화 간의 유사도 측정
- 유저가 본 영화의 평점을 기반으로 해서 유사도가 높은 20개의 영화를 추출하고, 그 영화들의 평점으로 않은 영화의 평점을 예측