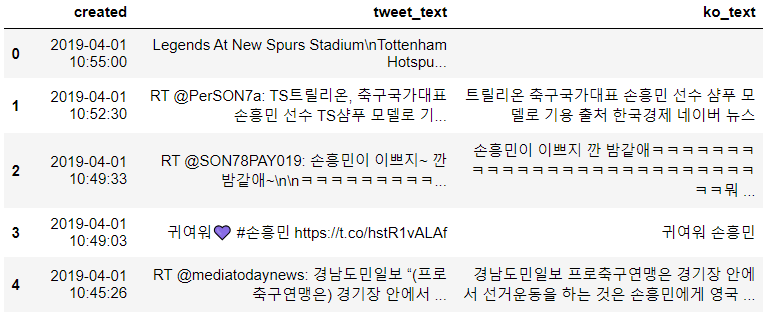
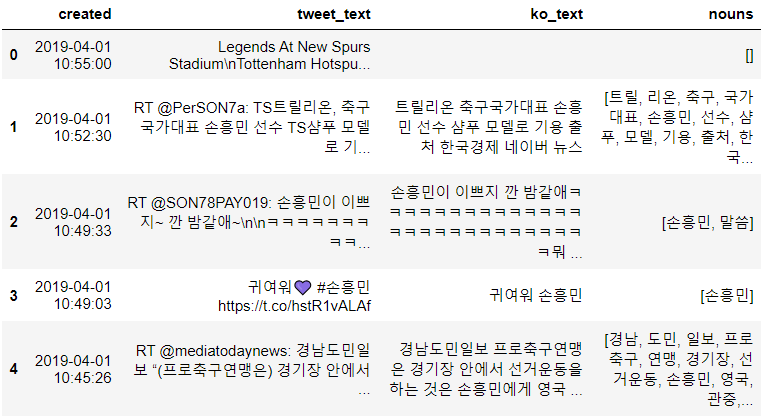
from ast import literal_eval
#문자열을 파이썬 객체로 변환
movies_df['genres'] = movies_df['genres'].apply(literal_eval)
movies_df['keywords'] = movies_df['keywords'].apply(literal_eval)
#디셔너리에서 데이터만 추출
movies_df['genres'] = movies_df['genres'].apply(lambda x : [ y['name'] for y in x])
movies_df['keywords'] = movies_df['keywords'].apply(lambda x : [ y['name'] for y in x])
#데이터 확인
movies_df[['genres', 'keywords']][:1]
2. 장르 유사도 측정
문자열을 피처로 만드는 방법은 CountVectorizer, TfidfVectorizer
장르 리스트 안에서 같은 단어가 나올 수 없으니 등장 횟수만을 기반으로 하는 CountVectorizer 사용
#피처 벡터화
from sklearn.feature_extraction.text import CountVectorizer
# CountVectorizer를 적용하기 위해 공백문자로 word 단위가 구분되는 문자열로 변환.
movies_df['genres_literal'] = movies_df['genres'].apply(lambda x : (' ').join(x))
print(movies_df['genres_literal'])
0 [ { " i d " : 2 8 , " n a m e " : " A c ... 1 [ { " i d " : 1 2 , " n a m e " : " A d ... 2 [ { " i d " : 2 8 , " n a m e " : " A c ... 3 [ { " i d " : 2 8 , " n a m e " : " A c ... 4 [ { " i d " : 2 8 , " n a m e " : " A c ...
#JSON 문자열을 Python의 자료구조로 변경
result = json.loads(data.text)
print(type(result))
<class 'dict'>
documents = result['documents']
for doc in documents:
print(doc['blogname'], doc['title'], doc['datetime'], )
야채's Data Tableau - <b>막대</b> <b>그래프</b> 2024-02-01T14:22:10.000+09:00 ...
- MySQL 연동
!pip install pyMySQL
- 데이터베이스 접속 확인
import pymysql
con = pymysql.connect(host='데이터베이스 위치',
port = 포트번호,
user = '아이디',
password = '비밀번호',
db = '데이터베이스 이름',
charset = '인코딩 방식')
con.close()
- SELECT를 제외한 구문 실행
#연결 객체를 가지고 cursor()를 호출해서 커서 객체 생성
cursor = con.cursor()
#sql 실행
cursor.execute("SQL 구문(%s를 대입할 데이터 개수만큼 생성)", (%s에 대입할 데이터를 나열))
#commint
con.commit()
from collections import Counter
# 한국어 약식 불용어사전 예시 파일 - https://www.ranks.nl/stopwords/korean
korean_stopwords_path = "./python_machine_learning-main/korean_stopwords.txt"withopen(korean_stopwords_path, encoding='utf8') as f:
stopwords = f.readlines()
#앞뒤 공백 제거
stopwords = [x.strip() for x in stopwords]
print(stopwords)
상품 거래 연관 규칙 분석을 할 때는 구매한 상품 목록을 list로 만들면 됨 ex. ['사과', '배', '한라봉']
3. 연관 규칙 분석
from apyori import apriori
# 장바구니 형태의 데이터(트랜잭션 데이터)를 생성
transactions = [
['손흥민', '시소코'],
['손흥민', '케인'],
['손흥민', '케인', '포체티노']
]
# 연관 분석을 수행
results = list(apriori(transactions))
for result in results:
print(result)
# 트랜잭션 데이터를 추출합니다.
transactions = df['nouns'].tolist()
transactions = [transaction for transaction in transactions if transaction] # 공백 문자열 방지print(transactions)
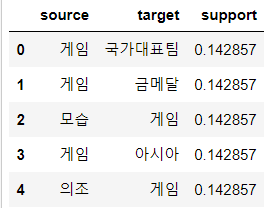
# 데이터 프레임 형태로 정리
columns = ['source', 'target', 'support']
network_df = pd.DataFrame(columns=columns)
# 규칙의 조건절을 source, 결과절을 target, 지지도를 support 라는 데이터 프레임의 피처로 변환for result in results:
items = [x for x in result.items]
row = [items[0], items[1], result.support]
series = pd.Series(row, index=network_df.columns)
network_df.loc[len(network_df)] = series
network_df.head()
4. 키워드 빈도 추출
from konlpy.tag import Okt
from collections import Counter
# 명사 키워드를 추출
nouns_tagger = Okt()
nouns = nouns_tagger.nouns(tweet_corpus)
count = Counter(nouns)
# 한글자 키워드를 제거
remove_char_counter = Counter({x : count[x] for x in count iflen(x) > 1})
print(remove_char_counter)
# 키워드와 키워드 빈도 점수를 ‘node’, ‘nodesize’ 라는 데이터 프레임의 피처로 생성
node_df = pd.DataFrame(remove_char_counter.items(), columns=['node', 'nodesize'])
node_df = node_df[node_df['nodesize'] >= 50] # 시각화의 편의를 위해 ‘nodesize’ 50 이하는 제거합니다.
node_df.head()
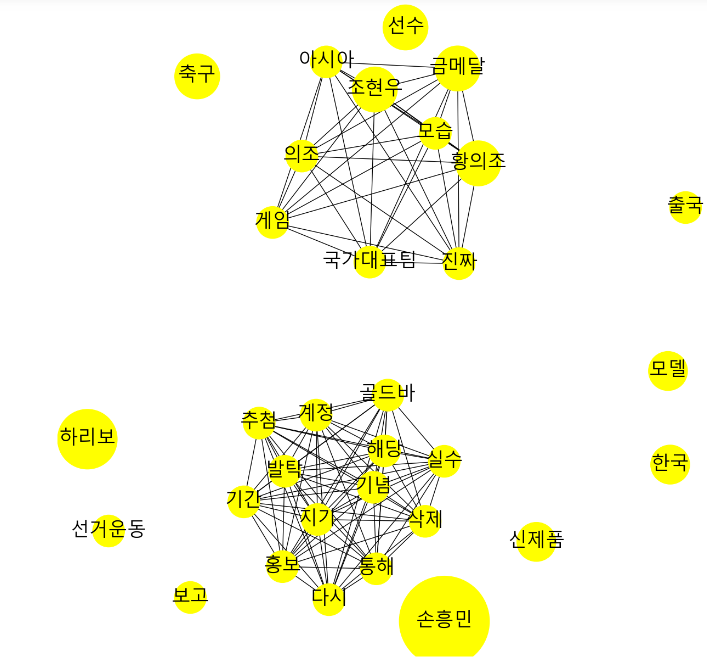
# networkx
import networkx as nx
plt.figure(figsize=(12,12))
# networkx 그래프 객체
G = nx.Graph()
# node_df의 키워드 빈도수를 데이터로 하여, 네트워크 그래프의 ‘노드’ 역할을 하는 원을 생성for index, row in node_df.iterrows():
G.add_node(row['node'], nodesize=row['nodesize'])
# network_df의 연관 분석 데이터를 기반으로, 네트워크 그래프의 ‘관계’ 역할을 하는 선을 생성for index, row in network_df.iterrows():
G.add_weighted_edges_from([(row['source'], row['target'], row['support'])])
# 그래프 디자인과 관련된 파라미터를 설정
pos = nx.spring_layout(G, k=0.6, iterations=50)
sizes = [G.nodes[node]['nodesize']*25for node in G]
nx.draw(G, pos=pos, node_size=sizes, node_color='yellow')
#레이블 출력 (한글폰트)
nx.draw_networkx_labels(G, pos=pos, font_family='Malgun Gothic', font_size=25)
# 그래프 출력
ax = plt.gca()
plt.show()
import pytagcloud
data = ko.vocab().most_common(101)
taglist = pytagcloud.make_tags(data, maxsize=200)
for i in taglist:
if i["tag"] == '고양이':
taglist.remove(i)
#태그 클라우드 생성
pytagcloud.create_tag_image(taglist, 'wordcloud.png', size=(2000, 2000), fontname='Korean', rectangular=False)
import matplotlib.pyplot
import matplotlib.image
img = matplotlib.image.imread('wordcloud.png')
imgplot = matplotlib.pyplot.imshow(img)
matplotlib.pyplot.show()
# 강아지
7. 단어 추천
!pipinstallgensim
from gensim.models import word2vec
okt = Okt()
results = []
lines = present_candi_text
for line in lines:
malist = okt.pos(line, norm=True, stem=True)
r = []
#조사, 어미, 구두점을 제거하고 r에 추가for word in malist:
ifnot word[1] in ["Josa", "Eomi", "Punctuation"]: #품사가 아닌 경우
r.append(word[0])
#앞뒤에 있는 좌우 공백 제거
r1 = (" ".join(r)).strip()
results.append(r1)
print(r1)
print(results)
['애기 고양이 상 좋다 건가 고양이 상 귀엽다 고양이 상 애기 고양이 상 들다 보다 그냥 고양이 상도 아니다 애기 고양 이상은 뭔 뜻', '고양이 간식 급여 이 거 고양이 주다 되다 이마트 구매 하다 고양이 강아지 코너 사이 있다 고양이 끄다 알 구 먀 하다 아니다 있다 생각 들어서다', '강아지 고양이 사료 강아지 고양이 같이 키우다 자율 급식 고양이 강아지 사료 각 각 퍼 놓다 근데 강아지 고양이 사료 먹다 고양이 강아지 사료 먹다 괜찮다', '고양이 방 집착 하다 많다 고양이 해 되다 방뮨 닫다 지내다 저희 고양이 친척 안 좋아하다 근데 친척 이번 설 고양이 되게 쌔 혼내다 많다 고양이 해 되다 방문 닫다 사용 싶다 고양이 화장실 밥 먹다 때 문 열다 닫다 하다 돼다 걱정 많다 고양이', '고양이 꿈 해몽 부탁드리다 제 방금 일어나다 고양이 꿈 생생하다 궁금하다 일단 일어나다 제 집 키우다 고양이 마당 앉다 집 들어오다 문 열다 모르다 고양이 들 ....
['강아지 적응 ㅠㅠ 무엇 제일 걸리다 강아지 네 물론 제 이직 하다 되어다 집 어머니 케어 해 주다 하지만 강아지 워낙 저 좋아하다 저 강아지 너무 좋아하다 두다 떠나다 마음 안좋다 강아지 제 없다 금방 적응 하다 요 물론 집 강아지 엄마 간식 맛있다', '강아지 꿈 해석 해주다 강아지 들 엘베 타다 강아지 못 타다 줄이다 올라가다 강아지 매달리다 사고 있다 그걸 꾸다 사람 들 이 줄 빨리 끊다 하니 끊다 안되다 하다 강아지 높이 올라가다 수록 더 아프다 20 층 멈추다 의미 있다', '강아지 털 알르레기 없애다 법 제 강아지 털 알르레기 있다 근데 강아지 너무 키우다 강아지 너무 좋아하다 ㅠㅠ 어리다 때 강아지 너무 좋아하다 강아지 훈련사 꾸다 ㅠㅠ 진짜 강아지 넘다 키우다 싶다 ㅠㅠ 엄마 키우다 되다 강아지 알르레기 땜 ㅠㅠㅠ 내공 40', '강아지 너무 키우다 싶다 저 5-6년 정도 강아지 키우다 싶다 마음 크다 엄마 강아지 침 알레르기 좀 있다 안되다 거 같다 저 엄마 신경 쓰다 진짜 강아지 자다 키우다 자신 있다 ㅜㅠ 강아지 키우다 정말로 힘들다 그렇다 거 .....
# Word2Vec 적용
data_file = 'cat.data'withopen(data_file, 'w', encoding='utf-8') as fp:
fp.write("\n".join(results))
data = word2vec.LineSentence(data_file)
model = word2vec.Word2Vec(data, vector_size=200, window=10, hs=1,min_count=2, sg=1)
model.save('cat.model')
model = word2vec.Word2Vec.load("cat.model")
model.wv.most_similar(positive=['고양이'])
#정규식 모듈import re
# <br> html 태그 -> 공백으로 변환
review_df['review'] = review_df['review'].str.replace('<br />',' ')
# 파이썬의 정규 표현식 모듈인 re를 이용하여 영어 문자열이 아닌 문자는 모두 공백으로 변환
review_df['review'] = review_df['review'].apply( lambda x : re.sub("[^a-zA-Z]", " ", x) )
print(review_df['review'].head())
0 With all this stuff going down at the moment ... 1 The Classic War of the Worlds by Timothy ... 2 The film starts with a manager Nicholas Bell... 3 It must be assumed that those who praised thi... 4 Superbly trashy and wondrously unpretentious ... Name: review, dtype: object
a-zA-Z가 아닌 글자를 공백으로 치환
한글을 제외한 글자 제거: [^가-힣]
3. 훈련/테스트 데이터 분리
- 지도학습 기반의 분류이므로 훈련 데이터를 이용해서 훈련하고, 테스트 데이터로 확인하는 것을 권장
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, roc_auc_score
ngram을 설정하면 하나의 단어를 하나로 인식하지 않고, n개의 단어까지 하나의 단어로 인지한다. 영어는 2나 3을 설정: 사람 이름 등 (I am a boy -> I am, am a, a boy) 정확하게 일치하는 것이라면 예측도 가능하다. (I am 다음은 a/an 이구나) 그래서 생성형 AI는 ngram을 설정하는게 좋다.
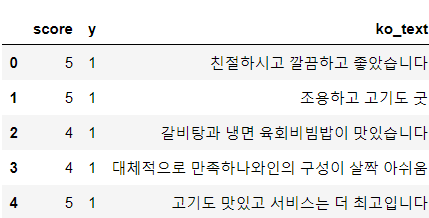
score review y 0 5 친절하시고 깔끔하고 좋았습니다 1 1 5 조용하고 고기도 굿 1 2 4 갈비탕과 냉면, 육회비빔밥이 맛있습니다. 1 3 4 대체적으로 만족하나\n와인의 구성이 살짝 아쉬움 1 4 5 고기도 맛있고 서비스는 더 최고입니다~ 1
2. 데이터 전처리
한글 추출: (가-힣)
모음과 자음만으로 구성된 텍스트도 추출하려면 (ㄱ-ㅣ, 가-힣)
#한글을 제외한 글자 전부 제거
import re
# 텍스트 정제 함수 : 한글 이외의 문자는 전부 제거deftext_cleaning(text):
# 한글의 정규표현식으로 한글만 추출합니다.
hangul = re.compile('[^ ㄱ-ㅣ가-힣]+')
result = hangul.sub('', text)
return result
df['ko_text'] = df['review'].apply(lambda x: text_cleaning(x))
del df['review']
df.head()
데이터 용량을 줄이기 위해 바로바로 del
3. 형태소분석
from konlpy.tag import Okt
# konlpy라이브러리로 텍스트 데이터에서 형태소를 '단어/품사'로 추출defget_pos(x):
tagger = Okt()
pos = tagger.pos(x) # PartOfSpeech
pos = ['{}/{}'.format(word,tag) for word, tag in pos]
return pos
# 형태소 추출 동작을 테스트합니다.
result = get_pos(df['ko_text'][0])
print(result)
from sklearn.feature_extraction.text import CountVectorizer
# 형태소를 벡터 형태의 학습 데이터셋(X 데이터)으로 변환
index_vectorizer = CountVectorizer(tokenizer = lambda x: get_pos(x))
X = index_vectorizer.fit_transform(df['ko_text'].tolist())
X.shape
from sklearn.feature_extraction.text import TfidfTransformer
# TF-IDF 방법으로, 형태소를 벡터 형태의 학습 데이터셋(X 데이터)으로 변환합니다.
tfidf_vectorizer = TfidfTransformer()
X = tfidf_vectorizer.fit_transform(X)
print(X.shape)
print(X[0])
- 차원을 축소하면 일부 정보가 유실되기 때문에 훈련 속도가 빨라지기는 하지만 성능은 나빠질 가능성이 높다.
2. 투영 (Projection)
물체의 그림자를 어떤 물체 위에 비추는 일 또는 그 비친 그림자를 의미
어떤 물체든 그림자는 2차원으로 표현될 수 있다는 원리
투영을 이용해서 구현된 알고리즘이 PCA, LDA 등
1) 특징
MNIST 같은 이미지에는 잘 적용이 되지만 스위스 롤 같은 데이터에는 적용할 수 없다.
특성들의 값이 거의 비슷하고 다른 특성의 값이 많이 다르면 적용하기가 좋은데 그렇지 않은 경우는 적용하기 어렵다.
높이가 별 차이 안나니까 눌러서 높이를 없애버려도 차이가 없으니 두개만으로도 설명이 된다.
MNIST 이미지 - 바깥 쪽은 거의 다 똑같다. (테두리는 항상 흰색)
스위스롤: 누르면 안됨. 부딪혀버린다.
실제 값 원했던 것
3. Manifold 방식
차원을 축소하는데 특정 차원을 없애지 않고 새로운 차원을 만들어 내는 방식
알고리즘: LLE, t-SNE, Isomap, Autoencoer
직선으로 구분하는 건 불가해졌지만, 곡선으로 나누면 됨 => PCA
4. PCA (Principal Component Analysis - 주성분 분석)
여러 변수 간에 존재하는 상관관계를 이용하고 이를 대표하는 주성분을 추출해서 차원을 축소하는 기법
차원을 축소할 때 데이터의 정보는 최대한 유지하면서 고차원에서 저차원으로 축소를 하는 방식
데이터의 다른 부분을 보존하는 방식으로 분산을 최대한 유지하는 축을 생성
이 방식은 데이터의 분포가 표준정규분포가 아닌 경우에는 적용이 어려움
- 동작 원리
학습 데이터 셋에서 분산(변동성)이 최대인 축 (PC1)을 찾음
PC1과 수직이면서 분산이 최대인 축 (PC2)를 찾음
첫 번째 축과 두 번째 축에 직교하고 분산을 최대한 보존하는 세 번째 축을 찾음
1~3의 방법으로 차원 수만큼 찾음
데이터 구분: 차이 구분되는 성질을 가장 적게 잃어야하기 때문에, 가장 많이 차이가 나는 것을 찾아야 한다. 애-어른을 구분하는 가장 큰 차이는 나이, 그게 첫번째 주성분이 된다. 그러면 반대편은 설명하지 못하기 때문에, 두번째 주성분은 첫번째 주성분과 직교한다. 2-3가지 정도로 판단하자!
배치 처리가 미니 배치 방식보다 좋은 점은 자원을 효율적으로 사용할 수 있고 작업 시간은 단축 시킬 수 있다는 것
미니 배치 방식이 좋은 점은 훈련을 실시간으로 수행하기 때문에 훈련이 끝나는 시점만 따져보면 더 빠르다.
* 파이썬에서 메모리 정리 방법: (1) 가리키는 데이터가 없을 때 자동으로 정리. (2) 기존 변수가 라키는 데이터가 없도록 del 변수명 을 사용
4-5) 3가지 PCA 훈련 시간 비교
# 일반 PCA
import time
start = time.time()
pca = PCA(n_components=154, svd_solver="full")
pca.fit_transform(X_train)
end = time.time()
print("PCA 수행 시간:", (end-start))
print(pca.explained_variance_ratio_.sum())
PCA 수행 시간: 4.382986545562744 0.9504506731634907
# 랜덤 PCA
import time
start = time.time()
pca = PCA(n_components=154, svd_solver="randomized")
pca.fit_transform(X_train)
end = time.time()
print("랜덤 PCA 수행 시간:", (end-start))
print(pca.explained_variance_ratio_.sum())
랜덤 PCA 수행 시간: 4.955554962158203 0.9500787743598854
svd_solver="randomized"를 생략해도 Random PCA - 피처의 500개가 넘으면 자동
# 점진적 PCA
from sklearn.decomposition import IncrementalPCA
#배치 사이즈: 데이터를 몇 개 씩 훈련
n_batches = 100
start = time.time()
inc_pca = IncrementalPCA(n_components=154)
for X_batch in np.array_split(X_train, n_batches):
inc_pca.partial_fit(X_batch)
X_reduced = inc_pca.transform(X_train)
end = time.time()
print("점진적 PCA 수행 시간:", (end-start))
print(inc_pca.explained_variance_ratio_.sum())
점진적 PCA 수행 시간: 29.47389006614685 0.9497567304638014
4-6) Kernel PCA
- 커널 트릭 PCA: 비선형 데이터에 다항을 추가하는 것 처럼 해서 비선형 결정 경계를 만드는 PCA
일반 PCA를 수행해서 분산의 비율이 제대로 표현되지 않는 경우 사용
- KernelPCA클래스 (kernel, gamma)
kernel = rbf: 가우시안 정규 분포 형태의 커널을 적용
kernel = sigmoid: 로그 함수 형태
gamma: 복잡도를 설정. 0.0 ~ 1.0 사이의 값
- 하이퍼 파라미터 튜닝을 거의 하지 않지만 주성분 분석을 분류나 회귀의 전처리 과정으로 사용하는 경우에 가장 좋은 성능을 발휘하는 kernel이나 gamma 값을 찾기 위해서 튜닝 하는 경우도 있다.
#데이터 생성from sklearn.datasets import make_swiss_roll
# X는 3차원 피처, t 는 범주
X, t = make_swiss_roll(n_samples=1000, noise=0.2, random_state=42)
print(X)
Decision Tree ----------------sklearn - RandomF: 랜덤추출 - Ada - GB : 경사하강법 - HistGB : 피처(연속형)의 구간(정수)화하여 경사하강법 ---------외부라이브러리 - XGBoost - LGBM - CAT 무작위성 추가, 속도 향상 등등 딥러닝 - 데이터가 많을 때 성능 날뜀
트리 모델을 쓸 때 조심할 점 1. 트리를 만들 때는 균형을 맞춰야 한다. - 깊이가 깊어지면 찾기가 더 힘들어지기 때문이다. 트리가 한쪽으로 치우치면 평균 조회횟수가 높아진다. - 그래서 Balaned Tree를 만들려고 애쓰는데, LGBM은 이걸 신경쓰지 않기 때문에 훈련속도가 빠르다.
2. 이상치나 과대적합 가능성 - 하나하나는 조건인데 만약 샘플이 한개밖에 없다면 이상치이거나 과대적합의 가능성이 높다. - 10만개 중 1개의 데이터를 맞추기 위해 알고리즘을 생성했다면 (상황에 따라 필요한 경우도 있지만) 과대적합의 가능성이 높다. - 샘플이 적은데 비율 차이가 많이 나면 그냥 하면 안됨. 추출을 할 때 반드시 100:1로 추출해! 그럼 선택이 안되는 상황은 줄어든다. => 층화추출 max_depth 트리의 깊이가 줄어들면 조건이 세분화되지 않으니까 배치되는 샘플이 많아진다. 얕게 여러번 하자! mean_leaf_nodes / samples같은게 있으면 배치할 수 있는 샘플 수가 있다. 최소 10개는 주자~
from sklearn.preprocessing import MinMaxScaler
ord_features = ['ord_' + str(i) for i inrange(6)]
all_data[ord_features] = MinMaxScaler().fit_transform(all_data[ord_features])
#명목형 피처와 날짜 피처 합치기
from scipy import sparse
#원핫 인코딩 한 결과가 sparse matrix라서 희소 행렬을 합치는 API 사용
all_data_sprs = sparse.hstack([sparse.csr_matrix(all_data),
encoded_nom_matrix,
encoded_date_matrix], format='csr')
all_data_sprs
<500000x16306 sparse matrix of type '<class 'numpy.float64'>' with 9163718 stored elements in Compressed Sparse Row format>
- 현재 작업
이진 피처는 숫자 0과 1로 생성
명목 피처는 원핫인코딩
순서형 피처는 순서를 만들어서 번호를 부여하거나 일련번호 형태로 인코딩한 후 스케일링 작업 수행
데이터 분할
#훈련 데이터의 개수
num_train = len(train)
#훈련용
X_train = all_data_sprs[:num_train]
#답안 제출용
X_test = all_data_sprs[num_train:]
#훈련용
y = train['target']
#ROC AUC 점수를 확인하라고 했으므로#훈련 데이터를 다시 모델 훈련 데이터와 평가 훈련 데이터로 분할
X_train, X_valid, y_train, y_test = train_test_split(X_train, y,
test_size=0.3,
stratify=y,
random_state=42)
- 무작위로 선택된 수천명의 사람에게 복잡한 질문을 하고 대답을 모은다고 가정하면 이렇게 모은 답이 전문가의 답보다 나을 가능성이 높은데, 이를 대중의 지혜 혹은 집단지성이라고 한다. - 하나의 좋은 예측기를 이용하는 것보다 일반적인 여러 예측기를 이용해서 예측을 하면 더 좋은 결과를 만들 수 있다는 것을 앙상블 기법이라고 한다. - Decision Tree는 전체 데이터를 이용해서 하나의 트리를 생성해서 결과를 예측하지만, Random Forest는 훈련 세트로부터 무작위로 각기 다른 서브 세트를 이용해서 여러개의 트리 분류기를 만들고 예측할 때 가장 많은 선택을 받은 클래스나 평균 이용 - 머신러닝에서 가장 좋은 모델은 앙상블을 이용하는 모델
2. 투표기반 분류기
- 분류기 여러개를 가지고 훈련을 한 후 투표를 해서 다수결의 원칙으로 분류하는 방식 - law of large numbers(큰 수의 법칙)
동전을 던졌을 때 앞면이 나올 확률이 51%이고 뒷면이 나올 확률이 49%인 경우 일반적으로 1000번을 던진다면 앞면이 510번 뒷면이 490번 나올 것이다.
이런 경우 앞면이 다수가 될 가능성은 확률적으로 75% 정도 된다.
이를 10000번으로 확장하면 확률은 97%가 된다.
- 앙상블 기법을 이용할 때 동일한 알고리즘을 사용하는 분류기를 여러 개 만들어도 되고 서로 다른 알고리즘의 분류기를 여러개 만들어도 됨
동일한 알고리즘을 사용하는 분류기를 여러개 만들어서 사용할 때는 훈련 데이터가 달라야 한다.
2-1) 직접 투표 방식
- 분류를 할 때 실제 분류된 클래스를 가지고 선정
2-2) 간접 투표 방식
- 분류를 할 때 클래스 별 확률 가지고 선정 - 이 방식을 사용할 때는 모든 분류기가 predict_proba 함수 사용 가능 - 이 방식의 성능이 직접 투표 방식보다 높음
2-3) API
- sklearn.ensemble.VotingClassifier 클래스 - 매개변수로는 estimators 가 있는데 여기에 list로 이름과 분류기를 튜플의 형태로 묶어서 전달하고 voting 매개변수에 hard와 soft를 설정해서 직접 투표 방식인지 간접 투표 방식인지 설정
2-4) 투표 기반 분류기 (클래스를 가지고 선정)
# 직접 투표 방식
# 데이터 생성from sklearn.model_selection import train_test_split #훈련 데이터와 테스트 데이터 분할from sklearn.datasets import make_moons #샘플 데이터 생성
X, y = make_moons(n_samples=500, noise=0.30, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
#개별 분류기 from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
#모델 생성 및 훈련
log_clf = LogisticRegression(solver="lbfgs", random_state=42)
rnd_clf = RandomForestClassifier(n_estimators=100, random_state=42)
svm_clf = SVC(gamma="scale", random_state=42)
#직접 투표 기반 분류기from sklearn.ensemble import VotingClassifier
voting_clf = VotingClassifier(
estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)],
voting='hard')
#평가 지표 확인from sklearn.metrics import accuracy_score
for clf in (log_clf, rnd_clf, svm_clf, voting_clf):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__, accuracy_score(y_test, y_pred))
100%는 아닐테니까 오류가 발생하고, 다른 모델에서 공통으로 발생할 가능성은 크지 않으니까 여러개를 돌리면 효율이 좋아질 것이라는게 투표기반 모델의 가정.
2-5) 배깅과 페이스팅
- 동일한 알고리즘을 사용하고 훈련 세트에 서브 세트를 무작위로 구성해서 예측기를 각기 다르게 학습시키는 것 - bagging(bootstrap aggregating): 훈련 세트에서 중복을 허용하고 샘플링하는 방식 - pasting: 훈련 세트에서 중복을 허용하지 않고 샘플링하는 방식
하나의 샘플링 데이터는 여러개의 예측기에 사용 가능한데 bagging은 하나의 예측기에 동일한 샘플이 포함될 수 있다. pasting은 하나의 예측기 안에는 동일한 샘플이 포함될 수 없다.
모든 예측기가 훈련을 마치면 모든 예측을 모아서 새로운 샘플에 대한 예측을 생성하는데, 이때 수집 함수는 분류일 때 최빈값이고 회귀일 때 평균을 계산
개별 예측기는 원본 데이터 전체로 훈련한 것보다 편향이 심하지만 수집 함수를 통과하면 편향과 분산이 모두 감소
예측기들은 동시에 다른 CPU 코어나 컴퓨터에서 병렬로 학습 가능
- API: BaggingClassifier
기본적으로 bagging을 사용. bootstrap 매개변수를 False로 설정하면 페이스팅 수행
샘플이 많으면 페이스팅 사용, 샘플의 개수가 적으면 bagging 사용
n_jobs 매개변수: sklearn이 훈련과 예측에 사용할 CPU 코어 수를 설정 (-1을 설정하면 모든 코어 사용)
max_features, bootstrap_features라는 매개변수 이용해서 특성 샘플링 지원
최대 사용하는 피처의 개수와 피처의 중복 허용 여부를 설정
각 예측기는 무작위로 선택한 입력 특성의 일부분으로 훈련된다.
이미지와 같은 고차원의 데이터 세트에서 이용
훈련 특성과 샘플을 모두 샘플링하는 것을 Random Patches Method라고 한다.
샘플을 모두 사용하고 특성만 샘플링하는 것은 Random Subspaces Method라고 한다.
특성 샘플링을 하게 되면 더 다양한 예측기가 만들어지므로 편향을 늘리는 대신 분산을 낮춘다.
3. RandomForest
- 같은 알고리즘으로 여러 개의 분류기를 만들어서 보팅으로 최종 결정하는 배깅의 대표적인 알고리즘 - 알고리즘은 DecisionTree를 이용 - bootstrap 샘플을 생성해서 샘플 데이터 각각에 결정 트리를 적용한 뒤 학습 결과를 취합하는 방식으로 작동 - 각각의 DecisionTree들은 전체 특성 중 일부만 학습 - random_state 값에 따라 예측이 서로 다른 모델이 만들어지는 경우가 있는데 트리의 개수를 늘리면 변동이 적어진다. - 각 트리가 별개로 학습되므로 n_jobs를 이용해서 동시에 학습하도록 할 수 있다.
3-1) 장점
- 단일 트리의 단점 보완 - 매개변수 튜닝을 하지 않아도 잘 작동하고 데이터의 스케일을 맞출 필요가 없다. - 매우 큰 데이터 세트에도 잘 작동 - 여러 개의 CPU 코어를 사용하는 것이 가능
3-2) 단점
- 대량의 데이터에서 수행하면 시간은 많이 걸린다. - 차원이 매우 높고 (특성의 개수가 많음) 희소한 데이터(유사한 데이터가 별로 없는) 일수록 잘 작동하지 않는다.
이런 경우 선형 모델을 사용하는 것이 적합
희소한 데이터는 리프 노드에 있는 샘플의 개수가 적은 경우
3-3) 배깅과 랜덤 포레스트 비교
- 랜덤 포레스트는 Decision Tree의 배깅
배깅에서 부트 스트래핑을 사용하고 특성 샘플링을 이용하는 것이 랜덤 포레스트
부트 스트래핑은 하나의 훈련 세트에서 일부분의 데이터를 추출하는데 복원 추출 이용해서 수행
특성 샘플링은 비율을 설정해서 특성을 전부 이용하지 않고 일부분만을 이용해서 학습하는 방식
랜덤 포레스트에서는 특성의 비율을 기본적으로 제곱근만큼 사용
#배깅을 이용한 random forest 만들기
bag_clf = BaggingClassifier(
DecisionTreeClassifier(max_features="sqrt", max_leaf_nodes=16),
n_estimators=500, random_state=42)
bag_clf.fit(X_train, y_train)
y_pred = bag_clf.predict(X_test)
- RandomForest 알고리즘은 트리의 노드를 분할할 때 전체 특성 중에서 최선의 특성을 찾는 것이 아니라 무작위로 선택한 특성 후보 중에서 최적의 특성을 찾는 식으로 무작위성 주입
이러한 방식은 트리의 다양성을 높여서 편향을 손해보는 대신에 분산을 낮추는 방식으로 더 좋은 모델을 만들어간다.
3-4) 특성 중요도
- 트리 모델은 특성의 상대적 중요도를 측정하기 쉬움 - sklearn은 어떤 특성을 사용한 노드가 평균적으로 불순도를 얼마나 감소시켰는지 확인해서 특성의 중요도 판단
가중치의 평균이며 노드의 가중치는 연관된 훈련 샘플의 수와 같음
훈련 샘플의 수를 전체 합이 1이 되도록 결과값을 정규화한 후 feature_importances_에 저장
from sklearn.datasets import load_iris
iris = load_iris()
#data라는 속성에 피처 4가지 있음#target이라는 속성의 꽃의 종류에 해당하는 범주형 데이터 3가지#featre_names 속성에 피처 이름이 저장되어 있고 class_names에 클래스 이름 저장
rnd_clf = RandomForestClassifier(n_estimators=500, random_state=42)
rnd_clf.fit(iris["data"], iris["target"])
for name, score inzip(iris["feature_names"], rnd_clf.feature_importances_):
print(name, score)
Bagging이나 Pasting은 여러 개의 학습기를 가지고 예측한 후 그 결과를 합산해서 예측
앞의 모델을 보완해 나가면서 예측기를 학습
종류는 여러가지
4-1) Ada Boost
이전 모델이 과소 적합했던 훈련 샘플의 가중치를 더 높이는 것으로 이 방식을 이용하면 새로 만들어진 예측기는 학습하기 어려운 샘플에 점점 더 맞춰지게 된다.
먼저 알고리즘의 기반이 되는 첫번째 분류기를 훈련 세트로 훈련시키고 예측을 만들고 그 다음에 알고리즘이 잘못 분류한 훈련 샘플의 가중치를 상대적으로 높인다.두번째 분류기는 업데이트된 가중치를 사용해서 훈련 세트에서 다시 훈련하고 다시 예측을 만들고 그 다음에 가중치를 업데이트 하는 방식
투표 방식이 아닌 것임
- API: sklearn. AdaBoostClassifier
기반 알고리즘이 predict_proba 함수를 제공한다면 클래스 확률을 기반으로 분류가 가능
algorithm 매개변수에 SAMME.R 값 설정
확률을 이용하는 방식이 예측 값을 이용하는 방식보다 성능이 우수할 가능성이 높다.
# moons 데이터에 AdaBoost 적용
X, y = make_moons(n_samples=500, noise=0.30, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
from sklearn.ensemble import AdaBoostClassifier
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=1), n_estimators=200,
algorithm="SAMME.R", learning_rate=0.5, random_state=42)
ada_clf.fit(X_train, y_train)
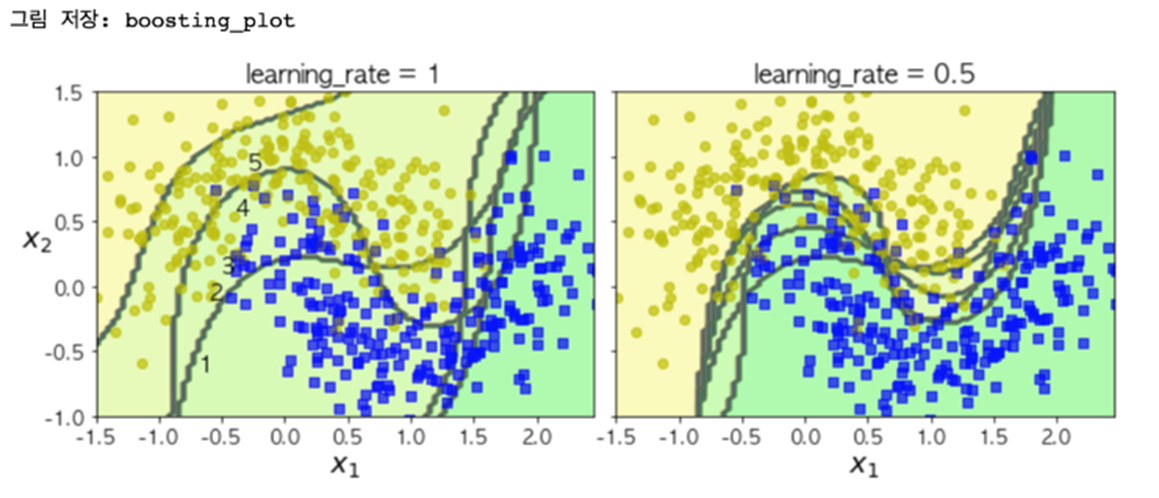
plot_decision_boundary(ada_clf, X, y)
learning_rate(학습률)는 훈련을 할 때 스텝의 크기로 이 값이 크면 최적화에 실패할 가능성이 높아지고, 낮으면 최적화에는 성공할 가능성이 높지만 훈련 속도가 느려지고 과대적합 가능성이 높아진다.
따라서 학습률은 그리드서치로 최적값을 찾을 필요가 있다.
4-2) Gradient Boosting
여러 개의 결정 트리를 묶어서 강력한 모델을 만드는 앙상블 기법
회귀와 분류 모두 가능
RandomForest도 여러 개의 결정 트리를 이용하는 것은 같지만, Gradient Boosting은 이전 트리의 오차를 보완하는 방식으로 순차적으로 트리 생성
무작위성이 없다. 이전에 오분류한 샘플에 가중치를 부여한다. 대신 강력한 사전 가지 치기를 사용한다.
보통 1~5 정도 깊이의 트리를 사용하기 때문에 메모리를 적게 사용하고 에측도 빠르다.
RandomForest 보다 매개변수 설정에 조금 더 민감하지만 잘 조정하면 더 높은 정확도를 제공한다.
AdaBoost 가중치 업데이트를 경사 하강법을 이용해서 조정한다.
예측 속도는 빠르지만 훈련 속도(수행 시간)는 느리고 하이퍼 파라미터 튜닝도 좀더 어렵다.
랜덤 포레스트는 각각 훈련하기 때문에 병렬이 된다. n_jobs여럿 지정 가능. 그런데 부스팅은 순차적으로 가야하기 때문에 병렬이 불가하다. GB의 장점은 메모리가 적고 예측도 빠르고 성능이 좋지만 훈련 시간이 문제임.
- API: sklean. GradientBoostingClassifier
from sklearn.ensemble import GradientBoostingClassifier
import time
# GBM 수행 시간 측정을 위함. 시작 시간 설정.
start_time = time.time()
gb_clf = GradientBoostingClassifier(random_state=0)
gb_clf.fit(X_train , y_train)
gb_pred = gb_clf.predict(X_test)
gb_accuracy = accuracy_score(y_test, gb_pred)
print('GBM 정확도: {0:.4f}'.format(gb_accuracy))
print("GBM 수행 시간: {0:.1f} 초 ".format(time.time() - start_time))
GBM 정확도: 0.8880 GBM 수행 시간: 0.2 초
- 하이퍼 파라미터
max_depth: 트리의 깊이
max_features: 사용하는 피처의 비율
n_estimators: 학습기의 개수로 기본은 100
learning_rate: 학습률. 기본은 0.1이며 0~1사이로 설정 가능
subsample: 샘플링 비율. 기본 값은 1인데 과대적합 가능성이 보이면 숫자를 낮추면 된다.기본은 모든 데이터로 학습
deck 열에는 결측치가 많다. embarked와 embark_town은 동일한 의미를 가진 컬럼
# 전처리
# load_dataset 함수를 사용하여 데이터프레임으로 변환
df = sns.load_dataset('titanic')
# IPython 디스플레이 설정 - 출력할 열의 개수 한도 늘리기
pd.set_option('display.max_columns', 15)
# NaN값이 많은 deck 열을 삭제, embarked와 내용이 겹치는 embark_town 열을 삭제
rdf = df.drop(['deck', 'embark_town'], axis=1)
# age 열에 나이 데이터가 없는 모든 행을 삭제 - age 열(891개 중 177개의 NaN 값)
rdf = rdf.dropna(subset=['age'], how='any', axis=0)
# embarked 열의 NaN값을 승선도시 중에서 최빈값으로 치환하기# 각 범주의 개수를 구한 후 가장 큰 값의 인덱스를 가져오기
most_freq = rdf['embarked'].value_counts(dropna=True).idxmax()
# 치환
rdf['embarked'].fillna(most_freq, inplace=True)
# 속성(변수) 선택
X=ndf[['pclass', 'age', 'sibsp', 'parch', 'female', 'male',
'town_C', 'town_Q', 'town_S']] #독립 변수 X# X=ndf.drop(['survived'], axis=1)
y=ndf['survived'] #종속 변수 Y#피처의 스케일 확인
X.describe() #숫자 컬럼의 기술 통계량 확인
숫자 컬럼의 값들의 범위가 차이가 많이 나면 scaling을 수행하는 것이 좋다.
# 스케일링
# 설명 변수 데이터를 정규화(normalization)from sklearn import preprocessing
X = preprocessing.StandardScaler().fit(X).transform(X)
# 훈련
# train data 와 test data로 구분(7:3 비율)from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=10)
- 분류에서는 잘못 분류된 데이터를 다음 학습기에서 다시 예측하는 형태로 구현 - 회귀에서는 첫번째 결정 트리 모델을 가지고 학습한 후 잔차를 구하여 다음 결정 트리 모델이 잔차를 타겟으로 해서 다시 학습을 수행하고 잔차를 구한 후 이 결과를 가지고 다음 결정 트리 모델이 훈련을 하는 방식으로 구현
예측값은 모든 결정 트리 모델의 예측을 더하면 됨
- GradientBoostingRegressor 제공
#샘플 데이터 생성
np.random.seed(42)
X = np.random.rand(100, 1) - 0.5
y = 3*X[:, 0]**2 + 0.05 * np.random.randn(100)
print(X[0])
print(y[0])
[-0.12545988] 0.05157289874841034
#첫번째 트리로 훈련from sklearn.tree import DecisionTreeRegressor
#의사 결정 나무를 이용한 회귀
tree_reg1 = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg1.fit(X, y)
print(y[0])
print(tree_reg1.predict(X[0].reshape(1, 1)))
0.05157289874841034 [0.12356613]
#첫번째 예측기에서 생긴 잔여 오차에 두번째 DecisionTreeRegresssor를 훈련
y2 = y - tree_reg1.predict(X)
#잔차를 타겟으로 훈련
tree_reg2 = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg2.fit(X, y2)
print(tree_reg2.predict(X[0].reshape(1, 1)))
#이제 세 개의 트리를 포함하는 앙상블 모델이 생겼습니다. #새로운 샘플에 대한 예측을 만들려면 모든 트리의 예측을 더하면 됩니다.
X_new = np.array([[0.8]])
y_pred = sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2, tree_reg3))
print(y_pred)
[0.75026781]
#이제 세 개의 트리를 포함하는 앙상블 모델이 생겼습니다. #새로운 샘플에 대한 예측을 만들려면 모든 트리의 예측을 더하면 됩니다.
X_new = np.array([[0.05]])
y_pred = sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2, tree_reg3))
print(y_pred)
Gradient Boosting에 기반하지만 느린 훈련속도와 과적합 규제에 대한 부분 보완
병렬 학습 가능
자체 내장된 교차 검증 수행
결측값도 자체 처리
5-1) 하이퍼 파라미터
- 일반 파라미터: 일반적으로 실행 시 스레드의 개수 silent 모드 (로그 출력x) 등의 선택을 위한 파라미터로 기본 값을 거의 변경하지 않음 - 부스터 파라미터: 트리 최적화, 규제 등의 파라미터 - 학습 태스크 파라미터: 학습 수행 시의 객체 함수나 평가를 위한 지표 등을 설정
#설치
pip install xgboost
5-2) 훈련과 검증에 사용하는 데이터
- API: DMatrix
data 매개변수에 피처, label 매개변수에 타겟 설정
- 위스콘신 유방암 데이터
X-ray 촬영한 사진을 수치화한 데이터
사진을 직접 이용하는게 아니라 사진에서 필요한 데이터를 추출해서 수치화해서 사용하는 경우가 많다.
이러한 라벨링 작업에 Open CV를 많이 활용한다.
타겟이 0이면 악성(malignant), 1이면 양성(benign)
# 데이터 가져오기import xgboost as xgb
from xgboost import plot_importance
from sklearn.datasets import load_breast_cancer
dataset = load_breast_cancer()
X_features= dataset.data
y_label = dataset.target
cancer_df = pd.DataFrame(data=X_features, columns=dataset.feature_names)
cancer_df['target']= y_label
cancer_df.head(3)
# 예측 확률이 0.5 보다 크면 1 , 그렇지 않으면 0 으로 예측값 결정하여 List 객체인 preds에 저장
preds = [ 1if x > 0.5else0for x in pred_probs ]
print('예측값 10개만 표시:',preds[:10])
예측값 10개만 표시: [1, 0, 1, 0, 1, 1, 1, 1, 1, 0]
#범주형 평가 지표 출력
정확도, 정밀도, 재현율, 정밀도와 재현율의 조화 평균(f1-score), roc_auc
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.metrics import precision_score, recall_score
from sklearn.metrics import f1_score, roc_auc_score
#오차 행렬 출력
confusion = confusion_matrix( y_test, preds)
print('오차행렬:\n', confusion)
#정확도: 전체 데이터에서 맞게 분류한 것의 비율
accuracy = accuracy_score(y_test , preds)
print('정확도:', accuracy)
#정밀도: 검색된 문서들 중 관련있는 문서들의 비율 (True로 판정한 것 중 실제 True인 것의 비율)
precision = precision_score(y_test , preds)
print('정밀도:', precision)
#재현율: 관련된 문서들 중 검색된 비율 (실제 True인 것 중 True로 판정한 것의 비율)
recall = recall_score(y_test , preds)
print('재현율:', recall)
#recall과 precision의 조화 평균 (f1_score)
f1 = f1_score(y_test,preds)
print('f1_score:', f1)
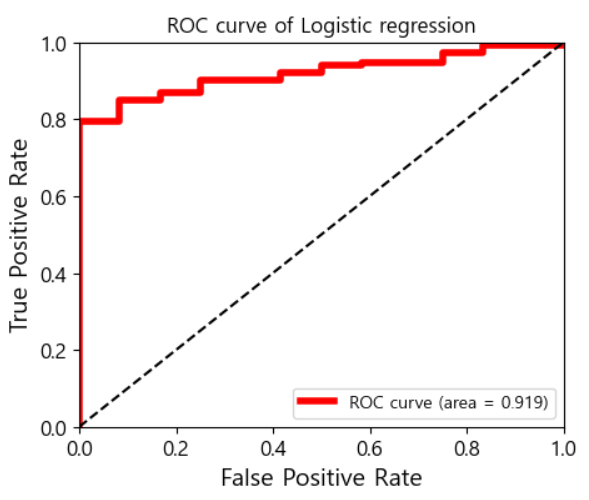
#roc_auc score - area under curve. 그래프 곡선 아래 면적#1에 가까울수록 좋은 성능
roc_auc = roc_auc_score(y_test, pred_probs)
print('roc_auc:', roc_auc)
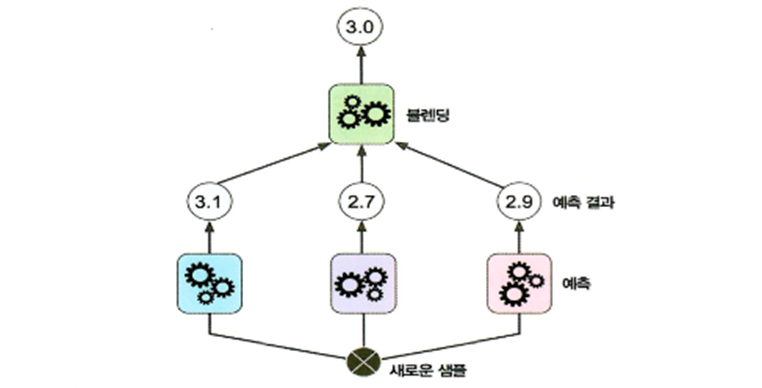
- 부스팅이나 랜덤 포레스트를 예측기의 예측을 취합해서 무언가 동작(투표, 확률, 평균 등)을 수행하는데 예측을 취합하는 모델을 훈련시키려고 하는 방식
개별 알고리즘의 예측 결과 데이터 세트를 최종적인 메타 데이터를 만들고 이 데이터를 가지고 별도의 ML 알고리즘으로 최종 학습을 수행하고 테스트 데이터를 기반으로 다시 최종 예측을 수행하는 방식
개별 알고리즘의 예측 결과를 가지고 훈련해서 최종 결과를 만들어내는 예측기 Blender 생성
블랜더는 홀드 아웃 세트를 이용해서 학습
스태킹에서는 두 종류의 모델이 필요한데 하나는 개별적인 기반 모델이고 다른 하나는 기반 모델의 예측 데이터를 학습 데이터로 만들어서 학습하는 최종 메타 모델
- API: sklearn 스태킹 지원 안함. 직접 구현하거나 오픈소스 시용
6-1) 위스콘신 유방암 데이터를 이용해서 스태킹 구현
- 개별 학습기: KNN, RandomForest, AdaBoost, DecisionTree - 최종 학습기: LogisticRegression
# 데이터 가져오기
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
cancer_data = load_breast_cancer()
X_data = cancer_data.data
y_label = cancer_data.target
X_train , X_test , y_train , y_test = train_test_split(X_data , y_label , test_size=0.2 , random_state=0)
# 예측기 생성
# 개별 ML 모델을 위한 Classifier 생성.
knn_clf = KNeighborsClassifier(n_neighbors=4)
rf_clf = RandomForestClassifier(n_estimators=100, random_state=0)
dt_clf = DecisionTreeClassifier()
ada_clf = AdaBoostClassifier(n_estimators=100)
# 최종 Stacking 모델을 위한 Classifier생성.
lr_final = LogisticRegression(C=10)
pred = np.array([knn_pred, rf_pred, dt_pred, ada_pred])
print(pred.shape)
# transpose를 이용해 행과 열의 위치 교환. 컬럼 레벨로 각 알고리즘의 예측 결과를 피처로 만듦.
pred = np.transpose(pred)
print(pred.shape)
(4, 114) (114, 4)
#최종 모델의 정확도 확인
lr_final.fit(pred, y_test)
final = lr_final.predict(pred)
print('최종 메타 모델의 예측 정확도: {0:.4f}'.format(accuracy_score(y_test , final)))